В этом примере показано, как соответствовать обобщенной модели линейных смешанных эффектов (GLME) для выборочных данных.
Загрузите выборочные данные.
load mfr
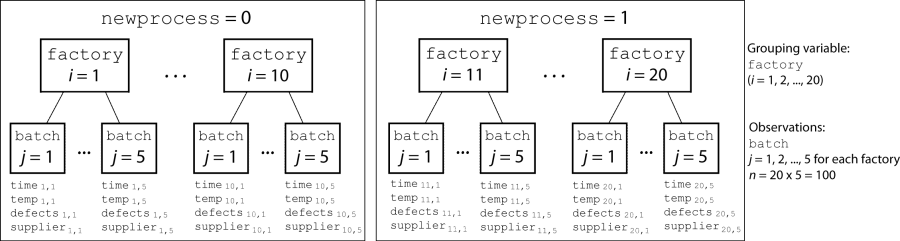
Производственная компания управляет 50 заводами по всему миру, и каждый запускает пакетный процесс для создания готового продукта. Компания хочет уменьшить количество дефектов в каждой партии, поэтому разработала новый производственный процесс. Однако компания хочет протестировать новый процесс на отдельных заводах, чтобы убедиться, что он эффективен, прежде чем распространять его на все 50 местоположений.
Чтобы проверить, значительно ли новый процесс уменьшает количество дефектов в каждой партии, компания выбрала 20 своих заводов наугад для участия в эксперименте. Десять заводов реализовали новый процесс, а другие десять использовали старый процесс.
На каждом из 20 заводов (i = 1, 2,..., 20) компания провела пять партий (j = 1, 2,..., 5) и записала следующие данные в таблицу mfr:
Флаг для указания использования нового процесса:
Если пакет использовал новый процесс, то newprocess = 1
Если пакет использовал старый процесс, то newprocess = 0
Время вычислений партии, в часах (time)
Температура партии, в степенях Цельсия (temp)
Поставщик химического вещества, используемого в партии (supplier)
supplier - категориальная переменная с уровнями A, B, и C, где каждый уровень представляет одного из трех поставщиков
Количество дефектов в партии (дефекты)
Данные также включают time_dev и temp_dev, которые представляют абсолютное отклонение времени и температуры, соответственно, от стандарта процесса 3 часов и 20 степеней Цельсия. Переменная отклика defects имеет распределение Пуассона. Это моделируемые данные.
Компания хочет определить, существенно ли новый процесс уменьшает количество дефектов в каждой партии, с учетом различий в качестве, которые могут существовать из-за специфических для завода изменений во времени, температуре и поставщике. Количество дефектов на партию может быть смоделировано с помощью распределения Poison:
Используйте обобщенную модель линейных смешанных эффектов, чтобы смоделировать количество дефектов на партию:
где
defectsij - количество дефектов, наблюдаемых в партии, произведенной заводскими i во время j партии.
μij - среднее количество дефектов, соответствующих заводским i (где i = 1, 2,..., 20) во время пакетной j (где j = 1, 2,..., 5).
newprocessij, time_devij и temp_devij являются измерениями для каждой переменной, которые соответствуют заводским i во время пакетной j. Например, newprocessij указывает, использовался ли новый процесс в партии, произведенной заводскими i во время j партии.
supplier_Cij и supplier_Bij являются фиктивными переменными, которые используют эффекты (сумма к нулю) кодирования, чтобы указать, C ли компания или B, соответственно, поставляла химикаты для партии, произведенной заводским i во время j партии.
bi ~ N (0, σb2) является точка пересечения случайных эффектов для каждого производственного i, которая учитывает специфическое для завода изменение качества.
