Чтение форматированных данных из текстового файла или строки
C = textscan(fileID,formatSpec)C. Текстовый файл обозначается идентификатором файла fileID. Использование fopen чтобы открыть файл и получить fileID значение. Когда вы закончите чтение из файла, закройте файл, позвонив fclose(fileID).
textscan пытается соответствовать данным в файле спецификатору преобразования в formatSpec. The textscan функция повторно применяет formatSpec на протяжении всего файла и останавливается, когда он не может совпадать formatSpec к данным.
C = textscan(fileID,formatSpec,N)formatSpec N раз, где N является положительным целым числом. Чтобы считать дополнительные данные из файла после N циклы, вызов textscan снова используя исходную fileID. Если вы возобновляете текстовый скан файла, вызывая textscan с тем же идентификатором файла (fileID), затем textscan автоматически возобновляет чтение в точке, где завершено последнее чтение.
C = textscan(chr,formatSpec)chr в C массива ячеек. При чтении текста из вектора символов повторяются вызовы в textscan перезапускать скан с самого начала каждый раз. Чтобы перезапустить скан из последней позиции, запросите position выход.
textscan пытается соответствовать данным в вектор символов chr в формат, заданный в formatSpec.
C = textscan(chr,formatSpec,N)formatSpec N раз, где N является положительным целым числом.
C = textscan(___,Name,Value)Name,Value парные аргументы, в дополнение к любому из входных параметров в предыдущих синтаксисах.
Считайте вектор символов, содержащий числа с плавающей запятой.
chr = '0.41 8.24 3.57 6.24 9.27'; C = textscan(chr,'%f');
Спецификатор '%f' в formatSpec говорит textscan для соответствия каждому полю в chr с двойной точностью числа с плавающей запятой.
Отображение содержимого массива ячеек C.
celldisp(C)
C{1} =
0.4100
8.2400
3.5700
6.2400
9.2700
Считайте тот же вектор символов и обрезайте каждое значение до одной десятичной цифры.
C = textscan(chr,'%3.1f %*1d');Спецификатор %3.1f указывает ширину поля 3 цифры и точность 1. The textscan функция считывает в общей сложности 3 цифры, включая десятичную точку и 1 цифру после десятичной точки. Спецификатор, %*1d, говорит textscan чтобы пропустить оставшуюся цифру.
Отображение содержимого массива ячеек C.
celldisp(C)
C{1} =
0.4000
8.2000
3.5000
6.2000
9.2000
Считайте вектор символов, который представляет набор шестнадцатеричных чисел. Текст, который представляет шестнадцатеричные числа, включает цифры 0- 9, буквы a- f или A- F, и опционально префиксы 0x или 0X.
Чтобы соответствовать полям в hexnums для шестнадцатеричных чисел используйте '%x' спецификатор. The textscan функция преобразует поля в беззнаковые 64-битные целые числа.
hexnums = '0xFF 0x100 0x3C5E A F 10'; C = textscan(hexnums,'%x')
C = 1x1 cell array
{6x1 uint64}
Отображение содержимого C как вектор-строка.
transpose(C{:})ans = 1x6 uint64 row vector
255 256 15454 10 15 16
Можно преобразовать поля в знаковые или беззнаковые целые числа, имеющие 8, 16, 32 или 64 бита. Преобразование полей в hexnums для знаковых 32-битных целых чисел используйте '%xs32' спецификатор.
C = textscan(hexnums,'%xs32');
transpose(C{:})ans = 1x6 int32 row vector
255 256 15454 10 15 16
Можно также задать ширину поля для интерпретации входов. В этом случае префикс отсчитывается по ширине поля. Для примера, если вы задаете ширину поля три, как в %3x, затем textscan разделяет текст на '0xAF 100' в три части текста, '0xA', 'F', и '100'. Три части текста рассматриваются как различные шестнадцатеричные числа.
