В этом примере показано, как создать и сравнить различные наивные классификаторы Байеса с помощью приложения Classification Learner и экспортировать обученные модели в рабочую область, чтобы делать предсказания для новых данных.
Наивные классификаторы Байеса используют теорему Бейеса и делают предположение, что предикторы независимы друг от друга в каждом классе. Однако классификаторы работают хорошо, даже когда предположение независимости не верно. Можно использовать наивный Байес с двумя или несколькими классами в Classification Learner. Приложение позволяет вам обучать Гауссову наивную модель Бейеса или ядерную наивную модель Бейеса индивидуально или одновременно.
Эта таблица приводит доступные наивные модели Байеса в Classification Learner и распределения вероятностей, используемые каждой моделью, чтобы соответствовать предикторам.
| Модель | Численный предиктор | Категориальный предиктор |
|---|---|---|
| Гауссов наивный Бейес | Гауссово распределение (или нормальное распределение) | многомерное полиномиальное распределение |
| Ядерный наивный Бейес | Ядерное распределение Можно задать тип ядра и поддержку. Classification Learner автоматически определяет ширину ядра, используя базовую fitcnb функция. | многомерное полиномиальное распределение |
Этот пример использует набор данных о радужке Фишера, который содержит измерения цветов (длина лепестка, ширина лепестка, длина чашелистика и ширина чашелистика) для образцов трех видов. Обучите наивные классификаторы Байеса прогнозировать виды на основе измерений предиктора.
В MATLAB® Командное окно, загрузите набор данных радужки Фишера и создайте таблицу предикторов измерения (или функций), используя переменные из набора данных.
fishertable = readtable('fisheriris.csv');Щелкните вкладку Apps, а затем щелкните стреле справа от раздела Apps, чтобы открыть галерею Apps. В группе Machine Learning and Deep Learning нажмите Classification Learner.
На вкладке Classification Learner, в разделе File, выберите New Session > From Workspace.

В диалоговом окне Новый сеанс из рабочей области выберите таблицу fishertable из Data Set Variable списка (при необходимости).
Как показано в диалоговом окне, приложение выбирает переменные отклика и предиктора на основе их типа данных. Длина и ширина лепестка и сепаля являются предикторами, а виды - это реакция, которую вы хотите классифицировать. В данном примере не изменяйте выбор.
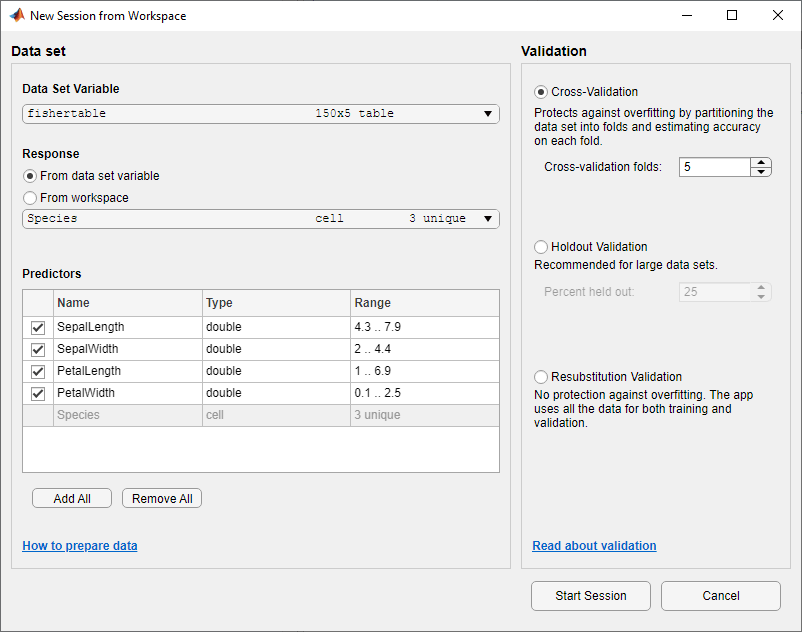
Чтобы принять схему валидации по умолчанию и продолжить, нажмите Start Session. Опция валидации по умолчанию является перекрестной валидацией, чтобы защитить от сверхподбора кривой.
