Накопление векторных элементов
B = accumarray(ind,data)data согласно группам, указанным в ind. Затем сумма вычисляется по каждой группе. Значения в ind определите и группу, к которой относятся данные, и индекс в выход массив B где сохранена каждая сумма группы.
Чтобы вернуть групповые суммы по порядку, задайте ind как вектор. Затем для группы с индексом i, accumarray возвращает его сумму в B(i). Для примера, если ind = [1 1 2 2]' и data = [1 2 3 4]', затем B = accumarray(ind,data) возвращает вектор-столбец B = [3 7]'.
Чтобы вернуть суммы группы в другую форму, задайте ind как матрица. Для m -by n матрицы indкаждая строка представляет назначение группы и n -мерный индекс в выходной B. Для примера, если ind содержит две строки формы [3 4], затем сумма соответствующих элементов в data хранится в элементе (3,4) B.
Элементы B индекс которого не отображается в ind заполнены 0 по умолчанию.
B = accumarray(ind,data,sz)B заполненный до размера sz. Задайте sz как вектор положительных целых чисел, которые совпадают или превышают длины размерности в ind. Дополнительные элементы на выходе заполнены 0. Задайте sz как [] чтобы позволить индексам в ind определить размер выхода.
Следующий рисунок иллюстрирует поведение accumarray на векторе данных о температуре, взятых за 12-месячный период. Чтобы найти максимальное значение температуры для каждого месяца, accumarray применяет max функцию для каждой группы значений в temperature которые имеют одинаковые индексы в month.
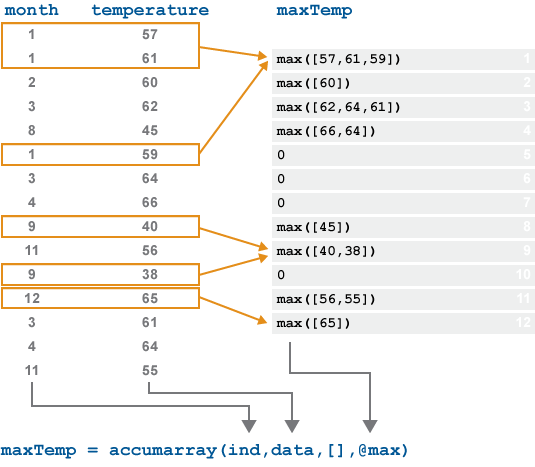
Нет значений в month указать на 5, 6, 7 или 10 положения выходного сигнала. Эти элементы 0 в выход по умолчанию.
Поведение accumarray аналогично функциям groupsummary и groupcounts для вычисления суммарной статистики по группам и подсчета количества элементов в группе, соответственно. Для получения дополнительной функциональности группировок в MATLAB®, см. Предварительная обработка данных.
Поведение accumarray также подобен тому, что у histcounts функция.
histcounts группирует непрерывные значения в 1-D область значений с помощью границ интервала. accumarray группирует данные с использованием n -мерных индексов.
histcounts можно вернуть только количества интервалов и размещение интервалов. accumarray может применить к данным любую функцию.
Можно имитировать поведение histcounts использование accumarray с data = 1.
The sparse функция также имеет поведение накопления, подобное поведению accumarray.
sparse группирует данные с помощью индексов 2-D, в то время как accumarray группирует данные с использованием n -мерных индексов.
Для элементов с идентичными индексами sparse применяет sum функция (для double значений) или any функция (для logical значения) и возвращает скалярный результат в выходной матрице. accumarray суммирует по умолчанию, но может применить к данным любую функцию.