C = textscan('0xAF 100','%3x'); transpose(C{:})
ans = 1x3 uint64 row vector
10 15 256
Считайте вектор символов, который представляет набор двоичных чисел. Текст, который представляет двоичные числа, включает цифры 0 и 1, и опционально префиксы 0b или 0B.
Чтобы соответствовать полям в binnums для двоичных чисел используйте '%b' спецификатор. The textscan функция преобразует поля в беззнаковые 64-битные целые числа.
binnums = '0b101010 0b11 0b100 1001 10'; C = textscan(binnums,'%b')
C = 1x1 cell array
{5x1 uint64}
Отображение содержимого C как вектор-строка.
transpose(C{:})ans = 1x5 uint64 row vector
42 3 4 9 2
Можно преобразовать поля в знаковые или беззнаковые целые числа, имеющие 8, 16, 32 или 64 бита. Преобразование полей в binnums для знаковых 32-битных целых чисел используйте '%bs32' спецификатор.
C = textscan(binnums,'%bs32');
transpose(C{:})ans = 1x5 int32 row vector
42 3 4 9 2
Можно также задать ширину поля для интерпретации входов. В этом случае префикс отсчитывается по ширине поля. Для примера, если вы задаете ширину поля три, как в %3b, затем textscan разделяет текст на '0b1010 100' в три части текста, '0b1', '010', и '100'. Он рассматривает три части текста как различные двоичные числа.
C = textscan('0b1010 100','%3b'); transpose(C{:})
ans = 1x3 uint64 row vector
1 2 4
Загрузите файл данных и считайте каждый столбец с соответствующим типом.
Загрузка файловой scan1.dat и предварительный просмотр его содержимого в текстовом редакторе. Снимок экрана показан ниже.
filename = 'scan1.dat';
Откройте файл и прочитайте каждый столбец с соответствующим спецификатором преобразования. textscan возвращает 1-by-9 C массива ячеек.
fileID = fopen(filename); C = textscan(fileID,'%s %s %f32 %d8 %u %f %f %s %f'); fclose(fileID); whos C
Name Size Bytes Class Attributes C 1x9 2105 cell
Просмотрите тип данных MATLAB ® каждой из камер в C.
C
C=1×9 cell array
Columns 1 through 5
{3x1 cell} {3x1 cell} {3x1 single} {3x1 int8} {3x1 uint32}
Columns 6 through 9
{3x1 double} {3x1 double} {3x1 cell} {3x1 double}
Исследуйте отдельные записи. Заметьте, что C{1} и C{2} являются массивами ячеек. C{5} относится к типу данных uint32, так что первые два элемента C{5} являются максимальными значениями для 32-битное беззнаковое целое число, или intmax('uint32').
celldisp(C)
C{1}{1} =
09/12/2005
C{1}{2} =
10/12/2005
C{1}{3} =
11/12/2005
C{2}{1} =
Level1
C{2}{2} =
Level2
C{2}{3} =
Level3
C{3} =
12.3400
23.5400
34.9000
C{4} =
45
60
12
C{5} =
4294967295
4294967295
200000
C{6} =
Inf
-Inf
10
C{7} =
NaN
0.0010
100.0000
C{8}{1} =
Yes
C{8}{2} =
No
C{8}{3} =
No
C{9} =
5.1000 + 3.0000i
2.2000 - 0.5000i
3.1000 + 0.1000i
Удалите буквенный текст 'Level' из каждого поля во втором столбце данных из предыдущего примера. Предварительный просмотр файла показан ниже.

Откройте файл и совпадите с буквенным текстом во входах formatSpec.
filename = 'scan1.dat'; fileID = fopen(filename); C = textscan(fileID,'%s Level%d %f32 %d8 %u %f %f %s %f'); fclose(fileID); C{2}
ans = 3x1 int32 column vector
1
2
3
Просмотрите тип данных MATLAB ® второй камеры в C. Вторая камера 1-by-9 массив ячеек, C, теперь имеет тип данных int32.
disp( class(C{2}) )int32
Прочтите первый столбец файла в предыдущем примере в массив ячеек, пропустив остальную часть линии.
filename = 'scan1.dat'; fileID = fopen(filename); dates = textscan(fileID,'%s %*[^\n]'); fclose(fileID); dates{1}
ans = 3x1 cell
{'09/12/2005'}
{'10/12/2005'}
{'11/12/2005'}
textscan возвращает даты массива ячеек.
