Классификационные потери для классификатора нейронной сети
L = loss(Mdl,Tbl,ResponseVarName)Mdl использование данных предиктора в таблице Tbl и метки классов в ResponseVarName табличная переменная.
L возвращается как скалярное значение, которое представляет ошибку классификации по умолчанию.
L = loss(___,Name,Value)
Вычислите ошибку классификации тестового набора классификатора нейронной сети.
Загрузите patients набор данных. Составьте таблицу из набора данных. Каждая строка соответствует одному пациенту, и каждый столбец соответствует диагностической переменной. Используйте Smoker переменная как переменная отклика, а остальная часть переменных как предикторы.
load patients
tbl = table(Diastolic,Systolic,Gender,Height,Weight,Age,Smoker);Разделите данные на набор обучающих данных tblTrain и тестовый набор tblTest при помощи стратифицированного раздела удержания. Программа резервирует приблизительно 30% наблюдений для тестовых данных набора и использует остальную часть наблюдений для обучающего набора данных.
rng("default") % For reproducibility of the partition c = cvpartition(tbl.Smoker,"Holdout",0.30); trainingIndices = training(c); testIndices = test(c); tblTrain = tbl(trainingIndices,:); tblTest = tbl(testIndices,:);
Обучите классификатор нейронной сети с помощью набора обучающих данных. Задайте Smoker столбец tblTrain как переменная отклика. Задайте, чтобы стандартизировать числовые предикторы.
Mdl = fitcnet(tblTrain,"Smoker", ... "Standardize",true);
Вычислите ошибку классификации тестового набора. Ошибка классификации является типом потерь по умолчанию для классификаторов нейронных сетей.
testError = loss(Mdl,tblTest,"Smoker")testError = 0.0671
testAccuracy = 1 - testError
testAccuracy = 0.9329
Модель нейронной сети правильно классифицирует приблизительно 93% наблюдений тестового набора.
Выполните выбор признаков путем сравнения полей классификации тестового набора, ребер, ошибок и предсказаний. Сравните метрики тестового набора для модели, обученной с использованием всех предикторов, с метриками тестового набора для модели, обученной с использованием только подмножества предикторов.
Загрузите образец файла fisheriris.csv, который содержит данные по радужке, включая длину чашелистика, ширину чашелистика, длину лепестка, ширину лепестка и видовой тип. Считайте файл в таблицу.
fishertable = readtable('fisheriris.csv');Разделите данные на набор обучающих данных trainTbl и тестовый набор testTbl при помощи стратифицированного раздела удержания. Программа резервирует приблизительно 30% наблюдений для тестовых данных набора и использует остальную часть наблюдений для обучающего набора данных.
rng("default") c = cvpartition(fishertable.Species,"Holdout",0.3); trainTbl = fishertable(training(c),:); testTbl = fishertable(test(c),:);
Обучите один классификатор нейронной сети, используя все предикторы в наборе обучающих данных, и обучите другой классификатор, используя все предикторы, кроме PetalWidth. Для обеих моделей задайте Species как переменная отклика и стандартизируйте предикторы.
allMdl = fitcnet(trainTbl,"Species","Standardize",true); subsetMdl = fitcnet(trainTbl,"Species ~ SepalLength + SepalWidth + PetalLength", ... "Standardize",true);
Вычислите поля классификации тестового набора для двух моделей. Поскольку тестовый набор включает только 45 наблюдений, отобразите поля с помощью гистограмм.
Для каждого наблюдения классификационный запас является различием между классификационной оценкой для истинного класса и максимальным счетом для ложных классов. Поскольку классификаторы нейронных сетей возвращают классификационные оценки, которые являются апостериорными вероятностями, значения полей, близкие к 1, указывают на уверенные классификации, а отрицательные значения полей указывают на неправильную классификацию.
tiledlayout(2,1) % Top axes ax1 = nexttile; allMargins = margin(allMdl,testTbl); bar(ax1,allMargins) xlabel(ax1,"Observation") ylabel(ax1,"Margin") title(ax1,"All Predictors") % Bottom axes ax2 = nexttile; subsetMargins = margin(subsetMdl,testTbl); bar(ax2,subsetMargins) xlabel(ax2,"Observation") ylabel(ax2,"Margin") title(ax2,"Subset of Predictors")

Сравните ребро классификации тестового набора или среднее значение классификационных полей двух моделей.
allEdge = edge(allMdl,testTbl)
allEdge = 0.8198
subsetEdge = edge(subsetMdl,testTbl)
subsetEdge = 0.9556
Основываясь на полях классификации тестового набора и ребрах, модель, обученная на подмножестве предикторов, по-видимому, превосходит модель, обученную на всех предикторах.
Сравните ошибку классификации тестового набора двух моделей.
allError = loss(allMdl,testTbl); allAccuracy = 1-allError
allAccuracy = 0.9111
subsetError = loss(subsetMdl,testTbl); subsetAccuracy = 1-subsetError
subsetAccuracy = 0.9778
Снова, модель, обученная с использованием только подмножества предикторов, кажется, работает лучше, чем модель, обученная с использованием всех предикторов.
