В этом примере показано, как создать и сравнить различные деревья классификации с помощью Classification Learner и экспортировать обученные модели в рабочую область, чтобы делать предсказания для новых данных.
Можно обучить деревья классификации прогнозировать ответы на данные. Чтобы предсказать ответ, следуйте решениям в дереве от корневого (начального) узла до узла листа. Узел листа содержит ответ.
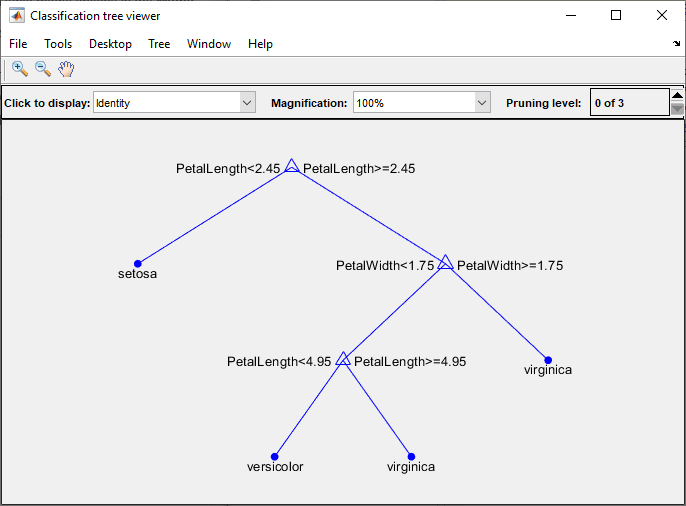
Statistics and Machine Learning Toolbox™ деревьев являются двоичными. Каждый шаг в предсказании включает проверку значения одного предиктора (переменной). Например, вот простое дерево классификации:
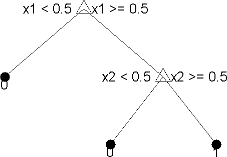
Это дерево предсказывает классификации на основе двух предикторов, x1 и x2. Чтобы предсказать, начните с верхнего узла. При каждом решении проверяйте значения предикторов, чтобы решить, какой ветви следовать. Когда ветви достигают конечного узла, данные классифицируются как тип 0 или 1.
В MATLAB®, загрузите fisheriris набор данных и создайте таблицу предикторов измерений (или функций), используя переменные из набора данных для использования в классификации.
fishertable = readtable('fisheriris.csv');На вкладке Apps, в группе Machine Learning and Deep Learning, нажмите Classification Learner.
На вкладке Classification Learner, в разделе File, нажмите New Session > From Workspace.

В диалоговом окне Новый сеанс из рабочей области выберите таблицу fishertable из Data Set Variable списка (при необходимости).
Заметьте, что приложение выбрало переменные отклика и предиктора на основе их типа данных. Длина и ширина лепестка и сепаля являются предикторами, а виды - это реакция, которую вы хотите классифицировать. В данном примере не изменяйте выбор.
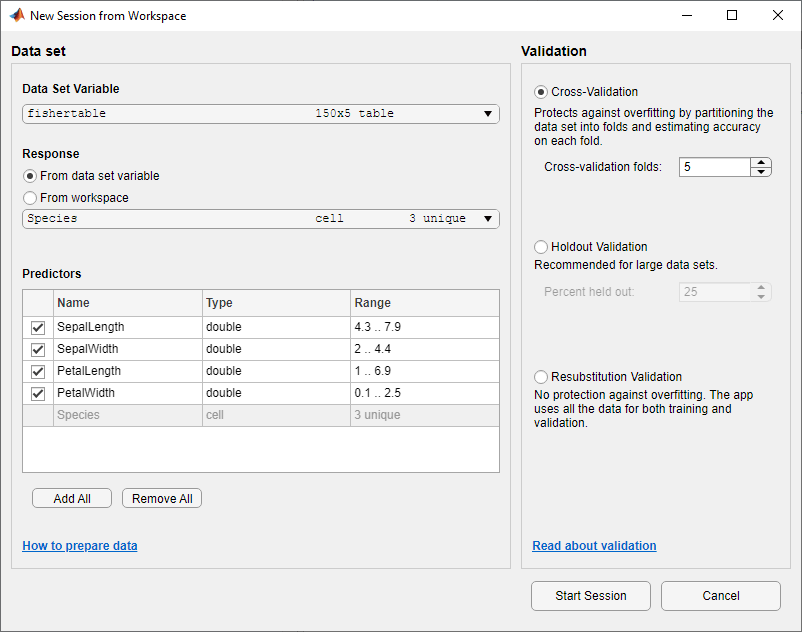
Чтобы принять схему валидации по умолчанию и продолжить, нажмите Start Session. Опция валидации по умолчанию является перекрестной валидацией, чтобы защитить от сверхподбора кривой.
