Основанный на плотности алгоритм для кластеризации данных
clusterDBSCAN кластеризует точки данных, принадлежащие P -мерному пространству функций, используя основанную на плотности пространственную кластеризацию приложений с алгоритмом noise (DBSCAN). Алгоритм кластеризации назначает точки, которые близки друг к другу в пространстве функций, одному кластеру. Для примера радиолокационная система может вернуть несколько обнаружений расширенной цели, которые тесно разнесены по области значений, углу и Доплеру. clusterDBSCAN присваивает эти обнаружения одному обнаружению.
Алгоритм DBSCAN принимает, что кластеры являются плотными областями в пространстве данных, разделенными областями с меньшей плотностью и что все плотные области имеют сходные плотности.
Чтобы измерить плотность в точке, алгоритм отсчитывает количество точек данных в окрестности точки. Окрестность является P -мерным эллипсом (гиперэллипсом) в пространстве функций. Радиусы эллипса заданы P -вектором .rможет быть скаляром, в этом случае гиперэллипс становится гиперсферой. Расстояния между точками в пространстве функций вычисляются с помощью метрики Евклидова расстояния. Микрорайон получил название, а по-соседству. Значение И определяется Epsilon свойство. Epsilon может быть либо скаляром, либо P -вектором:
Вектор используется, когда различные размерности в пространстве функций имеют различные модули.
Скаляр применяет одно и то же значение ко всем размерностям.
Кластеризация начинается с нахождения всех основных точек. Если точка имеет достаточное число точек в своей, то точка называется центральной точкой. Минимальное число точек, необходимое для того, чтобы точка стала центральной точкой, задается MinNumPoints свойство.
Оставшимися точками в и-окрестности центральной точки могут быть сами основные точки. Если нет, то это пограничные точки. Все точки в окрестности и окрестности называются непосредственно плотными, достижимыми от точки ядра.
Если ε-neighborhood основной точки содержит другие основные точки, точки в ε-neighborhoods всех основных точек сливаются вместе, чтобы сформировать объединение ε-neighborhoods. Этот процесс продолжается до тех пор, пока больше не будут добавлены основные точки.
Все точки в объединении и окрестностях являются доступными для достижения плотности от первой точки ядра. Фактически, все точки в объединении являются доступными для плотности из всех основных точек в объединении.
Все точки в объединении и окрестностях также называются плотными соединениями, хотя пограничные точки необязательно доступны друг от друга. Кластер является максимальным набором точек, связанных по плотности, и может иметь произвольную форму.
Точки, которые не являются основными или пограничными точками, являются шумовыми точками. Они не относятся ни к одному кластеру.
The clusterDBSCAN объект может оценивать и, используя k - ближайший соседний поиск, или можно задать значения. Чтобы позволить объекту оценить ε, установите EpsilonSource свойство к 'Auto'.
The clusterDBSCAN объект может изменить неоднозначность данных, содержащих неоднозначности. Область значений и Доплер являются примерами возможно неоднозначных данных. Задайте EnableDisambiguation свойство к true для определения неоднозначности данных.
Для обнаружения кластеров:
Создайте clusterDBSCAN Объекту и установите его свойства.
Вызывайте объект с аргументами, как будто это функция.
Дополнительные сведения о работе системных объектов см. в разделе «Что такое системные объекты?».
clusterer = clusterDBSCANclusterDBSCAN объект, clusterer, объект со значениями свойств по умолчанию.
clusterer = clusterDBSCAN(Name,Value)clusterDBSCAN объект, clusterer, с каждым заданным свойством Name установить на заданную Value. Можно задать дополнительные аргументы пары "имя-значение" в любом порядке как (Name1, Value1..., NameN, ValueN). Любые неопределенные свойства берут значения по умолчанию. Для примера,
clusterer = clusterDBSCAN('MinNumPoints',3,'Epsilon',2, ... 'EnableDisambiguation',true,'AmbiguousDimension',[1 2]);
EnableDisambiguation значение свойства установлено равным true, а значение AmbiguousDimension установлено на [1,2].[ также возвращает альтернативный набор идентификаторов кластеров, idx,clusterids] = clusterer(X)clusterids, для использования в phased.RangeEstimator и phased.DopplerEstimator объекты. clusterids присваивает уникальный идентификатор каждой точке шума.
