Приложение Reinforcement Learning Designer поддерживает агентов следующих типов.
Чтобы обучить агента, используя Reinforcement Learning Designer, необходимо сначала создать или импортировать окружение. Для получения дополнительной информации смотрите Создать окружения MATLAB для Reinforcement Learning Designer и Создать окружения Simulink для Reinforcement Learning Designer.
Чтобы создать агента, на вкладке Reinforcement Learning, в разделе Agent, нажмите New.
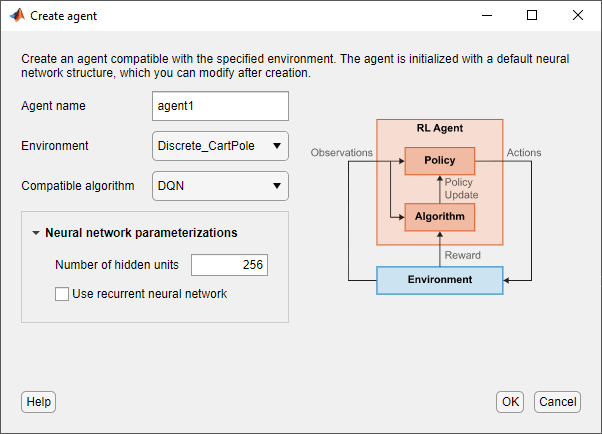
В диалоговом окне Create agent укажите следующую информацию.
Agent name - Укажите имя агента.
Environment - выберите окружение, которую вы ранее создали или импортировали.
Compatible algorithm - Выберите алгоритм настройки агента. Этот список содержит только алгоритмы, совместимые со окружением, которую вы выбираете.
Приложение Reinforcement Learning Designer создает агентов с представлениями актёра глубокой нейронной сети по умолчанию и критика. Можно задать следующие опции для сетей по умолчанию.
Number of hidden units - Задайте количество модулей в каждом полностью подключенном или LSTM слое сетей актёра и критика.
Use recurrent neural network - Выберите эту опцию, чтобы создать представления актёра и критика с рекуррентными нейронными сетями, которые содержат слой LSTM.
Чтобы создать агента, нажмите OK.
Приложение добавляет нового агента по умолчанию в область Agents и открывает документ для редактирования опций агента.
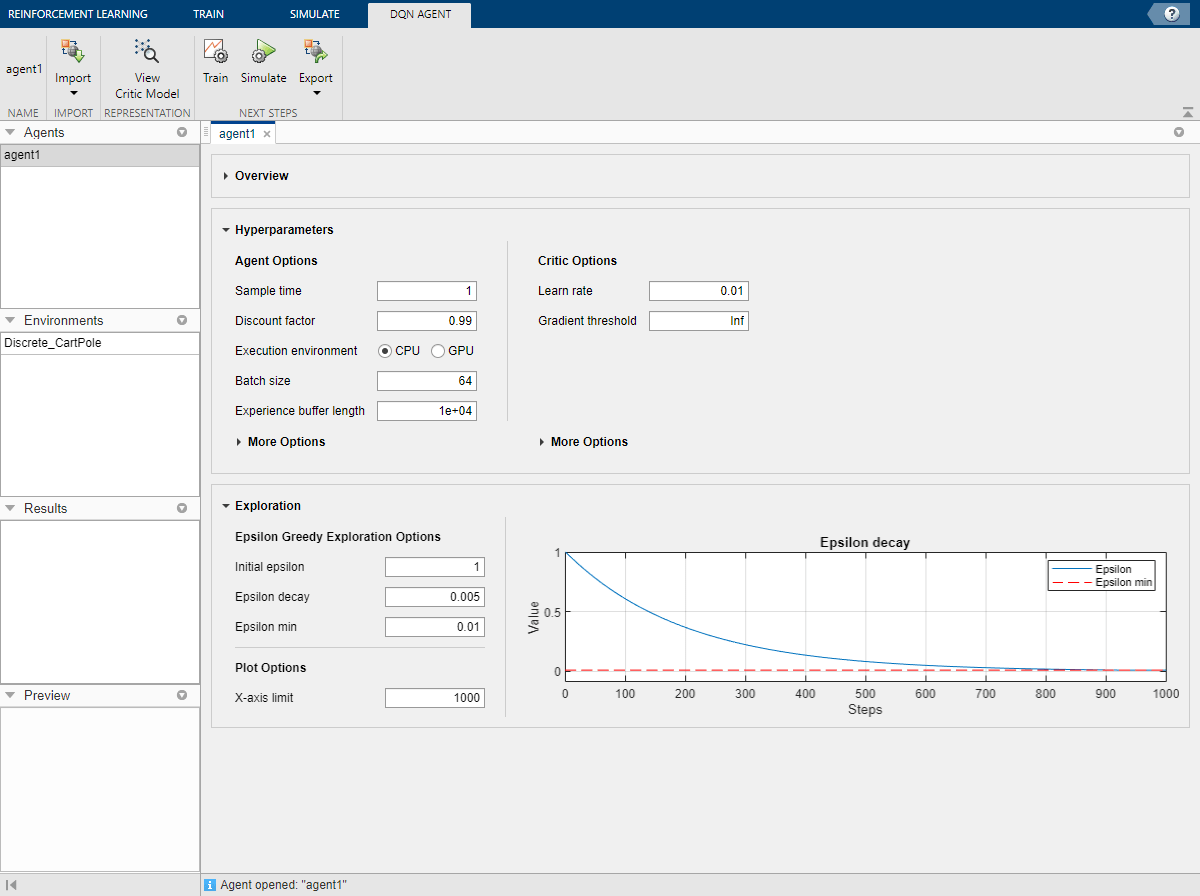
Можно также импортировать агента из MATLAB® рабочая область в Reinforcement Learning Designer. Для этого на вкладке Reinforcement Learning нажмите Import. Затем в разделе Select Agent выберите агента для импорта.