Classification Learner создает график поля точек данных.
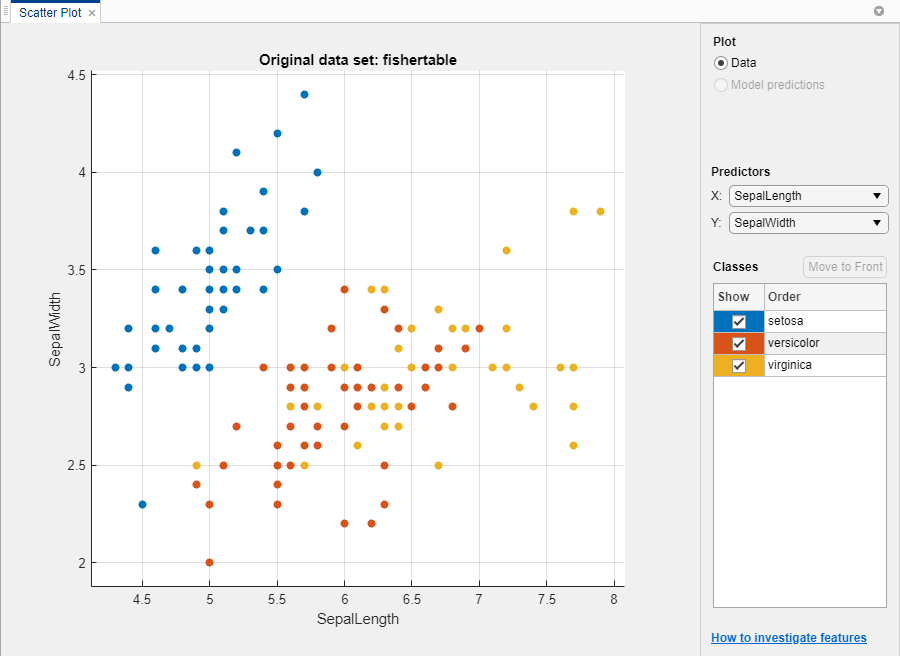
Используйте график поля точек, чтобы выяснить, какие переменные полезны для предсказания отклика. Выберите различные опции в списках X и Y под Predictors, чтобы визуализировать распределение видов и измерений. Наблюдайте, какие переменные разделяют цвета видов наиболее четко.
Заметьте, что setosa вид (синие точки) легко отделить от двух других видов со всеми четырьмя предикторами. The versicolor и virginica виды намного ближе друг к другу во всех предикторных измерениях и перекрываются, особенно когда вы строите график длины и ширины чашелистика. setosa легче предсказать, чем два других вида.
Чтобы создать модель дерева классификации, на вкладке Classification Learner, в разделе Model Type, щелкните стреле вниз, чтобы развернуть галерею и нажмите Coarse Tree. Затем нажмите Train.
Приложение создает простое дерево классификации и строит графики результатов.