Подбор обобщенной линейной модели смешанных эффектов с помощью newprocess, time_dev, temp_dev, и supplier как предикторы фиксированных эффектов. Включите термин случайных эффектов для точки пересечения, сгруппированного по factory, для расчета различий в качестве, которые могут существовать из-за специфичных для фабрики изменений. Переменная отклика defects имеет распределение Пуассона, и соответствующая функция ссылки для этой модели является логарифмической. Используйте метод Laplace fit, чтобы оценить коэффициенты. Задайте кодировку фиктивной переменной следующим 'effects', поэтому фиктивные переменные коэффициенты равны 0.
glme = fitglme(mfr,... 'defects ~ 1 + newprocess + time_dev + temp_dev + supplier + (1|factory)',... 'Distribution','Poisson','Link','log','FitMethod','Laplace',... 'DummyVarCoding','effects')
glme =
Generalized linear mixed-effects model fit by ML
Model information:
Number of observations 100
Fixed effects coefficients 6
Random effects coefficients 20
Covariance parameters 1
Distribution Poisson
Link Log
FitMethod Laplace
Formula:
defects ~ 1 + newprocess + time_dev + temp_dev + supplier + (1 | factory)
Model fit statistics:
AIC BIC LogLikelihood Deviance
416.35 434.58 -201.17 402.35
Fixed effects coefficients (95% CIs):
Name Estimate SE tStat DF pValue
'(Intercept)' 1.4689 0.15988 9.1875 94 9.8194e-15
'newprocess' -0.36766 0.17755 -2.0708 94 0.041122
'time_dev' -0.094521 0.82849 -0.11409 94 0.90941
'temp_dev' -0.28317 0.9617 -0.29444 94 0.76907
'supplier_C' -0.071868 0.078024 -0.9211 94 0.35936
'supplier_B' 0.071072 0.07739 0.91836 94 0.36078
Lower Upper
1.1515 1.7864
-0.72019 -0.015134
-1.7395 1.5505
-2.1926 1.6263
-0.22679 0.083051
-0.082588 0.22473
Random effects covariance parameters:
Group: factory (20 Levels)
Name1 Name2 Type Estimate
'(Intercept)' '(Intercept)' 'std' 0.31381
Group: Error
Name Estimate
'sqrt(Dispersion)' 1 The Model information таблица отображает общее количество наблюдений в выборочных данных (100), количество коэффициентов фиксированных и случайных эффектов (6 и 20, соответственно) и количество ковариационных параметров (1). Это также указывает, что переменная отклика имеет Poisson распределение, функция ссылки Log, и метод подгонки Laplace.
Formula указывает спецификацию модели, использующую обозначение Уилкинсона.
The Model fit statistics таблица отображает статистику, используемую для оценки качества подгонки модели. Это включает информационный критерий Акаике (AIC), байесовский информационный критерий (BIC) значения, журнал правдоподобия (LogLikelihood), и отклонение (Deviance) значения.
The Fixed effects coefficients таблица указывает, что fitglme возвращено 95% доверительных интервалов. Он содержит одну строку для каждого предиктора фиксированных эффектов, и каждый столбец содержит статистику, соответствующую этому предиктору. Столбец 1 (Name) содержит имя каждого коэффициента с фиксированными эффектами, столбец 2 (Estimate) содержит его расчетное значение и столбец 3 (SE) содержит стандартную ошибку коэффициента. Столбец 4 (tStat) содержит t -статистическую для проверки гипотезы, что коэффициент равен 0. Столбец 5 (DF) и столбец 6 (pValue) содержат степени свободы и p -значение, которые соответствуют t -statistic, соответственно. Последние два столбца (Lower и Upper) отображать нижний и верхний пределы, соответственно, 95% доверительного интервала для каждого коэффициента фиксированных эффектов.
Random effects covariance parameters отображает таблицу для каждой сгруппированной переменной (только здесь factory), включая его общее количество уровней (20), и тип и оценку ковариационного параметра. Здесь, std указывает, что fitglme возвращает стандартное отклонение случайного эффекта, сопоставленного с заводским предиктором, которое имеет оценочное значение 0,31381. В нем также отображается таблица, содержащая тип параметра ошибки (здесь квадратный корень параметра дисперсии) и его предполагаемое значение 1.
Стандартное отображение, сгенерированное fitglme не предоставляет доверительные интервалы для параметров случайных эффектов. Чтобы вычислить и отобразить эти значения, используйте covarianceParameters.