Приложение добавляет нового импортированного агента в область Agents и открывает документ для редактирования опций агента.
В Reinforcement Learning Designer можно изменить опции агента в соответствующем документе агента.
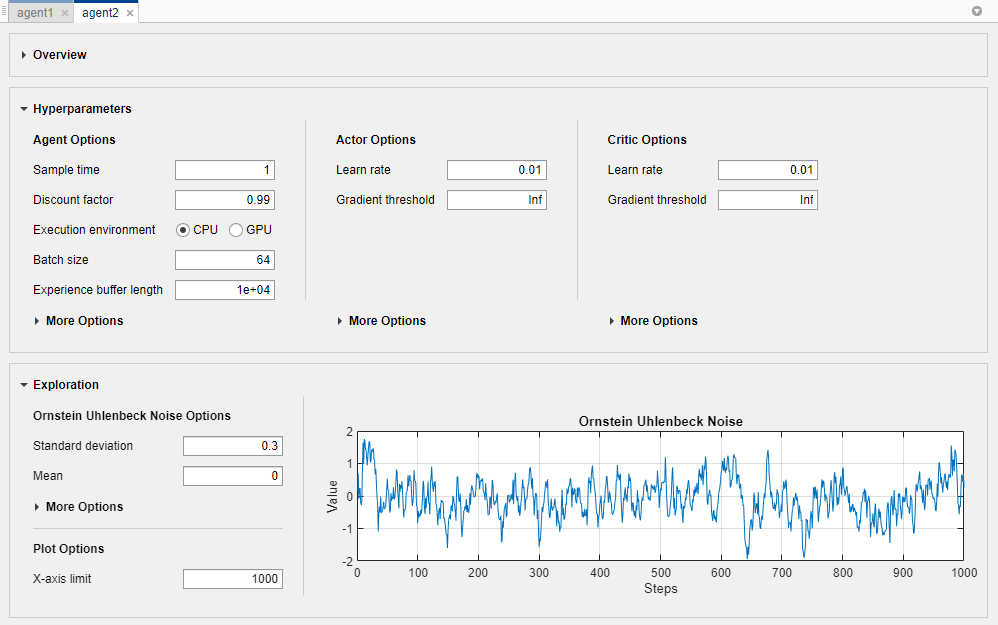
Для каждого агента можно изменить следующие опции.
Agent Options - опции агента, такие как шаги расчета и коэффициент скидки. Задайте эти опции для всех поддерживаемых типов агентов.
Exploration Model - Опции модели исследования. Агенты PPO не имеют модели исследования.
Target Policy Smoothing Model - опции для сглаживания целевой политики, которые поддерживаются только для агентов TD3.
Для получения дополнительной информации об этих опциях см. соответствующий объект параметров агента.
rlDQNAgentOptions - Опции агента DQN
rlDDPGAgentOptions - Опции агента DDPG
rlTD3AgentOptions - TD3 параметров агента
rlPPOAgentOptions - Опции агента PPO
Можно импортировать опции агента из рабочего пространства MATLAB. Чтобы создать опции для каждого типа агента, используйте один из предыдущих объектов. Можно также импортировать опции, которые вы ранее экспортировали из приложения Reinforcement Learning Designer
Чтобы импортировать опции, на соответствующей вкладке Agent нажмите Import. Затем под Options выберите объект опции. Приложение перечисляет только объекты совместимых опций из рабочего пространства MATLAB.
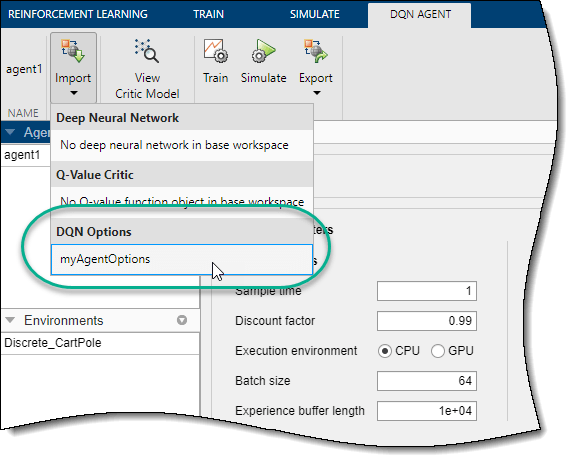
Приложение настраивает опции агента так, чтобы они совпадали с параметрами В выбранном объекте опции.