[___] = clusterer( автоматически оценивает эпсилон из матрицы входных данных, X,update)X, когда update установлено в true. Оценка использует поиск k -NN, чтобы создать набор поисковых кривых. Для получения дополнительной информации см. «Оценка Эпсилона». Оценка является средним значением L последних значений Эпсилона, где L задано в EpsilonHistoryLength
Чтобы включить этот синтаксис, установите EpsilonSource свойство к 'Auto', опционально установите MaxNumPoints свойство, а также опционально установите EpsilonHistoryLength свойство.
Чтобы использовать функцию объекта, задайте Системную object™ в качестве первого входного параметра. Например, чтобы освободить системные ресурсы системного объекта с именем obj, используйте следующий синтаксис:
release(obj)
Создайте обнаружения расширенных объектов с измерениями в области значений и Доплер. Предположим, что максимальная однозначная область значений составляет 20 м, а однозначный допплеровский диапазон простирается от Гц к Гц. Данные для этого примера содержатся в dataClusterDBSCAN.mat файл. Первый столбец матрицы данных представляет область значений, а второй - Doppler.
Входные данные содержат следующие расширенные цели и ложные предупреждения:
однозначная цель, расположенная на
неоднозначная цель в Доплере, расположенная в
неоднозначная цель в области значений, расположенном в
неоднозначная цель в области значений и Доплер, расположенный в
5 ложных предупреждений
Создайте clusterDBSCAN объект и укажите, что значения не выполняются путем установки EnableDisambiguation на false. Решите для индексов кластера.
load('dataClusterDBSCAN.mat'); cluster1 = clusterDBSCAN('MinNumPoints',3,'Epsilon',2, ... 'EnableDisambiguation',false); idx = cluster1(x);
Используйте clusterDBSCAN plot объект для отображения кластеров.
plot(cluster1,x,idx)

График указывает, что существует восемь явных кластеров и шесть шумовых точек. 'Dimension 1' метка соответствует области значений, и 'Dimension 2' метка соответствует Доплеру.
Далее создайте другую clusterDBSCAN объект и задать EnableDisambiguation на true чтобы указать, что кластеризация выполняется в диапазоне и контурах неоднозначности Доплера.
cluster2 = clusterDBSCAN('MinNumPoints',3,'Epsilon',2, ... 'EnableDisambiguation',true,'AmbiguousDimension',[1 2]);
Выполните кластеризацию с использованием пределов неоднозначности, а затем постройте график результатов кластеризации. Результаты кластеризации DBSCAN правильно показывают четыре кластера и пять шумовых точек. Для примера точки на области значений, близкие к нулю, кластеризованы с точками около 20 м, потому что максимальная однозначная область значений составляет 20 м.
amblims = [0 maxRange; minDoppler maxDoppler]; idx = cluster2(x,amblims); plot(cluster2,x,idx)

Кластеризуйте двумерные Декартовы данные о положении с помощью clusterDBSCAN. Чтобы проиллюстрировать, как выбор эпсилона влияет на кластеризацию, сравните результаты кластеризации с Epsilon установите значение 1 и Epsilon установите равным 3.
Создайте случайные данные о положении цели в xy Декартовых координатах.
x = [rand(20,2)+12; rand(20,2)+10; rand(20,2)+15];
plot(x(:,1),x(:,2),'.')
