Как только вы создали окружение и агента обучения с подкреплением, можно обучить агента в окружении, используя train функция. Чтобы сконфигурировать свое обучение, используйте rlTrainingOptions функция. Например, создайте набор опций обучения opt, и обучите агента agent в окружении env.
opt = rlTrainingOptions(... 'MaxEpisodes',1000,... 'MaxStepsPerEpisode',1000,... 'StopTrainingCriteria',"AverageReward",... 'StopTrainingValue',480); trainStats = train(agent,env,opt);
Для получения дополнительной информации о создании агентов см. Раздел «Агенты обучения с подкреплением». Для получения дополнительной информации о создании окружений смотрите Создание окружений обучения с подкреплением MATLAB и Создание окружений обучения с подкреплением Simulink.
train обновляет агент по мере процессов обучения. Чтобы сохранить параметры исходного агента для дальнейшего использования, сохраните агент в MAT-файле.
save("initialAgent.mat","agent")
Обучение прекращается автоматически, когда условия, которые вы задаете в StopTrainingCriteria и StopTrainingValue опции вашего rlTrainingOptions объект удовлетворен. Чтобы вручную прекратить обучение в прогресс, введите Ctrl+C или, в Диспетчере эпизодов обучения с подкреплением, нажмите Stop Training. Потому что train обновляет агента в каждом эпизоде, можно возобновить обучение, позвонив train(agent,env,trainOpts) снова, не теряя обученных параметров, выученных во время первого вызова, train.
В целом обучение выполняет следующие шаги.
Инициализируйте агента.
Для каждого эпизода:
Сбросьте окружение.
Получите s 0 начального наблюдения от окружения.
Вычислите начальное действие a 0 = μ (s 0), где μ (s) является текущей политикой.
Установите текущее действие на начальное действие (a − a 0) и установите текущее наблюдение на начальное наблюдение (s − s 0).
Пока эпизод не закончен или не завершен, выполните следующие шаги.
Примените a действия к окружению и получите следующий s' наблюдения 'и r вознаграждения.
Учитесь на наборе опыта (s, a, r, s').
Вычислите следующее действие a' = μ (s').
Обновите текущее действие следующим действием (a − a') и обновите текущее наблюдение следующим наблюдением (s − s').
Завершает эпизод, если выполняются условия завершения, определенные в окружении.
Если условие прекращения обучения выполнено, завершите обучение. В противном случае начнем следующий эпизод.
Особенности выполнения этих шагов программным обеспечением зависят от строения агента и окружения. Например, сброс окружения в начале каждого эпизода может включать рандомизацию начальных значений состояния, если вы конфигурируете своё окружение, чтобы сделать это. Для получения дополнительной информации об агентах и их алгоритмах обучения смотрите Обучение с Подкреплением Agents. Чтобы использовать параллельную обработку и графические процессоры для ускорения обучения, смотрите Train агентов с использованием параллельных вычислений и графических процессоров.
По умолчанию вызов функции train функция открывает Диспетчер эпизодов обучения с подкреплением, который позволяет вам визуализировать процесс обучения. График Диспетчера эпизодов показывает вознаграждение за каждый эпизод (EpisodeReward) и текущее среднее значение вознаграждения (AverageReward). Кроме того, для агентов, у которых есть критики, график показывает оценку критиком дисконтированного долгосрочного вознаграждения в начале каждого эпизода (EpisodeQ0). Диспетчер эпизодов также отображает различные эпизоды и статистику обучения. Вы также можете использовать train функция для возврата эпизода и обучающей информации.
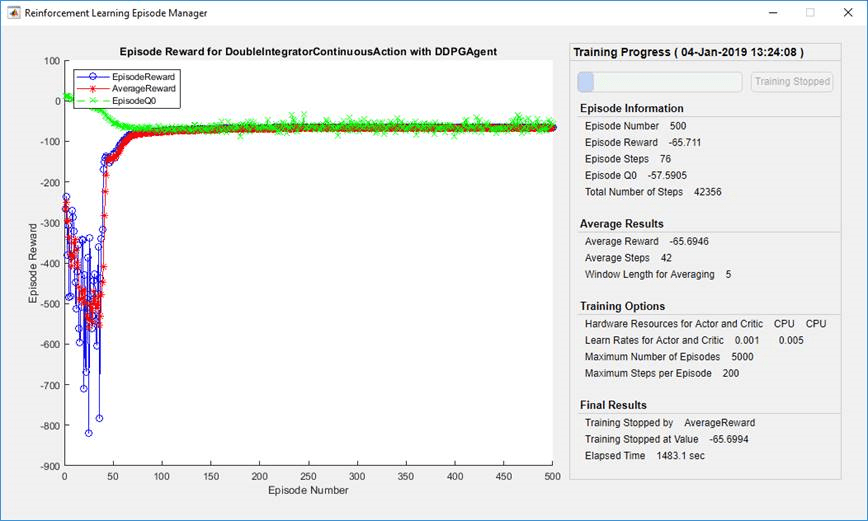
Для агентов с критиком Episode Q0 является оценкой дисконтированного долгосрочного вознаграждения в начале каждого эпизода, учитывая первоначальное наблюдение окружения. Когда обучение прогрессирует, если критик хорошо спроектирован. Episode Q0 приближается к истинному дисконтированному долгосрочному вознаграждению, как показано на предыдущем рисунке.