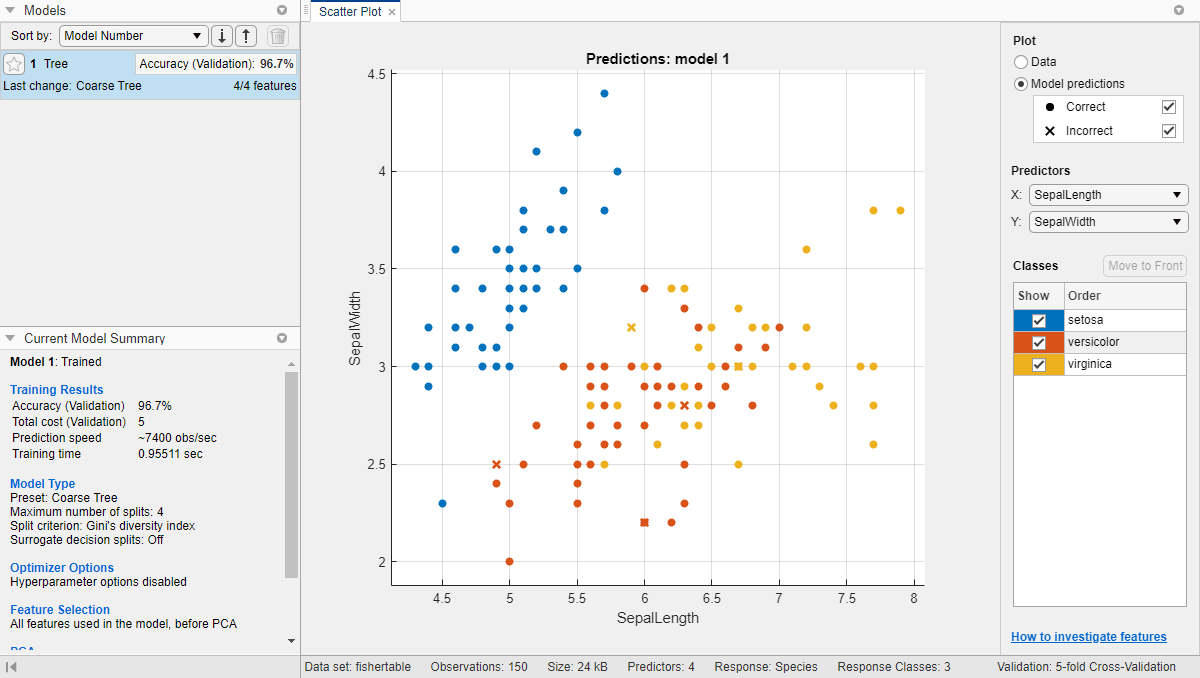
Наблюдайте модель Coarse Tree на панели Models. Проверьте счет валидации модели в Accuracy (Validation) окне. Модель показала себя хорошо.
Примечание
С валидацией в результатах есть некоторая случайность, поэтому результаты счета валидации вашей модели могут отличаться от показанных.
Исследуйте график поля точек. X указывает на неправильно классифицированные точки. Синие точки (setosa виды) все правильно классифицированы, но некоторые из двух других видов неправильно классифицированы. В разделе Plot переключитесь между опциями Data и Model Predictions. Наблюдайте цвет неправильных (X) точек. Кроме того, при построении графиков предсказаний модели, чтобы просмотреть только неправильные точки, снимите флажок Correct.
Обучите другую модель для сравнения. Нажмите Medium Tree, а затем нажмите Train.
При нажатии кнопки Train приложение отображает новую модель на панели Models.
Наблюдайте модель Medium Tree на панели Models. Счет валидации модели ничем не лучше грубого древовидного счета. Приложение обрисовывает в кубе Accuracy (Validation) счет лучшей модели. Щелкните каждую модель на панели Models, чтобы просмотреть и сравнить результаты.
Исследуйте график поля точек для модели Medium Tree. Среднее дерево правильно классифицирует столько точек, сколько предыдущее крупное дерево. Вы хотите избежать избыточной подгонки, и крупное дерево работает хорошо, поэтому основывайте все дальнейшие модели на крупном дереве.
Выберите Coarse Tree на панели Models. Чтобы попытаться улучшить модель, попробуйте включить различные функции в модель. Посмотрите, можно ли улучшить модель, удалив функции с низкой прогностической степенью.
На вкладке Classification Learner, в разделе Features, нажмите Feature Selection.
В диалоговом окне Выборе признаков снимите флажки для PetalLength и PetalWidth, чтобы исключить их из предикторов. Новая модель черновика появится на панели Models с новыми настройками 2/4 функций, основанными на крупном дереве.
Щелкните Train, чтобы обучить новую модель дерева с помощью новых опций предиктора.
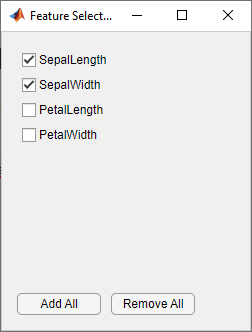
Наблюдайте третью модель на панели Models. Это также Coarse Tree модель, обученная с использованием только 2 из 4 предикторов. Приложение отображает, сколько предикторов исключено. Чтобы проверить, какие предикторы включены, щелкните модель на панели Models и наблюдайте флажки в диалоговом окне Выбора признаков. Модель с только измерениями сепаля имеет гораздо более низкий счет точности, чем модель только для лепестков.