Визуализируйте результаты классификации тестового набора с помощью матриц неточностей.
allLabels = predict(allMdl,testTbl);
figure
confusionchart(testTbl.Species,allLabels)
title("All Predictors")
subsetLabels = predict(subsetMdl,testTbl);
figure
confusionchart(testTbl.Species,subsetLabels)
title("Subset of Predictors")
Модель, обученная с использованием всех предикторов, неправильно классифицирует четыре наблюдения набора тестов. Модель, обученная с использованием подмножества предикторов, неправильно классифицирует только одно из наблюдений тестового набора.
Учитывая эффективность тестового набора двух моделей, рассмотрите использование модели, обученной с использованием всех предикторов, кроме PetalWidth.
Classification loss функции измеряют прогнозирующую неточность классификационных моделей. Когда вы сравниваете один и тот же тип потерь среди многих моделей, более низкая потеря указывает на лучшую прогнозирующую модель.
Рассмотрим следующий сценарий.
L - средневзвешенные классификационные потери.
n - размер выборки.
Для двоичной классификации:
yj - наблюдаемая метка класса. Программное обеспечение кодирует его как -1 или 1, указывая на отрицательный или положительный класс (или первый или второй класс в ClassNames свойство), соответственно.
f (Xj) является баллом классификации положительного класса для j наблюдений (строка) X данных предиктора.
mj = yj f (Xj) является классификационной оценкой для классификации j наблюдений в класс, относящийся к yj. Положительные значения mj указывают на правильную классификацию и не вносят большой вклад в средние потери. Отрицательные значения mj указывают на неправильную классификацию и вносят значительный вклад в среднюю потерю.
Для алгоритмов, которые поддерживают многоклассовую классификацию (то есть K ≥ 3):
yj* - вектор с K - 1 нулями, с 1 в положении, соответствующем истинному, наблюдаемому классу yj. Для примера, если истинный класс второго наблюдения является третьим классом и K = 4, то y 2* = [0 0 1 0]′. Порядок классов соответствует порядку в ClassNames свойство модели входа.
f (Xj) является вектором K длины счетов классов для j наблюдений X данных предиктора. Порядок счетов соответствует порядку классов в ClassNames свойство модели входа.
mj = yj*′ f (<reservedrangesplaceholder1>). Поэтому mj является скалярной классификационной оценкой, которую модель предсказывает для истинного наблюдаемого класса.
Вес для j наблюдения wj. Программа нормализует веса наблюдений так, чтобы они суммировались с соответствующей вероятностью предыдущего класса. Программное обеспечение также нормализует предыдущие вероятности, поэтому они равны 1. Поэтому,
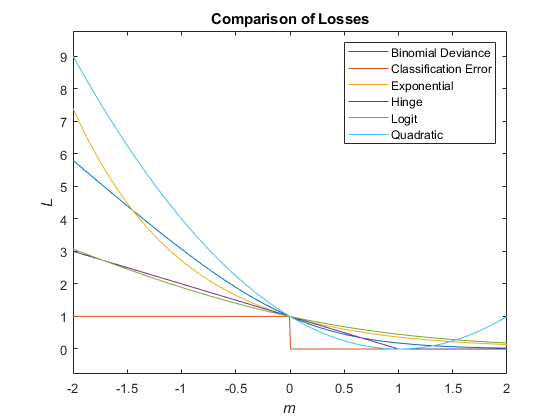
С учетом этого сценария в следующей таблице описываются поддерживаемые функции потерь, которые можно задать при помощи 'LossFun' аргумент пары "имя-значение".
| Функция потерь | Значение LossFun | Уравнение |
|---|---|---|
| Биномиальное отклонение | 'binodeviance' | |
| Неверно классифицированный коэффициент в десятичных числах | 'classiferror' | - метка класса, соответствующая классу с максимальным счетом. I {·} является функцией индикации. |
| Потери перекрестной энтропии | 'crossentropy' |
Взвешенные потери перекрестной энтропии где веса нормированы в сумме к n вместо 1. |
| Экспоненциальные потери | 'exponential' | |
| Потеря шарнира | 'hinge' | |
| Логит потеря | 'logit' | |
| Минимальные ожидаемые затраты на неправильную классификацию | 'mincost' |
Программа вычисляет взвешенные минимальные ожидаемые затраты классификации, используя эту процедуру для наблюдений j = 1,..., n.
Взвешенное среднее значение минимальных ожидаемых потерь от неправильной классификации Если вы используете матрицу затрат по умолчанию (значение элемента которой 0 для правильной классификации и 1 для неправильной классификации), то |
| Квадратичные потери | 'quadratic' |
Этот рисунок сравнивает функции потерь (кроме 'crossentropy' и 'mincost') по счету m для одного наблюдения. Некоторые функции нормированы, чтобы пройти через точку (0,1).
ClassificationNeuralNetwork | CompactClassificationNeuralNetwork | edge | fitcnet | margin | predict