Чтобы определить, является ли точка пересечения случайных эффектов сгруппированным по factory является статистически значимым, вычислите доверительные интервалы для предполагаемого ковариационного параметра.
[psi,dispersion,stats] = covarianceParameters(glme);
covarianceParameters возвращает предполагаемый ковариационный параметр в psi, расчетный параметр дисперсии dispersionи массив ячеек связанной статистики stats. Первая камера stats содержит статистику для factory, в то время как вторая камера содержит статистику для параметра дисперсии.
Отображение первой камеры stats чтобы увидеть доверительные интервалы для предполагаемого ковариационного параметра для factory.
stats{1}ans =
Covariance Type: Isotropic
Group Name1 Name2 Type
factory '(Intercept)' '(Intercept)' 'std'
Estimate Lower Upper
0.31381 0.19253 0.51148Столбцы Lower и Upper отобразить интервал 95% доверия по умолчанию для предполагаемого параметра ковариации для factory. Поскольку интервал [0,19253,0.51148] не содержит 0, точка пересечения случайных эффектов значим на уровне значимости 5%. Поэтому случайный эффект, вызванный специфичными для завода изменениями, должен быть рассмотрен, прежде чем делать какие-либо выводы об эффективности нового производственного процесса.
Сравните модель смешанных эффектов, которая включает в себя точку пересечения случайных эффектов, сгруппированный по factory с моделью, которая не включает случайный эффект, чтобы определить, какая модель является лучшей подгонкой для данных. Подгонка первой модели, FEglme, используя только предикторы фиксированных эффектов newprocess, time_dev, temp_dev, и supplier. Подгонка второй модели, glme, используя эти же предикторы фиксированных эффектов, но также включая точку пересечения случайных эффектов, сгруппированный по factory.
FEglme = fitglme(mfr,... 'defects ~ 1 + newprocess + time_dev + temp_dev + supplier',... 'Distribution','Poisson','Link','log','FitMethod','Laplace'); glme = fitglme(mfr,... 'defects ~ 1 + newprocess + time_dev + temp_dev + supplier + (1|factory)',... 'Distribution','Poisson','Link','log','FitMethod','Laplace');
Сравните две модели с помощью теста коэффициента правдоподобия. Задайте 'CheckNesting' как true, так compare возвращает предупреждение, если требования к вложенности не удовлетворены.
results = compare(FEglme,glme,'CheckNesting',true)
results =
Theoretical Likelihood Ratio Test
Model DF AIC BIC LogLik LRStat deltaDF
FEglme 6 431.02 446.65 -209.51
glme 7 416.35 434.58 -201.17 16.672 1
pValue
4.4435e-05compare возвращает степени свободы (DF), информационный критерий Акаике (AIC), байесовский информационный критерий (BIC) и журнал значений правдоподобия для каждой модели. glme имеет меньшие значения вероятностей AIC, BIC и журнал, чем FEglme, что указывает на то, что glme (модель, содержащая термин «случайные эффекты» для точки пересечения, сгруппированного по фабрикам), является более подходящей моделью для этих данных. Кроме того, значение small p -value указывает, что compare отклоняет нулевую гипотезу о том, что вектор отклика был сгенерирован моделью только фиксированных эффектов FEglme, в пользу альтернативы, что вектор отклика был сгенерирован моделью смешанных эффектов glme.
Сгенерируйте подобранные условные средние значения для модели.
mufit = fitted(glme);
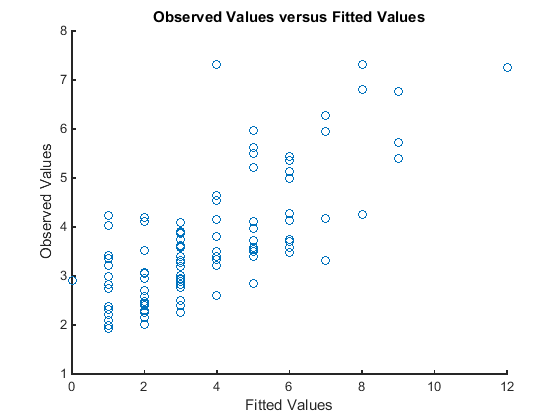
Постройте график наблюдаемых значений отклика от установленных значений отклика.
figure scatter(mfr.defects,mufit) title('Observed Values versus Fitted Values') xlabel('Fitted Values') ylabel('Observed Values')
Создайте диагностические графики с помощью условных невязок Пирсона для экспериментальной модели допущений. Поскольку необработанные невязки для обобщенных моделей линейных смешанных эффектов не имеют постоянного отклонения между наблюдениями, используйте вместо этого условные невязки Пирсона.