Classification Learner создает график поля точек данных.
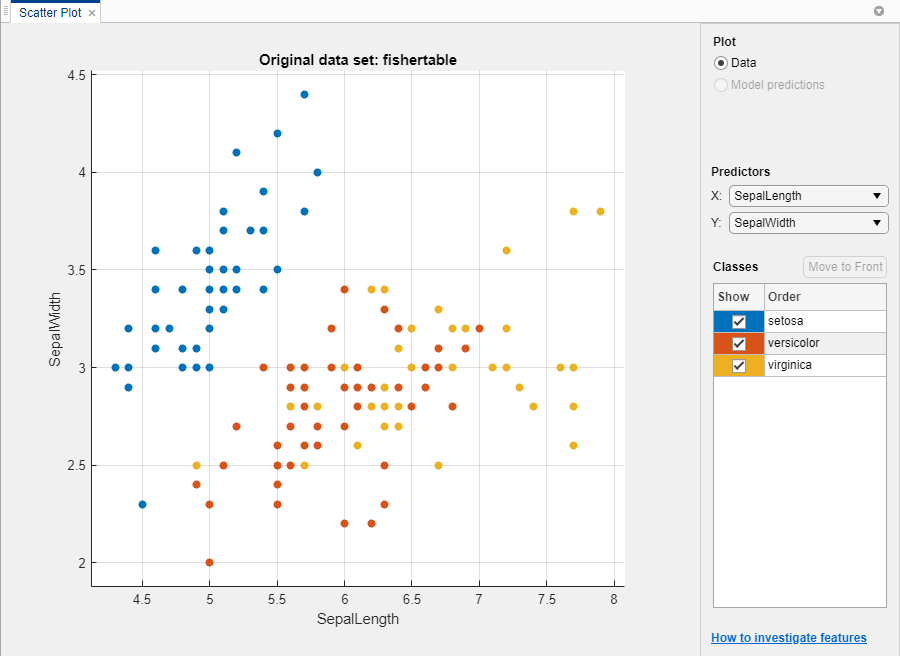
Используйте график поля точек, чтобы выяснить, какие переменные полезны для предсказания отклика. Выберите различные опции в списках X и Y под Predictors, чтобы визуализировать распределение видов и измерений. Наблюдайте, какие переменные разделяют цвета видов наиболее четко.
The setosa вид (синие точки) легко отделить от двух других видов со всеми четырьмя предикторами. The versicolor и virginica виды намного ближе друг к другу во всех предикторных измерениях и перекрытиях, особенно когда вы строите график длины и ширины чашелистика. setosa легче предсказать, чем два других вида.
Создайте наивную модель Байеса. На вкладке Classification Learner, в разделе Model Type, щелкните стреле, чтобы открыть галерею. В группе Naive Bayes Classifiers нажмите Gaussian Naive Bayes. Обратите внимание, что Classification Learner отключает кнопку Advanced в разделе Model Type, поскольку этот тип модели не имеет дополнительных настроек.

В Training разделе нажмите Train.