Создайте clusterDBSCAN объект со Epsilon значение свойства установлено равным 1, и MinNumPoints для набора свойств значение 3.
clusterer = clusterDBSCAN('Epsilon',1,'MinNumPoints',3);
Кластеризуйте данные при Epsilon равен 1.
idxEpsilon1 = clusterer(x);
Кластеризуйте данные снова, но с Epsilon установите равным 3. Можно изменить значение Epsilon потому что это настраиваемое свойство.
clusterer.Epsilon = 3; idxEpsilon2 = clusterer(x);
Постройте график результатов кластеризации один за другим. Сделайте это, передав в указатели plot осей и титулы способ. График показывает, что для Epsilon установите значение 1, появится три кластера. Когда Epsilon 3, два нижних кластера объединяются в один.
hAx1 = subplot(1,2,1); plot(clusterer,x,idxEpsilon1, ... 'Parent',hAx1,'Title','Epsilon = 1') hAx2 = subplot(1,2,2); plot(clusterer,x,idxEpsilon2, ... 'Parent',hAx2,'Title','Epsilon = 3')

Этот раздел иллюстрирует основные принципы формирования кластеров. Рисунок показывает точки в двумерном пространстве функций. Кластеры компактны и хорошо разделены. Появляется несколько шумовых точек.
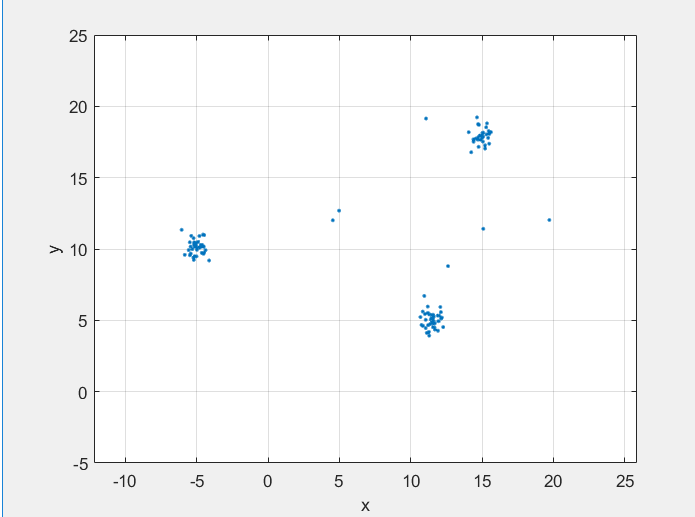
Кластеры начинаются с центральных точек. Первым шагом в алгоритме является идентификация всех центральных точек.
