Многоядерное программирование помогает вам создавать параллельные системы для развертывания на многоядерных процессорных и многопроцессорных системах. Система многоядерного процессора является одним процессором с множеством потоков выполнения ядрами в одном чипе. В отличие от этого, многопроцессорная система имеет несколько процессоров на материнской плате или чипе. Многопроцессорная система может включать программируемую в поле массив ворот (FPGA). FPGA является интегральной схемой, содержащей массив программируемых логических блоков и иерархию реконфигурируемых взаимосвязей. Узел обработки обрабатывает входные данные, чтобы получить выходы. Это может быть процессор в многоядерной или многопроцессорной системе или FPGA.
Многоядерный подход к программированию может помочь, когда:
Вы хотите воспользоваться преимуществами многоядерной обработки и обработки FPGA, чтобы увеличить эффективность встраиваемой системы.
Вы хотите достичь масштабируемости, чтобы развернутая система могла воспользоваться увеличением количества ядер и вычислительной степени FPGA с течением времени.
Параллельные системы, которые вы создаете с использованием многоядерного программирования, имеют несколько задач, выполняемых параллельно. Это известно как параллельное выполнение. Когда процессор выполняет несколько параллельных задач, он известен как многозадачность. Центральный процессор имеет микропрограмму, называемую планировщиком, которая обрабатывает задачи, которые выполняются параллельно. Центральный процессор реализует задачи, используя потоки операционной системы. Ваши задачи могут выполняться независимо, но имеют некоторую передачу данных между ними, например, передачу данных между модулем сбора данных и контроллером для системы. Передача данных между задачами означает, что существует зависимость данных.
Многоядерное программирование обычно используется в системах обработки сигналов и управления объектом. При обработке сигналов можно иметь параллельную систему, которая обрабатывает несколько системы координат параллельно. В системах управления заводом контроллер и объект могут выполнять как две отдельные задачи. Использование многоядерного программирования помогает разделить вашу систему на несколько параллельных задач, которые выполняются одновременно, ускоряя общее время выполнения.
Чтобы смоделировать одновременно выполняемую систему, см. Руководство по секционированию.
Концепция многоядерного программирования состоит в том, чтобы несколько системных задач выполнялись параллельно. Типы параллелизма включают:
Параллелизм данных
Параллелизм задач
Конвейеризация
Параллелизм данных включает обработку нескольких частей данных независимо параллельно. Процессор выполняет ту же операцию на каждом блоке данных. Параллелизм достигается путем параллельной подачи данных.
Рисунок показывает временную схему для этого параллелизма. Вход разделен на четыре фрагментов, A, B, C и D. Та же операция F() применяется к каждой из этих частей, и выходом является OA, OB, OC и OD соответственно. Все четыре задачи идентичны, и они выполняются параллельно.
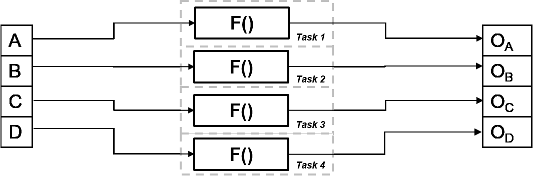
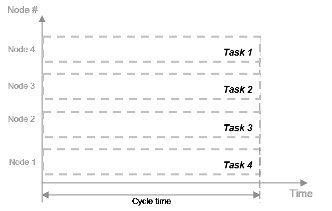
Время, затрачиваемое на каждый цикл процессора, известное как время цикла, t = tF.
Общее время вычислений также tF, поскольку все четыре задачи выполняются одновременно. В отсутствие параллелизма все четыре части данных обрабатываются одним узлом обработки. Время цикла tF для каждой задачи, но общее время вычислений 4*tF, поскольку части обрабатываются последовательно.
Можно использовать параллелизм данных в сценариях, где можно обрабатывать каждую часть входных данных независимо. Для примера веб-база данных с независимыми наборами данных для обработки или обработки систем координат видео независимо являются хорошими кандидатами для параллелизма данных.
