Класс: RegressionGP
Перекрестная валидация модели регрессии Гауссова процесса
cvMdl = crossval(gprMdl)
cvmdl = crossval(gprMdl,Name,Value)
cvMdl = crossval(gprMdl)cvMdl, созданный из модели регрессии Гауссова процесса (GPR), gprMdl, с использованием 10-кратной перекрестной валидации.
cvmdl является RegressionPartitionedModel объект, и gprMdl является RegressionGP (полный) объект.
cvmdl = crossval(gprMdl,Name,Value)cvmdl, с дополнительными опциями, заданными одним или несколькими Name,Value аргументы в виде пар. Для примера можно задать количество складок или долю данных, которые будут использоваться для проверки.
Загрузите данные корпуса [1] из репозитория машинного обучения UCI [4].
Набор данных имеет 506 наблюдений. Первые 13 столбцов содержат значения предиктора, а последний - значения отклика. Цель состоит в том, чтобы предсказать медианное значение домов, занятых владельцами в пригородном Бостоне, как функцию 13 предикторов.
Загрузите данные и задайте вектор отклика и матрицу предиктора.
load('housing.data');
X = housing(:,1:13);
y = housing(:,end);
Подгонка модели GPR с использованием квадратной экспоненциальной функции ядра с отдельной шкалой длины для каждого предиктора. Стандартизируйте переменные предиктора.
gprMdl = fitrgp(X,y,'KernelFunction','ardsquaredexponential','Standardize',1);
Создайте раздел перекрестной проверки для данных, используя предиктор 4 в качестве сгруппированной переменной.
rng('default') % For reproducibility cvp = cvpartition(X(:,4),'kfold',10);
Создайте 10-кратную перекрестную модель с использованием секционированных данных в cvp.
cvgprMdl = crossval(gprMdl,'CVPartition',cvp);
Вычислите регрессионые потери для кратных наблюдений с помощью моделей, обученных для несовпадающих наблюдений.
L = kfoldLoss(cvgprMdl)
L =
9.5299Предсказать ответ для кратных наблюдений, то есть наблюдений, не используемых для обучения.
ypred = kfoldPredict(cvgprMdl);
Для каждой складки, kfoldPredict предсказывает ответы на наблюдения в этой складке, используя модели, настроенные на несвойственных наблюдениях.
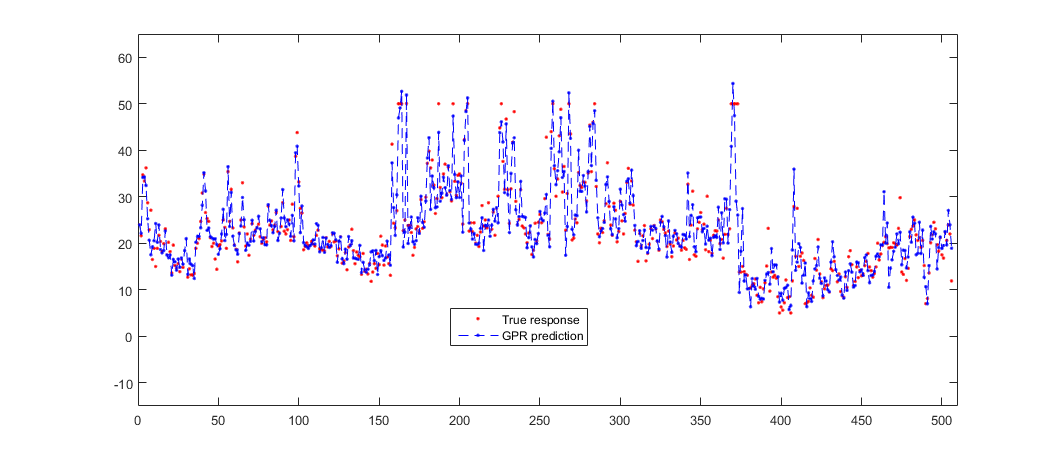
Постройте график фактических откликов и данных предсказания.
plot(y,'r.'); hold on; plot(ypred,'b--.'); axis([0 510 -15 65]); legend('True response','GPR prediction','Location','Best'); hold off;
Загрузите данные abalone [2], [3] из репозитория машинного обучения UCI [4] и сохраните их в текущей директории с именем abalone.data.
Считайте данные в table.
tbl = readtable('abalone.data','Filetype','text','ReadVariableNames',false);
Набор данных имеет 4177 наблюдений. Цель состоит в том, чтобы предсказать возраст абалона из 8 физических измерений.
Подгонка модели GPR с использованием подмножества регрессоров (sr) метод для оценки параметра и полностью независимый условный (fic) метод для предсказания. Стандартизируйте предикторы и используйте квадратную экспоненциальную функцию ядра с отдельной шкалой длины для каждого предиктора.
gprMdl = fitrgp(tbl,tbl(:,end),'KernelFunction','ardsquaredexponential',... 'FitMethod','sr','PredictMethod','fic','Standardize',1);
Перекрестная валидация модели с помощью 4-кратной перекрестной валидации. Это разделяет данные на 4 набора. Для каждого набора, fitrgp использует этот набор (25% данных) в качестве тестовых данных и обучает модель на остальных 3 наборах (75% данных).
rng('default') % For reproducibility cvgprMdl = crossval(gprMdl,'KFold',4);
Вычислите потери по отдельным складкам.
L = kfoldLoss(cvgprMdl,'mode','individual')
L =
4.3669
4.6896
4.0565
4.3162Вычислите средние кросс-проверенные потери по всем складкам. По умолчанию это средняя квадратичная невязка.
L2 = kfoldLoss(cvgprMdl)
L2 =
4.3573
Это равно средней потере по отдельным складкам.
mse = mean(L)
mse =
4.3573
Одновременно можно использовать только один из аргументов пары "имя-значение".
Вы не можете вычислить интервалы предсказания для перекрестно проверенной модели.
Кроме того, можно обучить перекрестно проверенную модель, используя связанные аргументы пары "имя-значение" в fitrgp.
Если вы поставляете пользовательский 'ActiveSet' в вызове на fitrgp, тогда вы не можете пересечь проверку модели GPR.
[1] Харрисон, Д. и Д. Л., Рубинфельд. «Гедонические цены и спрос на чистый воздух». Дж. Энвирон. Экономика и менеджмент. Vol.5, 1978, с. 81-102.
[2] Нэш, У. Дж., Т. Л. Селлерс, С. Р. Тальбот, А. Дж. Коуторн и У. Б. Форд. "Популяционная биология Абалоне (виды Haliotis) в Тасмании. I. Blacklip Abalone (H. rubra) с Северного побережья и островов пролива Басс ". Деление морского рыболовства, технический доклад № 48, 1994 год.
[3] Waugh, S. «Extending and Benchmarking Cascade-Correlation: Extensions to the Cascade-Correlation Architecture and Benchmarking of Feed-Forward Supervied Neural Networds». Тасманийский университет, кафедра компьютерных наук, 1995 год.
[4] Лихман, M. UCI Machine Learning Repository, Irvine, CA: University of California, School of Information and Computer Science, 2013. http://archive.ics.uci.edu/ml.
fitrgp | kfoldLoss | kfoldPredict | RegressionGP | RegressionPartitionedModel