Загрузите файл data.csv и предварительный просмотр его содержимого в текстовом редакторе. Снимок экрана показан ниже. Заметьте, что файл содержит данные, разделенные запятыми, а также содержит пустые значения.
![]()
Чтение файла, преобразование пустых камер в -Inf.
filename = 'data.csv'; fileID = fopen(filename); C = textscan(fileID,'%f %f %f %f %u8 %f',... 'Delimiter',',','EmptyValue',-Inf); fclose(fileID); column4 = C{4}, column5 = C{5}
column4 = 2×1
4
-Inf
column5 = 2x1 uint8 column vector
0
11
textscan возвращает 1-by-6 массив ячеек, C. The textscan функция преобразует пустое значение в C{4} на -Inf, где C{4} сопоставлен с форматом с плавающей точкой. Потому что MATLAB ® представляет беззнаковое целое число -Inf как 0, textscan преобразует пустое значение в C{5} на 0, и не -Inf.
Загрузите файл data2.csv и предварительный просмотр его содержимого в текстовом редакторе. Снимок экрана показан ниже. Заметьте, что файл содержит данные, которые могут быть интерпретированы как комментарии и другие записи, такие как 'NA' или 'na' которые могут указывать на пустые поля.
filename = 'data2.csv';![]()
Определите вход, который textscan следует рассматривать как комментарии или пустые значения и сканировать данные на C.
fileID = fopen(filename); C = textscan(fileID,'%s %n %n %n %n','Delimiter',',',... 'TreatAsEmpty',{'NA','na'},'CommentStyle','//'); fclose(fileID);
Отобразите выход.
celldisp(C)
C{1}{1} =
abc
C{1}{2} =
def
C{2} =
2
NaN
C{3} =
NaN
5
C{4} =
3
6
C{5} =
4
7
Загрузите файл data3.csv и предварительный просмотр его содержимого в текстовом редакторе. Снимок экрана показан ниже. Заметьте, что файл содержит повторные разделители.
filename = 'data3.csv';
Чтобы обработать повторные запятые как один разделитель, используйте MultipleDelimsAsOne Параметру и установите значение 1 (true).
fileID = fopen(filename); C = textscan(fileID,'%f %f %f %f','Delimiter',',',... 'MultipleDelimsAsOne',1); fclose(fileID); celldisp(C)
C{1} =
1
5
C{2} =
2
6
C{3} =
3
7
C{4} =
4
8
Загрузите файл данных grades.txt для этого примера и предварительный просмотр его содержимого в текстовом редакторе. Снимок экрана показан ниже. Заметьте, что файл содержит повторные разделители.
filename = 'grades.txt';
Чтение заголовков столбцов в формате '%s' четыре раза.
fileID = fopen(filename); formatSpec = '%s'; N = 4; C_text = textscan(fileID,formatSpec,N,'Delimiter','|');
Считайте числовые данные в файле.
C_data0 = textscan(fileID,'%d %f %f %f')C_data0=1×4 cell array
{4x1 int32} {4x1 double} {4x1 double} {4x1 double}
Значение по умолчанию для CollectOutput является 0 (false), так textscan возвращает каждый столбец числовых данных в отдельном массиве.
Установите индикатор положения файла в начале файла.
frewind(fileID);
Перечитайте файл и установите значение CollectOutput на 1 (true), чтобы собрать последовательные столбцы того же класса в один массив. Можно использовать repmat функция, чтобы указать, что %f спецификатор преобразования должен появиться три раза. Этот метод полезен, когда формат повторяется много раз.