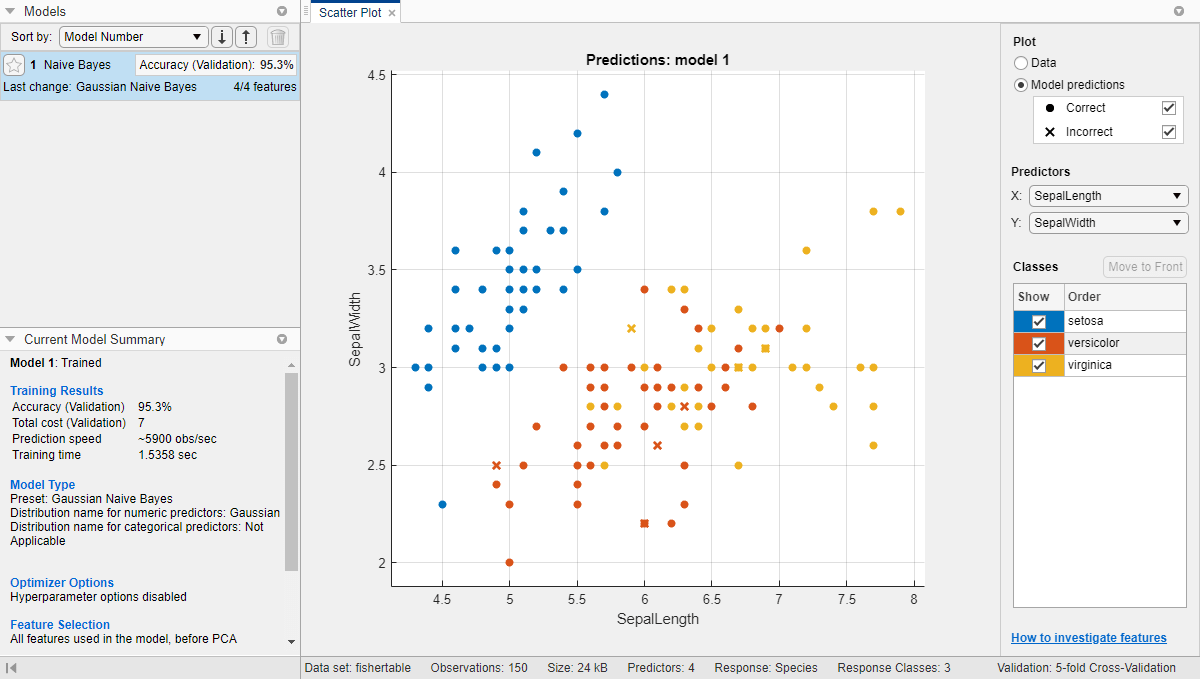
Приложение создает Гауссову наивную модель Байеса и строит графики результатов.
Приложение отображает модель Gaussian Naive Bayes на панели Models. Проверьте счет валидации модели в Accuracy (Validation) окне. Счет показывает, что модель работает хорошо.
Для модели Gaussian Naive Bayes по умолчанию приложение моделирует распределение числовых предикторов с помощью Гауссова распределения и моделирует распределение категориальных предикторов с помощью многомерного полиномиального распределения (MVMN).
Примечание
Валидация вводит некоторую случайность в результаты. Результаты валидации вашей модели могут отличаться от результатов, показанных в этом примере.
Исследуйте график поля точек. X указывает на неправильно классифицированные точки. Синие точки (setosa виды) все правильно классифицированы, но два других вида имеют неправильно классифицированные точки. В разделе Plot переключитесь между опциями Data и Model predictions. Наблюдайте цвет неправильных (X) точек. Или, чтобы просмотреть только неправильные точки, снимите флажок Correct.
Обучите ядерную наивную модель Бейеса для сравнения. На вкладке Classification Learner, в разделе Model Type, нажмите Kernel Naive Bayes. Обратите внимание, что Classification Learner включает кнопку Advanced, поскольку этот тип модели имеет расширенные настройки.

Приложение отображает наивную модель Байеса ядра на панели Models.
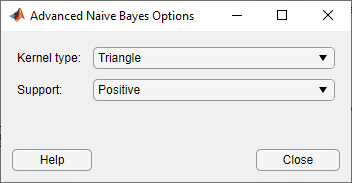
В Model Type разделе нажмите кнопку Advanced, чтобы изменить настройки в диалоговом окне Advanced Naive Bayes Options. Выберите Triangle из списка Kernel Type и выберите Positive из списка Support.
Примечание
Настройки в диалоговом окне Advanced Naive Bayes Options доступны только для непрерывных данных. Указание на Kernel Type отображает подсказку «Задайте функцию сглаживания ядра для непрерывных переменных» и указание на Support отображает подсказку «Задайте поддержку плотности сглаживания ядра для непрерывных переменных».
В Training разделе нажмите Train, чтобы обучить новую модель.
Теперь панель Models включает новую наивную модель Байеса ядра. Его счет валидации модели лучше, чем счет для Гауссовой наивной модели Байеса. Приложение подсвечивает Accuracy (Validation) счет лучшей модели, обрисовав его в кубе.
На панели Models щелкните каждую модель, чтобы просмотреть и сравнить результаты.
Обучите Гауссову наивную модель Байеса и ядерную наивную модель Байеса одновременно. На вкладке Classification Learner, в разделе Model Type, нажмите All Naive Bayes. Classification Learner отключает кнопку Advanced. В Training разделе нажмите Train.
