Наиболее частые значения в массиве
M = mode(A)A, которое является наиболее часто встречающимся значением в A. Когда несколько значений происходят одинаково часто, mode возвращает наименьшее из этих значений. Для комплексных входов наименьшее значение является первым значением в отсортированном списке.
Если A является вектором, тогда mode(A) возвращает наиболее частое значение A.
Если A является непустой матрицей, тогда mode(A) возвращает вектор-строку, содержащую режим каждого столбца A.
Если A - пустая матрица 0 на 0, mode(A) возвращает NaN.
Если A является многомерным массивом, затем mode(A) обрабатывает значения по первому измерению массива, размер которого не равен 1 как векторы и возвраты массив наиболее частых значений. Размер этой размерности становится 1 в то время как размеры всех других размерностей остаются неизменными.
A - Входной массивВходной массив, заданный как векторный, матричный или многомерный массив. A может быть числовым массивом, категориальным массивом, массивом datetime или массивом длительности.
NaN или NaT (Не Время) значения во входном массиве, A, игнорируются. Неопределенные значения в категориальных массивах аналогичны NaNs в числовых массивах.
dim - Размерность для работыРазмерность для работы, заданная как положительный целочисленный скаляр Если значение не задано, то по умолчанию это первое измерение массива, не равный 1.
Размерность dim указывает размерность, длина которого уменьшается до 1. The size(M,dim) является 1, в то время как размеры всех других размерностей остаются неизменными.
Рассмотрим двумерный входной массив, A.
Если dim = 1, затем mode(A,1) возвращает вектор-строку, содержащую наиболее частое значение в каждом столбце.
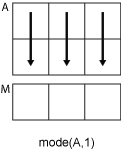
Если dim = 2, затем mode(A,2) возвращает вектор-столбец, содержащую наиболее частое значение в каждой строке.
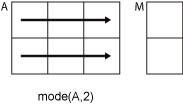
mode возвращает A если dim больше ndims(A).
Типы данных: double | single | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
vecdim - Вектор размерностейВектор размерностей, заданный как вектор положительных целых чисел. Каждый элемент представляет размерность входного массива. Длины выходов в заданных рабочих размерностях равны 1, в то время как остальные остаются прежними.
Рассмотрите массив входа 2 на 3 на 3, A. Затем mode(A,[1 2]) возвращает массив 1 на 1 на 3, элементы которого - способы каждой страницы A.
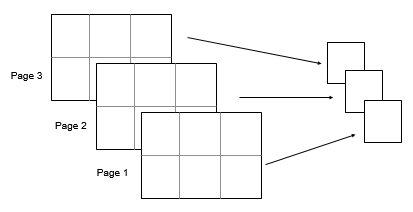
Типы данных: double | single | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
mode функция наиболее полезна с дискретными или грубо округлыми данными. Режим непрерывного распределения вероятностей задан как пик его функции плотности. Применение mode функция для выборки из этого распределения вряд ли даст хорошую оценку пика; было бы лучше вычислить гистограмму или оценку плотности и вычислить пик этой оценки. Кроме того, mode функция не подходит для нахождения peaks в распределениях, имеющих несколько режимов.
histcounts | histogram | mean | median | sort