Обучите другую модель, включая только измерения лепестков. Измените выбор в диалоговом окне Выбора признаков и нажатия кнопки Train.
Модель, обученная с использованием только измерений лепестка, работает сопоставимо с моделями, содержащими все предикторы. Модели предсказывают не лучше, используя все измерения по сравнению только с измерениями лепестка. Если набор данных является дорогим или трудным, вы можете предпочитать модель, которая работает удовлетворительно без некоторых предикторов.
Повторите, чтобы обучить еще две модели, включая только измерения ширины и затем измерения длины. Между несколькими моделями нет большого различия в счетах.
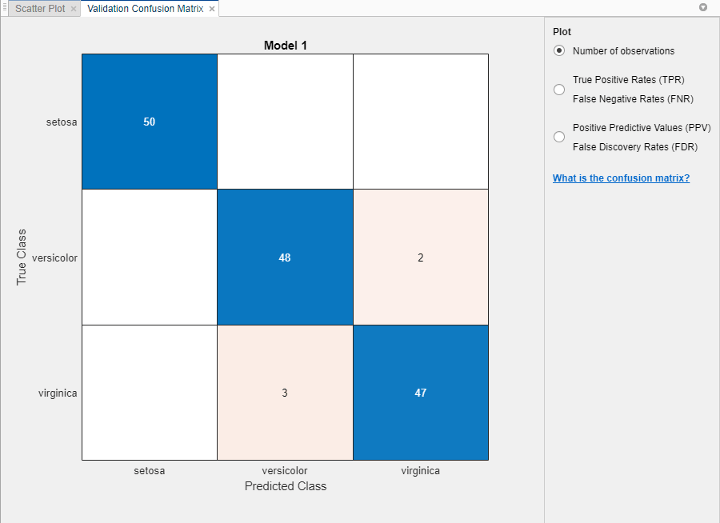
Выберите лучшую модель среди моделей с аналогичными счетами путем изучения эффективности в каждом классе. Выберите крупное дерево, которое включает все предикторы. Чтобы проверить точность предсказаний в каждом классе, на вкладке Classification Learner, в разделе Plots, нажмите Confusion Matrix и выберите Validation Data. Используйте этот график, чтобы понять, как в настоящее время выбранный классификатор выполняется в каждом классе. Просмотрите матрицу результатов истинного класса и предсказанного класса.
Проверьте области, где классификатор выполнял плохо, исследуя камеры вне диагонали, которые отображают высокие числа и красные. В этих красных камерах истинный класс и предсказанный класс не совпадают. Точки данных неправильно классифицируются.
Примечание
С валидацией в результатах есть некоторая случайность, поэтому результаты матрицы неточностей могут отличаться от показанных.
На этом рисунке исследуйте третью камеру в среднем строке. В этой камере истинный класс versicolor, но модель неправильно классифицировала точки как virginica. Для этой модели в камере отображается 2 неправильно классифицированных (ваши результаты могут варьироваться). Чтобы просмотреть проценты вместо количества наблюдений, выберите опцию True Positive Rates под Plot элементами управления.
Вы можете использовать эту информацию, чтобы помочь вам выбрать лучшую модель для своей цели. Если ложные срабатывания в этом классе очень важны для вашей задачи классификации, то выберите лучшую модель при предсказании этого класса. Если ложные срабатывания в этом классе не очень важны, и модели с меньшим количеством предикторов лучше работают в других классах, то выберите модель, чтобы сравнить некоторую общую точность, чтобы исключить некоторые предикторы и облегчить набор данных в будущем.
Сравните матрицу неточностей для каждой модели на панели Models. Проверьте диалоговое окно Выбора признаков, чтобы увидеть, какие предикторы включены в каждую модель.