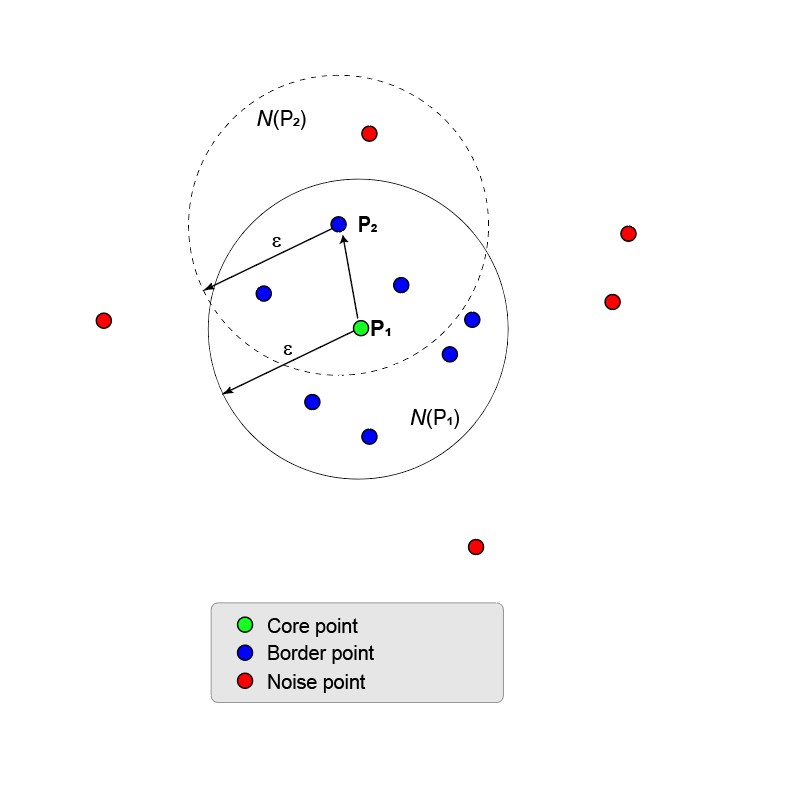
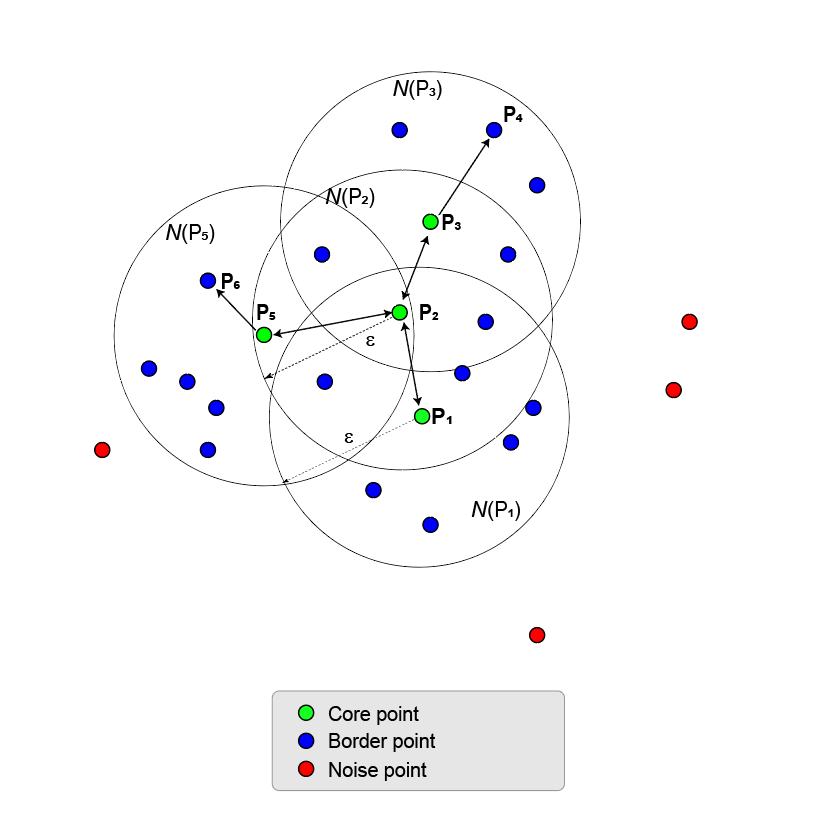
Рисунок здесь показывает P точки 1 и ее, по-соседству N и (P 1). Окрестность,, имеет восемь точек (включая саму себя) в радиусе Использование MinNumPoints свойство, устанавливающее порог равным 8, означает, что P 1 является базовой точкой. Синие точки, которые находятся внутри N, называются пограничными точками. Эти пограничные точки являются непосредственно доступными для достижения плотности от основной точки P 1.
Никакие другие точки на рисунке не имеют достаточного количества соседних точек в их и близости, чтобы стать центральной точкой. P 2 не является основной точкой, потому что она имеет только пять точек в пределах своего района. P 2 непосредственно достигает плотности от P 1. Противоположное значение не верно, потому что P 2 не является основной точкой. Односторонняя стрела, соединяющая две точки, показывает эту асимметрию.
Точки, которые падают снаружи N, (P 1) являются шумовыми точками (красными) и не принадлежат кластеру.
Поскольку никакие другие точки не являются основными точками, основная точка и пограничные точки являются максимальным набором точек, связанных с плотностью, и, следовательно, образуют кластер.