Можно редактировать свойства представлений актёра и критика для каждого агента.
У агентов DQN есть просто критическая сеть.
Агенты DDPG и PPO имеют представление актера и представление критика.
TD3 агенты имеют представление актера и два представления критика. При изменении опций представления критика для агента TD3 изменения применяются к обоим критикам.
Можно также импортировать представления актёра и критика из рабочего пространства MATLAB. Для получения дополнительной информации о создании представлений актёра и критика, смотрите, Создают Политику и Представления Функции Ценности. Можно также импортировать представления, которые вы ранее экспортировали из приложения Reinforcement Learning Designer.
Чтобы импортировать представление актёра или критика, на соответствующей вкладке Agent, нажмите Import. Затем под Actor или Critic выберите объект представления со спецификациями действий и наблюдений, которые совместимы со спецификациями агента.
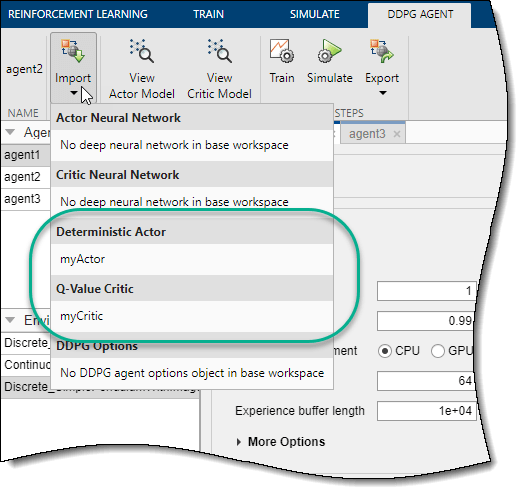
Приложение заменяет представление актёра или критика в агенте выбранным представлением. Если вы импортируете представление критика для агента TD3, приложение заменяет сеть для обоих критиков.
Чтобы использовать недефектную глубокую нейронную сеть для актёра или критика, необходимо импортировать сеть из рабочего пространства MATLAB. Одной из распространенных стратегий является экспорт глубокой нейронной сети по умолчанию, изменение ее с помощью приложения Deep Network Designer, а затем импорт обратно в Reinforcement Learning Designer. Для получения дополнительной информации о создании глубоких нейронных сетей для актёров и критиков, смотрите, Создают Политику и Представления Функции Ценности.
Чтобы импортировать глубокую нейронную сеть, на соответствующей вкладке Agent нажмите Import. Затем под Actor Neural Network или Critic Neural Network выберите сеть с входом и выходными слоями, которые совместимы с наблюдением и спецификациями действия агента.
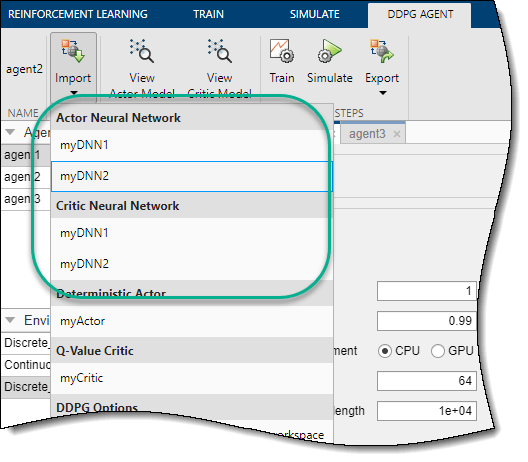
Приложение заменяет глубокую нейронную сеть в соответствующем представлении актёра или агента. Если вы импортируете сеть критика для агента TD3, приложение заменяет сеть для обоих критиков.
Для данного агента можно экспортировать любое из следующих в рабочее пространство MATLAB.
Агент
Опции агента
Представление актёра или критика
Актёр или критик глубокой нейронной сети
Чтобы экспортировать агент или компонент агента, на соответствующей вкладке Agent, нажмите Export. Затем выберите элемент для экспорта.
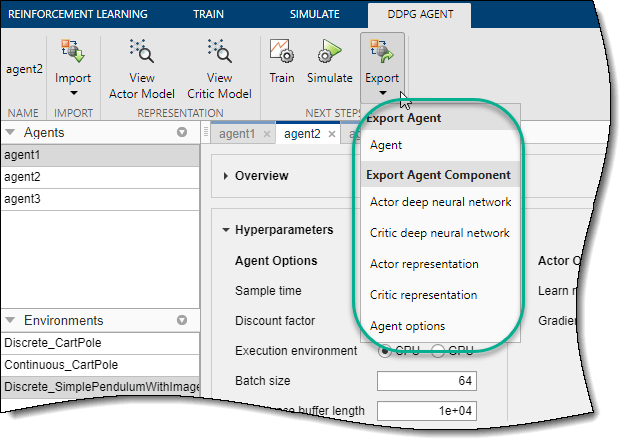
Приложение сохраняет копию агента или компонента агента в рабочем пространстве MATLAB.
Reinforcement Learning Designer