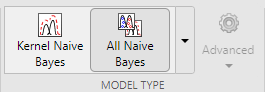
Приложение обучает один из каждого наивного типа модели Байеса и подсвечивает Accuracy (Validation) счет лучшей модели или модели.
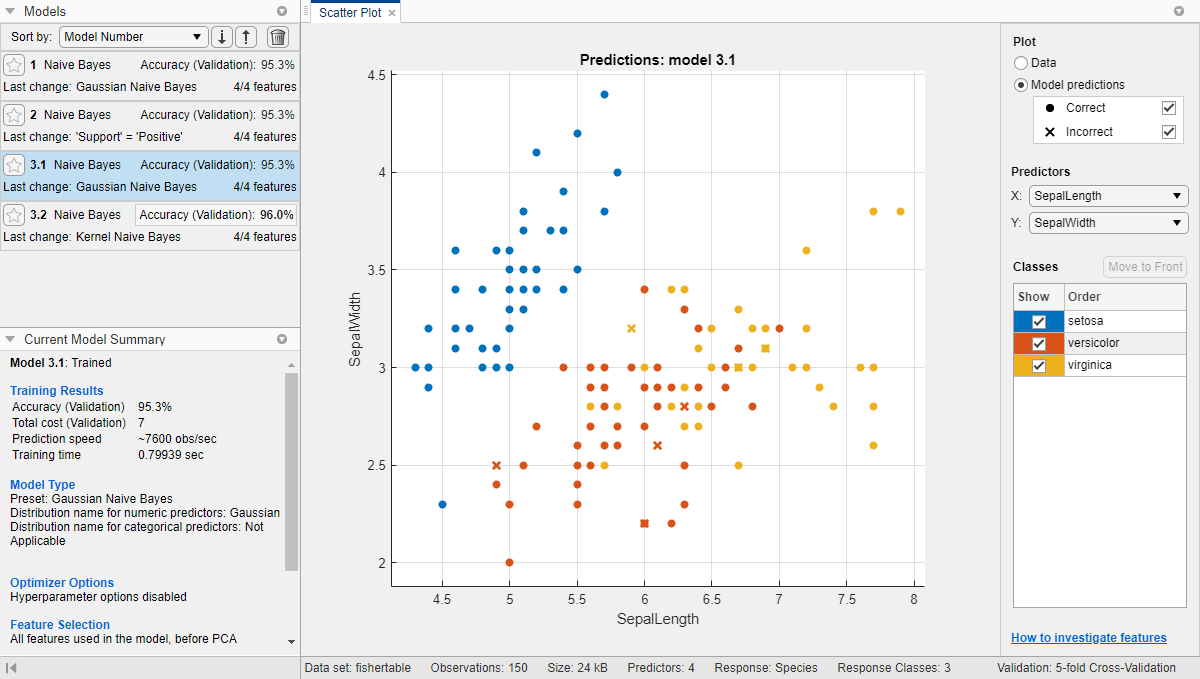
На панели Models щелкните модель, чтобы просмотреть результаты. Исследуйте график поля точек для обученной модели и попробуйте построить график различных предикторов. Неправильно классифицированные точки отображаются как X.
Чтобы проверить точность предсказаний в каждом классе, на вкладке Classification Learner, в разделе Plots, нажмите Confusion Matrix и выберите Validation Data. Приложение отображает матрицу результатов истинного класса и предсказанного класса.