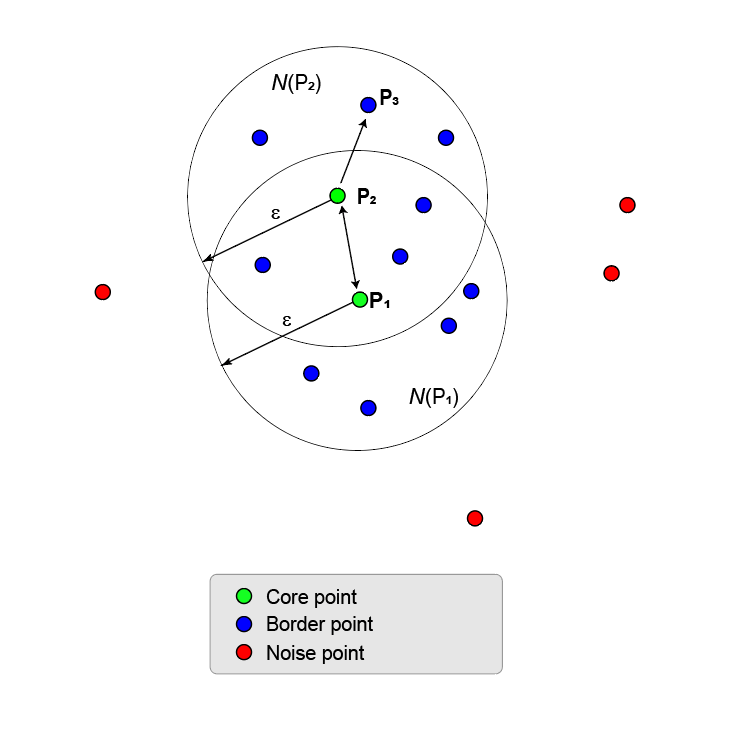
Следующий рисунок показывает большую совокупность точек, содержащих две основные точки, P 1 и P 2. P 2 является пограничной точкой P 1, но P 2 также имеет достаточно точек в своем собственном районе, чтобы стать центральной точкой. Поскольку они являются обеими основными точками, P 1 является непосредственно плотностью, достижимой из P 2, и P 1 непосредственно достижимой плотностью из P 2. Двухсторонняя стрела, соединяющая их, показывает эту симметрию.
P 3 непосредственно достигает плотности от P 2, но не от P 1 (как показано односторонней стрелкой). Однако P 3 называется просто плотностью, достижимой из P 1.
Поскольку никакие другие точки не являются основными точками, две основные точки и их пограничные точки образуют максимальный набор точек, связанных с плотностью, и образуют один кластер.
Этот процесс роста кластера может быть расширен от базовой точки до основной точки, пока не будет больше основных точек для добав. Основные точки и пограничные пункты относятся к одной и той же кластере. В целом, точка Pn является плотностью, достижимой от точки P 1, когда существует цепочка центральных точек, P 1, P 2, P 3,..., Pn-1 таким образом, что каждая центральная точка Pi + 1 непосредственно является плотностью, достижимой от Pi, и Pn непосредственно плотность достигается от Pn -1.