Постройте гистограмму, чтобы визуально подтвердить, что среднее значение невязок Пирсона равно 0. Если модель верна, мы ожидаем, что невязки Пирсона будут центрироваться на 0.
plotResiduals(glme,'histogram','ResidualType','Pearson')
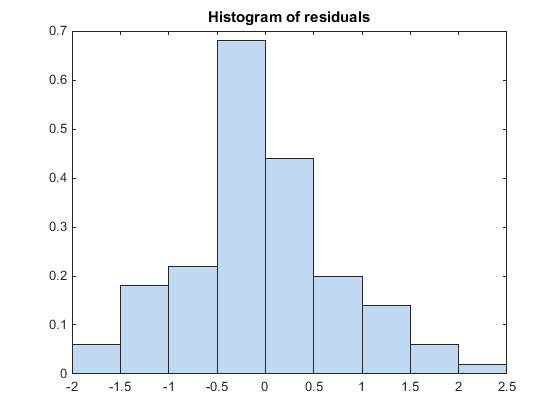
Гистограмма показывает, что невязки Пирсона центрированы при 0.
Постройте график невязок Пирсона по сравнению с установленными значениями, чтобы проверить признаки неконстантного отклонения среди невязок (гетероскедастичность). Мы ожидаем, что условные невязки Пирсона будут иметь постоянное отклонение. Поэтому график условных невязок Пирсона от условных подобранных значений не должен выявлять никакой систематической зависимости от условных подобранных значений.
plotResiduals(glme,'fitted','ResidualType','Pearson')
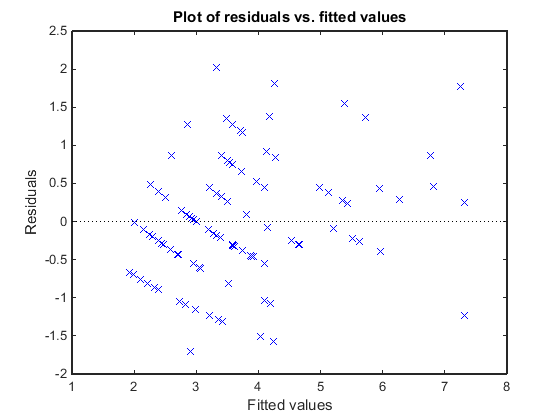
График не показывает систематической зависимости от подобранных значений, поэтому нет признаков неконстантного отклонения среди невязок.
Постройте график невязок Пирсона от отстающих остатков, чтобы проверить корреляцию среди невязок. Условное предположение независимости в GLME подразумевает, что условные невязки Пирсона примерно некоррелированы.
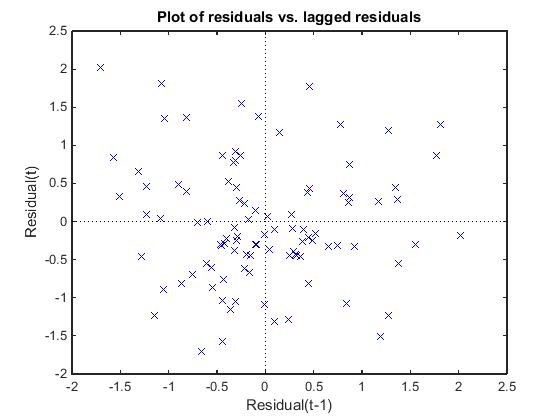
Шаблона к графику нет, поэтому признаков корреляции среди невязок нет.
fitglme | GeneralizedLinearMixedModel