Чтобы выключить Диспетчер эпизодов обучения с подкреплением, установите Plots опция rlTrainingOptions на "none".
Во время обучения можно сохранить агентов кандидата, которые соответствуют условиям, заданным в SaveAgentCriteria и SaveAgentValue опций вашего rlTrainingOptions объект. Например, можно сохранить любого агента, чье вознаграждение по эпизоду превышает определенное значение, даже если общее условие прекращения обучения еще не удовлетворено. Для примера сохраните агентов, когда вознаграждение эпизода больше 100.
opt = rlTrainingOptions('SaveAgentCriteria',"EpisodeReward",'SaveAgentValue',100');
train хранит сохраненные агенты в MAT-файле в указанной папке с помощью SaveAgentDirectory опция rlTrainingOptions. Сохраненные агенты могут быть полезны, например, для тестирования агентов-кандидатов, сгенерированных во время длительного процесса обучения. Для получения дополнительной информации о сохранении критериев и сохранении местоположения смотрите rlTrainingOptions.
После завершения обучения можно сохранить последнего обученного агента из MATLAB® рабочей области с использованием save функция. Для примера сохраните агент myAgent в файл finalAgent.mat в текущей рабочей директории.
save(opt.SaveAgentDirectory + "/finalAgent.mat",'agent')
По умолчанию при сохранении агентов DDPG и DQN буферные данные опыта не сохраняются. Если вы планируете продолжить обучение своего сохраненного агента, можно начать обучение с предыдущего буфера опыта в качестве начальной точки. В этом случае установите SaveExperienceBufferWithAgent опция для true. Для некоторых агентов, таких как те, которые имеют большие буферы опыта и наблюдения на основе изображений, память, необходимая для сохранения буфера опыта, велика. В этих случаях необходимо убедиться, что для сохраненных агентов достаточно памяти.
Чтобы подтвердить своего обученного агента, можно симулировать агента в среде обучения с помощью sim функция. Чтобы сконфигурировать симуляцию, используйте rlSimulationOptions.
При проверке вашего агента рассмотрите, как ваш агент обрабатывает следующее:
Изменения начальных условий симуляции - Чтобы изменить начальные условия модели, измените функцию сброса для окружения. Для получения примера функций сброса смотрите Создание Окружения MATLAB С помощью Пользовательских функций, Создание Пользовательских Окружений MATLAB из шаблона и Создание Окружений Обучения с Подкреплением Simulink.
Несоответствия между динамикой среды обучения и симуляции - Чтобы проверить такие несоответствия, создайте тестовые окружения так же, как вы создали окружение обучения, изменив поведение окружения.
Как и при параллельном обучении, если у вас есть программное обеспечение Parallel Computing Toolbox™, можно запустить несколько параллельных симуляций на многоядерных компьютерах. Если у вас есть программное обеспечение MATLAB Parallel Server™, можно запустить несколько параллельных симуляций на компьютерных кластерах или облачных ресурсах. Для получения дополнительной информации о настройке симуляции для использования параллельных вычислений смотрите UseParallel и ParallelizationOptions в rlSimulationOptions.
Если ваше окружение обучения реализует plot метод, можно визуализировать поведение окружения во время обучения и симуляции. Если вы звоните plot(env) перед обучением или симуляцией, где env является вашим объектом окружения, затем визуализация обновляется во время обучения, чтобы позволить вам визуализировать прогресс каждого эпизода или симуляции.
Визуализация окружения не поддерживается при обучении или симуляции агента с помощью параллельных вычислений.
Для пользовательских окружений необходимо реализовать свои собственные plot способ. Для получения дополнительной информации о создании пользовательских окружений с plot , см. «Создание пользовательского окружения MATLAB из шаблона».