C_text = textscan(fileID,'%s',N,'Delimiter','|'); C_data1 = textscan(fileID,['%d',repmat('%f',[1,3])],'CollectOutput',1)
C_data1=1×2 cell array
{4x1 int32} {4x3 double}
Тестовые счета, которые все являются двойными, собираются в один массив 4 на 3.
Закройте файл.
fclose(fileID);
Считайте первый и последний столбцы данных из текстового файла. Пропустите столбец текста и столбец целочисленных данных.
Загрузите файл names.txt и предварительный просмотр его содержимого в текстовом редакторе. Снимок экрана показан ниже. Заметьте, что файл содержит два столбца цитируемого текста, за которым следует столбец с целыми числами и, наконец, столбец с числами с плавающей точкой.
filename = 'names.txt';
Считайте первый и последний столбцы данных в файле. Используйте спецификатор преобразования, %q для чтения текста, заключенного двойными кавычками ("). %*q пропускает цитируемый текст, %*d пропускает целочисленное поле и %f читает число с плавающей запятой. Задайте разделитель запятыми, используя 'Delimiter' аргумент пары "имя-значение".
fileID = fopen(filename,'r'); C = textscan(fileID,'%q %*q %*d %f','Delimiter',','); fclose(fileID);
Отобразите выход. textscan возвращает массив ячеек C где удаляются двойные кавычки, заключающие текст.
celldisp(C)
C{1}{1} =
Smith, J.
C{1}{2} =
Bates, G.
C{1}{3} =
Curie, M.
C{1}{4} =
Murray, G.
C{1}{5} =
Brown, K.
C{2} =
71.1000
69.3000
64.1000
133.0000
64.9000
Загрузите файл german_dates.txt и предварительный просмотр его содержимого в текстовом редакторе. Снимок экрана показан ниже. Заметьте, что первый столбец значений содержит даты на немецком языке, а второй и третий столбцы являются числовыми значениями.
filename = 'german_dates.txt';
Откройте файл. Укажите схему кодирования символов, связанную с файлом, как последний вход в fopen.
fileID = fopen(filename,'r','n','ISO-8859-15');
Прочтите файл. Задайте формат дат в файле используя %{dd % MMMM yyyy}D спецификатор. Определение локали дат с помощью DateLocale аргумент пары "имя-значение".
C = textscan(fileID,'%{dd MMMM yyyy}D %f %f',... 'DateLocale','de_DE','Delimiter',','); fclose(fileID);
Просмотр содержимого первой камеры в С. Отображение дат на языке, используемом MATLAB, зависит от локали системы.
C{1}ans = 3x1 datetime
01 January 2014
01 February 2014
01 March 2014
Использование sprintf для преобразования выходных последовательностей nondefault в ваши данные.
Создайте текст, который включает в себя символ ленты формы, \f. Затем, чтобы прочитать текст с помощью textscan, вызов sprintf для явного преобразования канала формы.
lyric = sprintf('Blackbird\fsinging\fin\fthe\fdead\fof\fnight'); C = textscan(lyric,'%s','delimiter',sprintf('\f')); C{1}
ans = 7x1 cell
{'Blackbird'}
{'singing' }
{'in' }
{'the' }
{'dead' }
{'of' }
{'night' }
textscan возвращает массив ячеек, C.
Возобновите сканирование из положения, отличного от начала.
Если вы возобновите скан текста, textscan читает с начала каждый раз. Чтобы возобновить скан из любой другой позиции, используйте синтаксис аргумента с двумя выходами в вашем первоначальном вызове, чтобы textscan.
Для примера создайте вектор символов под названием lyric. Прочтите первое слово вектора символов, а затем возобновите скан.
lyric = 'Blackbird singing in the dead of night'; [firstword,pos] = textscan(lyric,'%9c',1); lastpart = textscan(lyric(pos+1:end),'%s');
fileID - Идентификатор файлаИдентификатор файла открытого текстового файла, заданный как число. Перед чтением файла с textscan, вы должны использовать fopen чтобы открыть файл и получить fileID.
