Алгоритм мягкого актёра-критика (SAC) является онлайновым методом обучения с подкреплением актёра без моделей и без политики. Алгоритм SAC вычисляет оптимальную политику, которая максимизирует как долгосрочное ожидаемое вознаграждение, так и энтропию политики. Энтропия политики является мерой неопределенности политики, учитывая состояние. Более высокое значение энтропии способствует большему исследованию. Максимизация как ожидаемого совокупного долгосрочного вознаграждения, так и балансов энтропии, а также эксплуатация и исследования окружения.
Для получения дополнительной информации о различных типах агентов обучения с подкреплением смотрите Reinforcement Learning Agents.
Реализация агента SAC в пакете Reinforcement Learning Toolbox™ использует два критика функции Q-значения, что предотвращает завышение функции ценности. Другие реализации алгоритма SAC используют дополнительную функцию ценности критика.
Агенты SAC могут быть обучены в окружениях со следующими пространствами наблюдений и действий.
| Пространство наблюдений | Пространство действий |
|---|---|
| Дискретный или непрерывный | Непрерывный |
Агенты SAC используют следующие представления актёра и критика.
| Критик | Актер |
|---|---|
Критик функции Q (S, A), которую вы создаете | Актёр Стохастической политики (S), который вы создаете используя |
Во время обучения агент SAC:
Обновляет свойства актёра и критика через регулярные интервалы времени во время обучения.
Оценивает среднее и стандартное отклонение Гауссова распределения вероятностей для непрерывного пространства действий, затем случайным образом выбирает действия на основе распределения.
Обновляет термин энтропийного веса, который балансирует ожидаемый возврат и энтропию политики.
Сохраняет прошлый опыт с помощью буфера циклического опыта. Агент обновляет актёра и критика, используя мини-пакет переживаний, случайным образом выбранных из буфера.
Если на UseDeterministicExploitation опция в rlSACAgentOptions установлено в true действие с максимальной вероятностью всегда используется в sim и generatePolicyFunction. Это заставляет моделируемого агента и сгенерированную политику вести себя детерминированно.
Чтобы оценить политику и функцию ценности, агент SAC поддерживает следующие функциональные аппроксимации:
Стохастический актёр μ (S) - актёр принимает S наблюдения и возвращает функцию плотности вероятностей действия. Агент случайным образом выбирает действия на основе этой функции плотности.
Один или два критика Q-значения Qk (S, A) - критики берут наблюдение S и действие A как входы и возвращают соответствующее ожидание функции ценности, которая включает и долгосрочное вознаграждение и энтропию.
Один или два Q'k целевых критиков (S, A) - для повышения устойчивости оптимизации агент периодически обновляет целевых критиков на основе последних значений параметров критиков. Количество целевых критиков совпадает с количеством критиков.
Когда вы используете двух критиков, Q 1 (S, A) и Q 2 (S, A), каждый критик может иметь разную структуру. Когда критики имеют ту же структуру, они должны иметь другие начальные значения параметров.
Для каждого критика Qk (S, A) и Q'k (S, A) имеют одинаковую структуру и параметризацию.
Когда обучение завершено, обученная оптимальная политика сохранена в μ актёра (S).
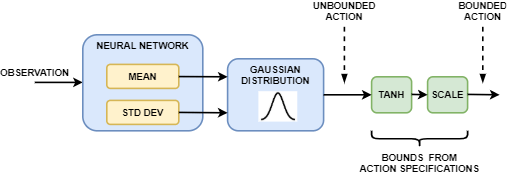
Актёр в агенте SAC генерирует выходные выходы среднего и стандартного отклонений. Чтобы выбрать действие, актёр сначала случайным образом выбирает неограниченное действие из Гауссова распределения с этими параметрами. Во время обучения агент SAC использует неограниченное распределение вероятностей, чтобы вычислить энтропию политики для заданного наблюдения.
Если пространство действий агента SAC ограничено, актёр генерирует ограниченные действия путем применения операций tanh и масштабирования к неограниченному действию.
Можно создать агента SAC с представлениями актёра и критика по умолчанию на основе наблюдений и спецификаций действия от окружения. Для этого выполните следующие шаги.
Создайте спецификации наблюдений для вашего окружения. Если у вас уже есть объект интерфейса окружения, можно получить эти спецификации, используя getObservationInfo.
Создайте спецификации действия для вашего окружения. Если у вас уже есть объект интерфейса окружения, можно получить эти спецификации, используя getActionInfo.
При необходимости укажите количество нейронов в каждом обучаемом слое или использовать рекуррентную нейронную сеть. Для этого создайте объект опции инициализации агента с помощью rlAgentInitializationOptions.
При необходимости задайте опции агента, используя rlSACAgentOptions объект.
Создайте агента с помощью rlSACAgent объект.
Кроме того, можно создать представления актёра и критика и использовать эти представления для создания агента. В этом случае убедитесь, что входная и выходная размерности представлений актёра и критика совпадают с соответствующими спецификациями действий и наблюдений окружения.