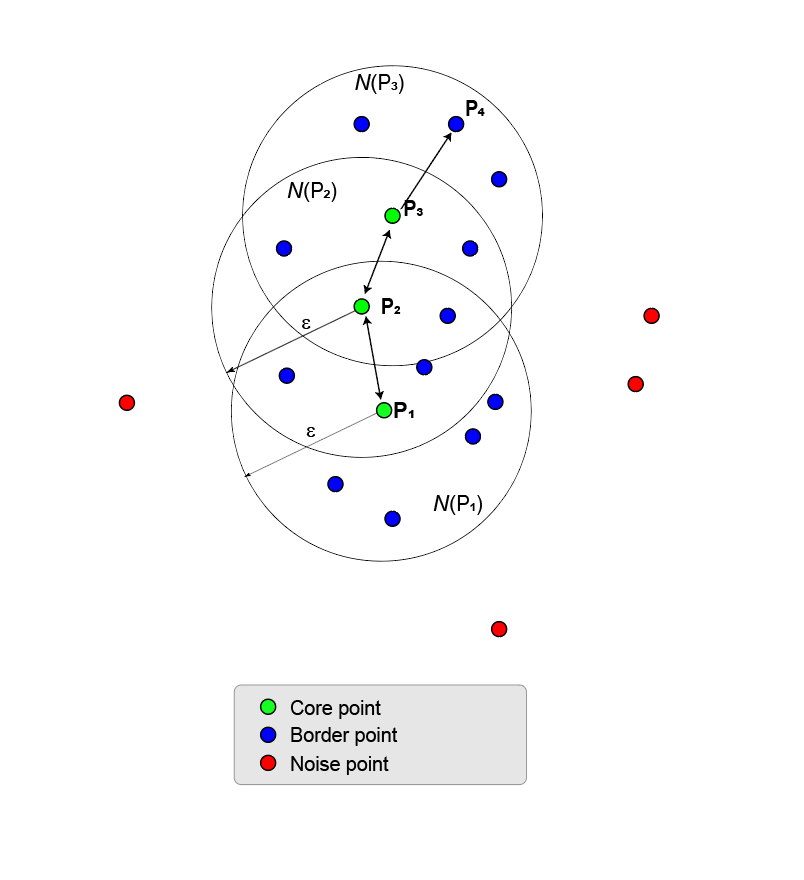
Следующий рисунок иллюстрирует некоторые свойства связности плотности.
Кластер может иметь несколько цепей ветвления, например (P 1, P 2, P 3, P 4) и (P 1, P 2, P 5, P 6).
Две точки, P 6 и P 4, связаны плотностью, когда существует третья точка P 2, так что P 6 и P 4 являются плотностями, достижимыми от P 2.
Две точки, соединенные по плотности, не обязательно являются достижимыми по плотности друг от друга.
Максимальный набор связанных точек плотности задает кластер. Не имеет значения, какая точка ядра является отправной точкой ядра.
Все точки в кластере являются доступными для плотности из всех центральных точек.
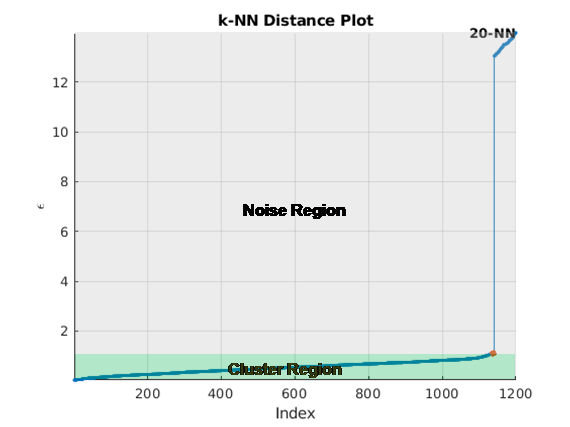
Кластеризация DBSCAN требует значения для параметра neighborhood size The clusterDBSCAN объект и clusterDBSCAN.estimateEpsilon функция использует k - ближайший соседний поиск, чтобы оценить скалярный эпсилон. Предположим, что D - расстояние между любой точкой P и ее kth ближайшего соседа. Задайте Dk (P) -светность как окрестность, окружающую P, которая содержит ее k-ближайшие соседи. В k (Dk) -светности P + 1 пункт, включая саму точку P. Контур алгоритма оценки следующий:
Для каждой точки найдите все точки в ее Dk (P) -неисходимости
Накопьте расстояния во всех Dk (P) -светах для всех точек в один вектор.
Отсортируйте вектор путем увеличения расстояния.
Постройте график отсортированного k -dist, который является отсортированным расстоянием от числа точек.
Найдите колено кривой. Значение расстояния в этой точке является оценкой эпсилона.
Рисунок здесь показывает расстояние, нанесенное на график на индекс точки для k = 20. Колено происходит приблизительно в 1,5. Любые точки ниже этого порога относятся к кластеру. Любые точки выше этого значения являются шумом.