Типы данных: double
formatSpec - Формат полей данныхФормат полей данных, заданный как вектор символов или строка одного или нескольких спецификаторов преобразования. Когда textscan считывает вход, он пытается соответствовать данным формату, указанному в formatSpec. Если textscan не соответствует полю данных, он останавливает чтение и возвращает все поля, считанные до отказа.
Количество спецификаторов преобразования определяет количество камер в выходном массиве, C.
Numeric Fields
В этой таблице перечислены доступные спецификаторы преобразования для числовых входов.
| Численный входной тип | Спецификатор преобразования | Выходной класс |
|---|---|---|
| Целое число, со знаком | %d | int32 |
%d8 | int8 | |
%d16 | int16 | |
%d32 | int32 | |
%d64 | int64 | |
| Целое число, без знака | %u | uint32 |
%u8 | uint8 | |
%u16 | uint16 | |
%u32 | uint32 | |
%u64 | uint64 | |
| Число с плавающей запятой | %f | double |
%f32 | single | |
%f64 | double | |
%n | double | |
| Шестнадцатеричное число, беззнаковое целое число | %x | uint64 |
%xu8 | uint8 | |
%xu16 | uint16 | |
%xu32 | uint32 | |
%xu64 | uint64 | |
| Шестнадцатеричное число, целое число со знаком | %xs8 | int8 |
%xs16 | int16 | |
%xs32 | int32 | |
%xs64 | int64 | |
| Двоичное число, беззнаковое целое число | %b | uint64 |
%bu8 | uint8 | |
%bu16 | uint16 | |
%bu32 | uint32 | |
%bu64 | uint64 | |
| Двоичное число, целое число со знаком | %bs8 | int8 |
%bs16 | int16 | |
%bs32 | int32 | |
%bs64 | int64 |
Nonnumeric Fields
В этой таблице перечислены доступные спецификаторы преобразования для входов, которые включают нечисловые символы.
| Нечисловой входной тип | Спецификатор преобразования | Подробнее |
|---|---|---|
| Символ | %c | Чтение любого отдельного символа, включая разделитель. |
| Текстовый массив | %s | Считайте как массив ячеек из векторов символов. |
%q | Считайте как массив ячеек из векторов символов. Если текст начинается с двойной кавычки ( Пример: | |
| Даты и время | %D | Читайте так же, как |
% { | Читайте так же, как Для получения дополнительной информации о форматах отображения datetime смотрите Пример: | |
| Длительность | %T |
Читайте так же, как |
% { | Читайте так же, как Для получения дополнительной информации о форматах отображения длительности смотрите Пример: | |
| Категория | %C | Читайте так же, как |
| Соответствие шаблона | %[...] | Считайте как массив ячеек из векторов символов, символы в скобках до первого несоответствующего символа. Включение Пример: |
%[^...] | Исключить символы в скобках, считывая до первого совпадающего символа. Чтобы исключить Пример: |
Optional Operators
Спецификаторы преобразования в formatSpec могут включать необязательные операторы, которые появляются в следующем порядке (включает пространства для ясности):
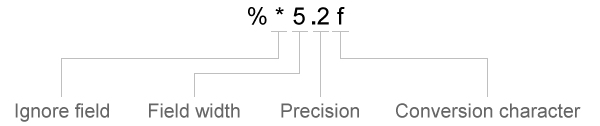
Опциональные операторы включают:
Поля и символы, которые нужно игнорировать
textscan считывает все символы в файле последовательно, если только вы не говорите ему игнорировать конкретное поле или фрагмент поля.
Вставьте символ звездочки (*) после символа процента (%), чтобы пропустить поле или фрагмент символьного поля.
Оператор | Принятые меры |
|---|---|
% * | Пропустите поле. Пример: |
'% * | Пропустите до Пример: |
'% * | Пропустите |
Ширина поля
textscan считывает количество символов или цифр, заданное шириной или точностью поля, или вплоть до первого разделителя, в зависимости от того, что наступит раньше. Десятичная точка, знак (+ или -), экспонентный символ и цифры в числовом выражении считаются символами и цифрами в пределах ширины поля. Для комплексных чисел ширина поля относится к отдельным ширинам вещественной части и мнимой части. Для мнимой части ширина поля включает + или −, но не i или j. Задайте ширину поля путем вставки числа после процентного символа (%) в спецификатор преобразования.