В отличие от параллелизма данных, параллелизм задачи не разделяет входные данные. Вместо этого он достигает параллелизма путем разделения приложения на несколько задач. Параллелизм задачи включает распределение задач внутри приложения между несколькими узлами обработки. Одни задачи могут иметь зависимость данных от других, поэтому все задачи не выполняются точно в одно и то же время.
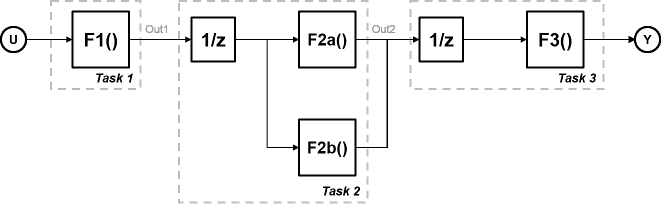
Рассмотрим систему, которая включает четыре функции. Функции F2a () и F2b () параллельны, то есть могут запускаться одновременно. В параллелизме задачи можно разделить расчет на две задачи. Функция F2b () запускается на отдельном узле обработки после того, как она получает Out1 данных из Задачи 1 и выводит назад в F3 () в Задаче 1.
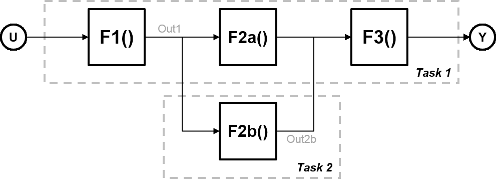
Рисунок показывает временную схему для этого параллелизма. Задача 2 не запускается, пока она не получит Out1 данных из Задачи 1. Следовательно, эти задачи не выполняются полностью параллельно. Время, затрачиваемое на цикл процессора, известное как время цикла, является
t = tF1 + max (tF2a, tF2b) + tF3.
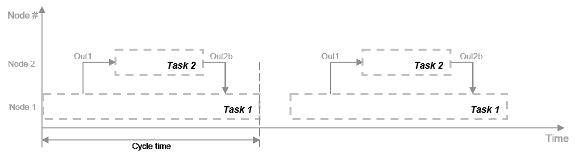
Можно использовать параллелизм задач в сценариях, таких как завод, где объект и контроллер выполняются параллельно.
Используйте выполнение модели трубопровода, или конвейеризацию, чтобы обойти задачу параллелизма задачи, где потоки не проходят полностью параллельно. Этот подход включает изменение системной модели, чтобы ввести задержки между задачами, где существует зависимость данных.
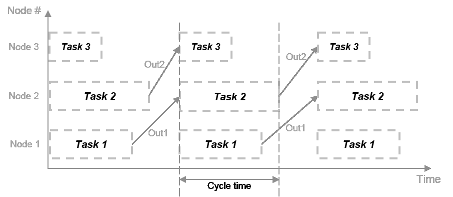
На этом рисунке система разделена на три задачи для выполнения на трех различных узлах обработки с задержками, введенными между функциями. На каждом временном шаге каждая задача принимает значение от предыдущего временного шага посредством задержки.
Каждая задача может начать обработку одновременно, как показывает эта временная схема. Эти задачи действительно параллельны, и они больше не зависят друг от друга последовательно в одном процессорном цикле. Время цикла не имеет никаких сложений, но является максимальным временем вычислений всех задач.
t = макс. (Task1, Task2, Task3) = макс. (tF1, tF2a, tF2b, tF3).
Конвейерную конвейеризация можно использовать везде, где можно искусственно ввести задержки в одновременно выполняемой системе. Результирующие накладные расходы из-за этого введения не должны превышать времени, сэкономленного при конвейеризации.
Методы секционирования помогают вам обозначить области системы для параллельного выполнения. Разбиение позволяет создавать задачи независимо от специфики целевой системы, на которой развернуто приложение.