Создайте стохастического актёра, используя rlStochasticActorRepresentation объект. Для агентов SAC сеть актёра не должна содержать tanhLayer и scalingLayer в среднем выходном пути.
Создайте одного или двух критиков, используя rlQValueRepresentation объекты.
Задайте опции агента, используя rlSACAgentOptions объект.
Создайте агента с помощью rlSACAgent объект.
Агенты SAC не поддерживают актёров и критиков, которые используют рецидивирующие глубокие нейронные сети в качестве функциональной аппроксимации.
Для получения дополнительной информации о создании актёров и критиков для приближения функций, смотрите Создать политику и Представления функции ценности.
Агенты SAC используют следующий алгоритм настройки, в котором они периодически обновляют свои модели актёра и критика и энтропийный вес. Чтобы сконфигурировать алгоритм настройки, задайте опции используя rlSACAgentOptions объект. Здесь K = 2 - количество критиков и k - индекс критика.
Инициализируйте каждый Qk критика (S, A) со случайными значениями параметров θQk и инициализируйте каждого целевого критика с одинаковыми случайными значениями параметров:.
Инициализируйте μ актёра (S) со случайными значениями параметров θμ.
Выполните теплое начало, выполнив последовательность действий, следующих за начальной случайной политикой в μ (S). Для каждого действия сохраните опыт в буфере опыта. Чтобы задать количество действий разогрева, используйте NumWarmStartSteps опция.
Для каждого временного шага обучения:
Для текущей S наблюдения выберите действие A используя политику в μ (S).
Выполните действие A. Наблюдайте за R вознаграждения и следующими S' наблюдения.
Сохраните опыт (S, A, R, S') в буфере опыта.
Пробуйте случайную мини-партию M события (Si, Ai, Ri, S'i) от буфера опыта. Чтобы задать M, используйте MiniBatchSize опция.
Каждый DC временные шаги обновляйте параметры каждого критика, минимизируя Lk потерь во всех выборочных опытах. Чтобы задать DC, используйте CriticUpdateFrequency опция.
Если S'i является конечным состоянием, целевой yi функции ценности равен Ri вознаграждения опыта. В противном случае цель функции ценности является суммой Ri, минимальным дисконтированным будущим вознаграждением от критиков и взвешенной H энтропии.
Здесь:
A'i - ограниченное действие, выведенное из неограниченного выхода μ актёра (S'i).
γ - коэффициент скидки, который вы задаете используя DiscountFactor опция.
H - энтропия политики, которая вычисляется для неограниченного выхода актёра.
α - вес настройки энтропии, который агент SAC настраивает во время обучения.
Каждый DA временные шаги обновляйте параметры актёра путем минимизации следующей целевой функции. Чтобы задать DA, используйте PolicyUpdateFrequency опция.
Каждый DA временные шаги, также обновляйте энтропийный вес, минимизируя следующую функцию потерь.
Здесь H' является целевой энтропией, которую вы задаете используя EntropyWeightOptions.TargetEntropy опция.
Каждый D T шагов обновляйте целевых критиков в зависимости от целевого метода обновления. Чтобы задать D T, используйте TargetUpdateFrequency опция. Дополнительные сведения см. в разделе Методы целевого обновления.
Повторите шаги с 4 по 8 NG раз, где NG - количество шагов градиента, которые вы задаете используя NumGradientStepsPerUpdate опция.
Агенты SAC обновляют свои параметры целевого критика с помощью одного из следующих методов целевого обновления.
Сглаживание - обновляйте параметры целевого критика в каждый временной шаг с помощью τ коэффициента сглаживания. Чтобы задать коэффициент сглаживания, используйте TargetSmoothFactor опция.
Периодический - Периодически обновляйте параметры целевого критика без сглаживания (TargetSmoothFactor = 1). Чтобы задать период обновления, используйте TargetUpdateFrequency параметр.
Периодическое сглаживание - периодически обновляйте целевые параметры с сглаживанием.
Чтобы сконфигурировать целевой метод обновления, создайте rlSACAgentOptions Объекту и установите TargetUpdateFrequency и TargetSmoothFactor параметры, как показано в следующей таблице.
| Метод обновления | TargetUpdateFrequency | TargetSmoothFactor |
|---|---|---|
| Сглаживание (по умолчанию) | 1 | Менее 1 |
| Периодический | Больше 1 | 1 |
| Периодическое сглаживание | Больше 1 | Менее 1 |
[1] Haarnoja, Tuomas, Aurick Zhou, Kristian Hartikainen, George Tucker, Sehoon Ha, Jie Tan, Vikash Kumar, et al. «Алгоритмы и применение мягкого актёра-критика». Препринт, представленный 29 января 2019 года. https://arxiv.org/abs/1812.05905.
rlSACAgent | rlSACAgentOptions