Пример: %5f читает '123.456' как 123.4.
Пример: %5c читает 'abcdefg' как 'abcde'.
Когда оператор ширины поля используется с одинарными символами (%c), textscan также считывает символы разделителя, пробел и конца строки.
Пример: %7c считывает 7 символов, включая пробел, так 'Day and night' читается следующим 'Day and'.
Точность
Для чисел с плавающей запятой (%n, %f, %f32, %f64), можно задать количество считываемых десятичных цифр.
Пример: %7.2f читает '123.456' как 123.45.
Буквенный текст, который нужно игнорировать
textscan игнорирует текст, добавленный к formatSpec спецификатор преобразования.
Пример: Level%u8 читает 'Level1' как 1.
Пример: %u8Step читает '2Step' как 2.
Типы данных: char | string
N - Количество раз применять formatSpecInf (по умолчанию) | положительное целое числоКоличество раз применять formatSpec, заданный как положительное целое число.
Типы данных: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
chr - Входной текстВведите текст для чтения.
Типы данных: char | string
Задайте необязательные разделенные разделенными запятой парами Name,Value аргументы. Name - имя аргумента и Value - соответствующее значение. Name должны находиться внутри кавычек. Можно задать несколько аргументов в виде пар имен и значений в любом порядке Name1,Value1,...,NameN,ValueN.
C = textscan(fileID,formatSpec,'HeaderLines',3,'Delimiter',',') пропускает первые три линии данных, а затем читает оставшиеся данные, обрабатывая запятые как разделитель.Имена не зависят от регистра.
textscan преобразует числовые поля в указанный выходной тип в соответствии с правилами MATLAB, касающимися переполнения, усечения и использования NaN, Inf, и -Inf. Для примера MATLAB представляет целое число NaN как нуль. Если textscan находит пустое поле, сопоставленное со спецификатором целочисленного формата (например %d или %u), оно возвращает пустое значение как нуль, а не NaN.
При сопоставлении данных со спецификатором преобразования текста textscan читается до тех пор, пока не найдет разделитель или символ в конце строки. При сопоставлении данных со спецификатором числового преобразования textscan читается до тех пор, пока не найдет нечисловой символ. Когда textscan не может больше соответствовать данным к конкретному спецификатору преобразования, он пытается соответствовать данным к следующему спецификатору преобразования в formatSpec. Знак (+ или -), символы экспоненты и десятичные точки считаются числовыми символами.
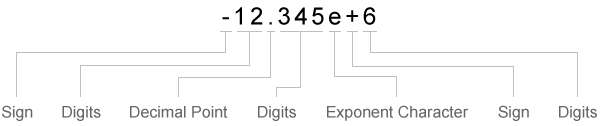
| Знак | Цифры | Десятичная точка | Цифры | Экспонентный символ | Знак | Цифры |
|---|---|---|---|---|---|---|
| Считайте один символ знака, если он существует. | Считайте одну или несколько цифр. | Считайте одну десятичную точку, если она существует. | Если существует десятичная точка, прочитайте одну или несколько цифр, которые немедленно следуют за ней. | Считайте один символ экспоненты, если он существует. | Если существует символ экспоненты, прочтите один символ знака. | Если существует символ экспоненты, прочитайте одну или несколько цифр, которые следуют за ним. |
textscan импортирует любое комплексное число в целом в комплексное числовое поле, преобразуя действительную и мнимую части в заданный числовой тип (например %d или %f). Допустимые формы для комплексного числа:
± <reservedrangesplaceholder0>± <reservedrangesplaceholder0> | Пример: |
± <reservedrangesplaceholder0> | Пример: |
Не включать встроенное пустое пространство в комплексное число. textscan интерпретирует встроенное пустое пространство как разделитель полей.