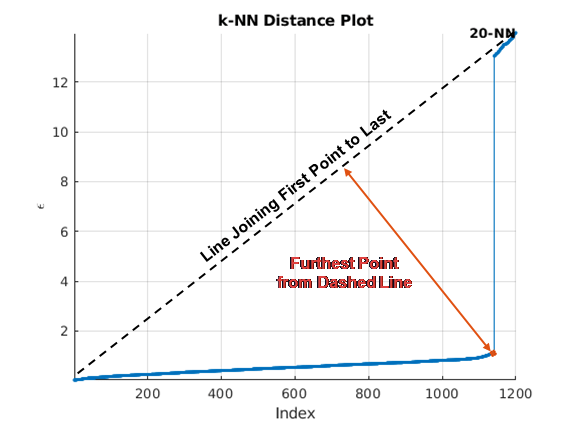
Существует несколько методов найти колено кривой. clusterDBSCAN и clusterDBSCAN.estimateEpsilon сначала задайте линию, соединяющую первую и последнюю точки кривой. Ордината точки на отсортированном k -dist графику, наиболее удалённая от линии и перпендикулярная линии, задает эпсилон.
Когда вы задаете область значений k значений, алгоритм рассчитывает средние значения эпсилона для всех кривых. Этот рисунок показывает, что эпсилон довольно нечувствителен к k для k в диапазоне от 14 до 19.
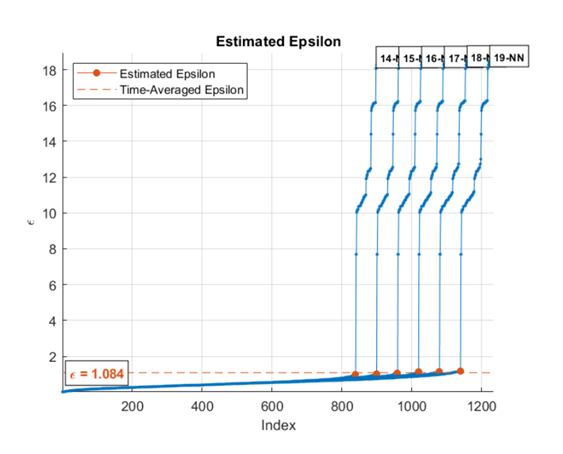
Чтобы создать один k -NN графиков расстояния, установите MinNumPoints свойство, равное MaxNumPoints свойство.
[1] Ester M., Kriegel H.-P., Sander J. и Xu X. «Основанный на плотности алгоритм обнаружения кластеров в больших пространственных базах данных с шумом». Proc. 2nd Int. Conf. on Knowledge Discovery and Data Mining, Portland, OR, AAAI Press, 1996, pp. 226-231.
[2] Эрих Шуберт, Йорг Сандер, Мартин Эстер, Ханс-Петер Кригель и Сяовэй Сюй. 2017. DBSCAN Revisited, Revisited: Why and How You Still (Still) Use DBSCAN (неопр.) (недоступная ссылка). ACM Trans. Database Syst. 42, 3, Article 19 (July 2017), 21 стр.
[3] Dominik Kellner, Jens Klappstein and Klaus Dietmayer, «Grid-Based DBSCAN for Clustering Extended Объектов in Radar Данных», 2012 IEEE Intelligent Транспортных средств Symposium.
[4] Thomas Wagner, Reinhard Feger, and Andreas Stelzer, «A Fast Grid-Based Clustering Algorithm for Range/Doppler/DoA Measurements», Труды 13-й Европейской радиолокационной конференции.
[5] Mihael Ankerst, Markus M. Breunig, Hans-Peter Kriegel, Jörg Sander, «OPTICS: Order Points To Identify the Clustering Structure», Proc. ACM SIGMOOD D 99 InT T. Conf. on Management of Data, Philadelphia PA, 1999.