Рассмотрим эту систему. F1-F6 являются функциями системы, которые могут выполняться независимо. Стрела между двумя функциями указывает на зависимость данных. Например, выполнение F5 имеет зависимость данных от F3.
Выполнение этих функций назначается различным процессорным узлам в целевой системе. Серые стрелы указывают на назначение функций, которые будут развернуты на центральном процессоре или FPGA. Планировщик центрального процессора определяет, когда выполняются отдельные задачи. CPU и FPGA взаимодействуют через общую шину связи.
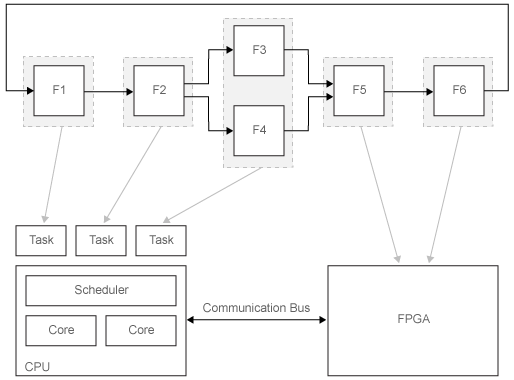
Рисунок показывает одно возможное строение для разбиения. В целом, вы тестируете различные строения и итеративно улучшаете, пока не получите оптимальное распределение задач для вашего приложения.
Ручное кодирование вашего приложения на многоядерном процессоре или FPGA создает проблемы, помимо проблем, вызванных ручным кодированием. При параллельном выполнении необходимо отслеживать:
Планирование задач, которые выполняются на многоядерном процессоре встраиваемой системы обработки
Передача данных в различные узлы обработки и из них
Simulink управляет реализацией задач и передачей данных между задачами. Он также генерирует код, который развертывается для приложения. Для получения дополнительной информации смотрите Многоядерное программирование с Simulink.
В дополнение к этим проблемам возникают проблемы, когда необходимо развернуть приложение в различных архитектурах и когда необходимо повысить эффективность развертываемого приложения.
Аппаратное строение, которая запускает развернутое приложение, известно как архитектура. Он может содержать многоядерные процессоры, многопроцессорные системы, FPGA или их комбинацию. Развертывание одного и того же приложения в различных архитектурах может потребовать усилий из-за:
Разное количество и типы процессорных узлов в архитектуре
Стандарты связи и передачи данных для архитектуры
Стандарты для определенных событий, синхронизации и защиты данных в каждой архитектуре
Чтобы развернуть приложение вручную, необходимо переназначить задачи различным узлам обработки для каждой архитектуры. Также может потребоваться повторное внедрение приложения, если каждая архитектура использует различные стандарты.
Simulink помогает преодолеть эти проблемы, предлагая переносимость между архитектурами. Для получения дополнительной информации смотрите, Как Simulink помогает вам преодолеть проблемы в многоядерном программировании.
Можно повысить эффективность развертываемого приложения путем балансировки нагрузки различных узлов обработки в окружении обработки. Необходимо выполнить итерацию и улучшить распределение задач во время разбиения, как упомянуто в System Partitioning for Parallelism. Этот процесс включает перемещение задач между различными узлами обработки и проверку полученной эффективности. Поскольку это итерационный процесс, требуется время, чтобы найти наиболее эффективное распределение.
Simulink помогает вам преодолеть эти проблемы с помощью профилирования. Для получения дополнительной информации смотрите, Как Simulink помогает вам преодолеть проблемы в многоядерном программировании.
Некоторые задачи системы зависят от выхода других задач. Зависимость данных между задачами определяет порядок их обработки. Два или более разделов, содержащих зависимости данных в цикле, создают цикл зависимости данных, также известный как алгебраический цикл.
Simulink идентифицирует циклы в вашей системе перед развертыванием. Для получения дополнительной информации смотрите, Как Simulink помогает вам преодолеть проблемы в многоядерном программировании.