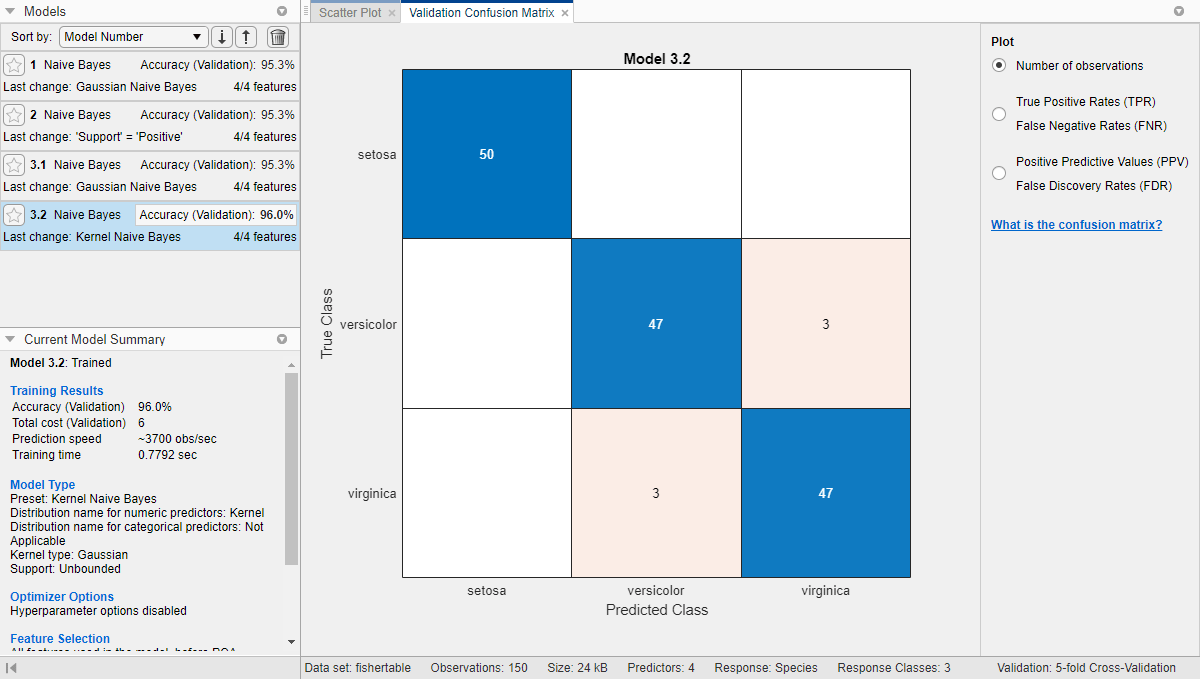
Примечание
Валидация вводит некоторую случайность в результаты. Результаты матрицы неточностей могут отличаться от результатов, показанных в этом примере.
На панели Models щелкните другие модели и сравните их результаты.
На панели Models щелкните модель с наивысшими Accuracy (Validation) счетами. Чтобы улучшить модель, попробуйте изменить ее функции. Для примера смотрите, можете ли вы улучшить модель, удалив функции с низким прогнозирующей степенью.
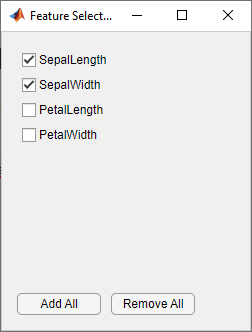
На вкладке Classification Learner, в разделе Features, нажмите Feature Selection.
В диалоговом окне Выборе признаков снимите флажки для PetalLength и PetalWidth, чтобы исключить их из предикторов. Новая модель черновика (модель 4) появляется на панели Models с новыми настройками (2/4 функции), основанными на наивной модели Байеса ядра (модель 3.2).
В разделе Training нажмите Train, чтобы обучить новую наивную модель Байеса ядра с помощью новых опций предиктора.
Панель Models теперь включает модель 4. Это также ядерная наивная модель Байеса, обученная с использованием только 2 из 4 предикторов.
Чтобы определить, какие предикторы включены, щелкните модель на панели Models, затем щелкните Feature Selection в разделе Features и отметьте, какие флажки установлены. Модель с только измерениями сепаля (модель 4) имеет намного более низкий < reservedrangesplaceholder0 > счет, чем модели, содержащие все предикторы.
Обучите другую наивную модель Байеса ядра, включая только измерения лепестка. Измените выбор в диалоговом окне Выбора признаков и нажатия кнопки Train.
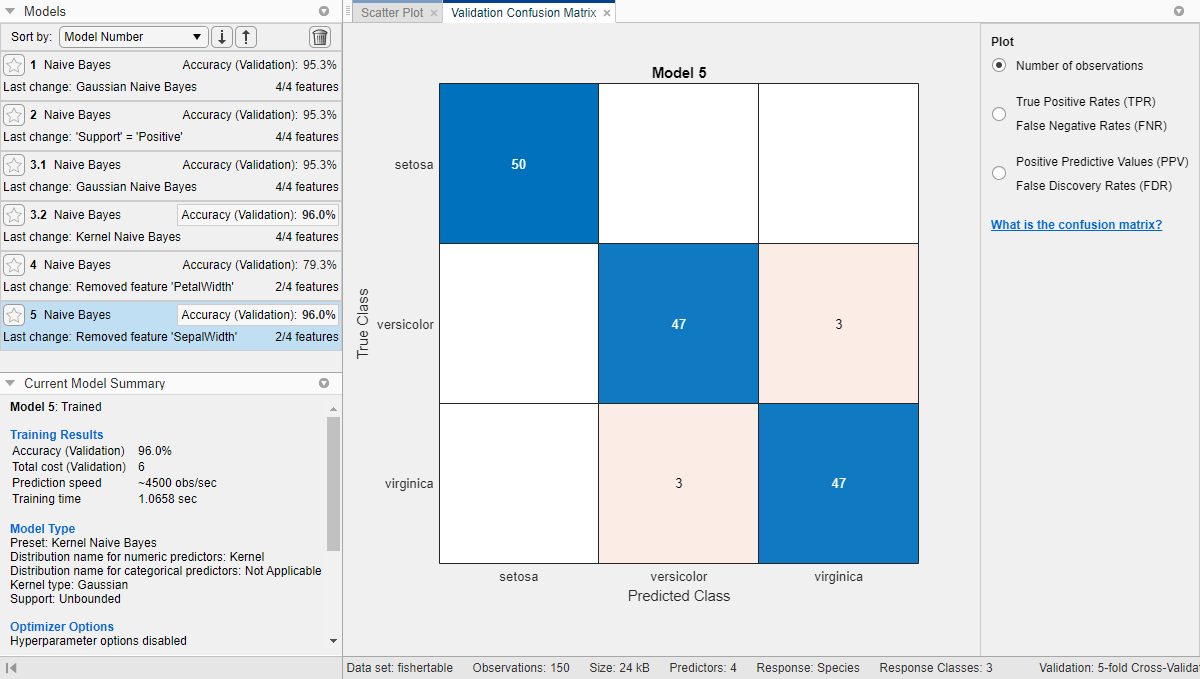
Модель, обученная с использованием только измерений лепестка (модель 5), работает сопоставимо с моделью, содержащей все предикторы. Модели предсказывают не лучше, используя все измерения по сравнению только с измерениями лепестка. Если набор данных является дорогим или трудным, вы можете предпочитать модель, которая работает удовлетворительно без некоторых предикторов.
Чтобы исследовать функции, которые нужно включить или исключить, используйте график параллельных координат. На вкладке Classification Learner, в разделе Plots, нажмите Parallel Coordinates.
На панели Models щелкните модель с наивысшими Accuracy (Validation) счетами. Чтобы улучшить модель дальше, попробуйте изменить наивные настройки Байеса (при наличии). На вкладке Classification Learner, в разделе Model Type, нажмите Advanced. Напомним, что кнопка Advanced включена только для некоторых моделей. Измените настройку, затем обучите новую модель, нажав Train.
Экспортируйте обученную модель в рабочую область. На вкладке Classification Learner, в разделе Export, выберите Export Model > Export Model. Смотрите Экспорт Классификационной модели для предсказания новых данных.
Исследуйте код для обучения этого классификатора. В Export разделе нажмите Generate Function.
Используйте тот же рабочий процесс для анализа и сравнения других типов классификаторов, которые можно обучить в Classification Learner.
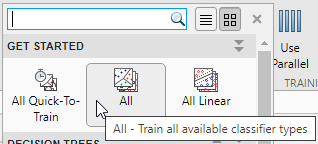
Чтобы попробовать все наборы моделей неоптимизируемых классификаторов, доступные для вашего набора данных:
Щелкните стреле на Model Type разделе, чтобы открыть коллекцию классификаторов.
В группе Get Started щелкните All, затем щелкните Train в Training разделе.
Для получения информации о других типах классификаторов смотрите Train классификационных моделей в приложении Classification Learner.