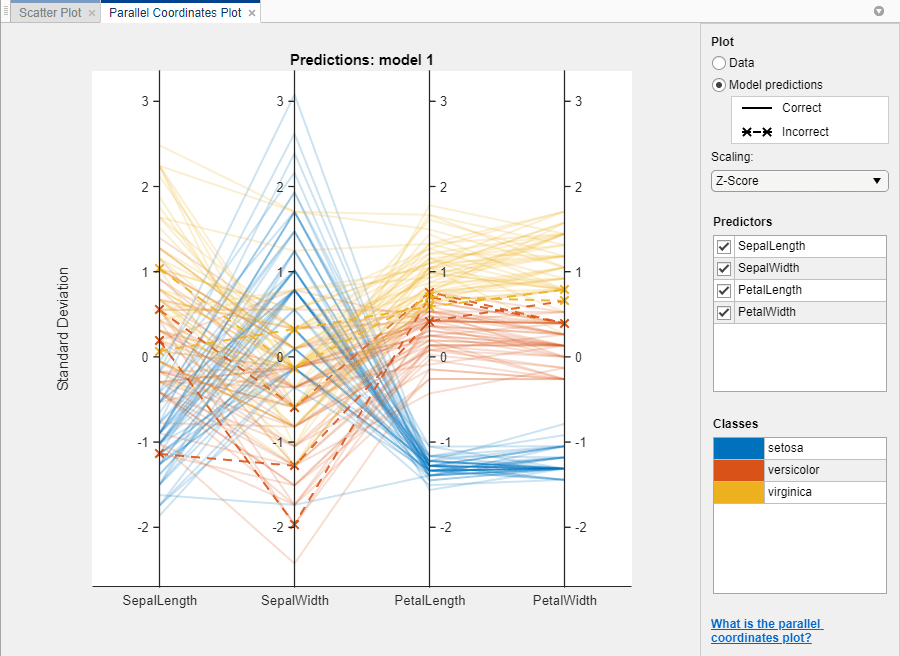
Чтобы исследовать функции, которые нужно включить или исключить, используйте график поля точек и график параллельных координат. На вкладке Classification Learner, в разделе Plots, нажмите Parallel Coordinates. Можно видеть, что длина лепестка и ширина лепестка являются функциями, которые лучше всего разделяют классы.
Чтобы узнать о настройках модели, выберите модель на панели Models и просмотрите дополнительные настройки. Опции неоптимизируемой модели в галерее Model Type являются предустановленными начальными точками, и можно изменить дальнейшие настройки. На вкладке Classification Learner, в разделе Model Type, нажмите Advanced. Сравните простые и средние модели дерева на панели Models и наблюдайте различия в диалоговом окне Расширенные параметры дерева (Advanced Tree Options). Настройка Maximum Number of Splits управляет глубиной дерева.
Чтобы попытаться улучшить модель грубого дерева дальше, попробуйте изменить настройку Maximum Number of Splits, затем обучите новую модель, нажав Train.
Просмотрите настройки выбранной обученной модели на панели Current Model Summary или в диалоговом окне Дополнительно.
Чтобы экспортировать лучшую обученную модель в рабочую область, на вкладке Classification Learner, в разделе Export, нажмите Export Model. В диалоговом окне «Экспорт модели» нажмите кнопку OK, чтобы принять имя переменной по умолчанию trainedModel.
Смотрите в командном окне, чтобы увидеть информацию о результатах.
Чтобы визуализировать модель дерева решений, введите:
view(trainedModel.ClassificationTree,'Mode','graph')
Можно использовать экспортированный классификатор для предсказаний новых данных. Для примера, чтобы сделать предсказания для fishertable данные в рабочей рабочей области, введите:
yfit = trainedModel.predictFcn(fishertable)
yfit содержит предсказание класса для каждой точки данных.Если вы хотите автоматизировать обучение того же классификатора с новыми данными или узнать, как программно обучить классификаторы, можно сгенерировать код из приложения. Чтобы сгенерировать код для наилучшей обученной модели, на вкладке Classification Learner, в разделе Export, нажмите Generate Function.
Приложение генерирует код из вашей модели и отображает файл в РЕДАКТОРА MATLAB. Чтобы узнать больше, смотрите Генерация кода MATLAB для обучения модели с новыми данными.
Этот пример использует данные радужки Фишера 1936 года. Данные радужки содержат измерения цветов: длина лепестка, ширина лепестка, длина чашелистика и ширина чашелистика для образцов трех видов. Обучите классификатор, чтобы предсказать вид на основе измерений предиктора.
Используйте тот же рабочий процесс для анализа и сравнения других типов классификаторов, которые можно обучить в Classification Learner.
Чтобы попробовать все наборы моделей неоптимизируемых классификаторов, доступные для вашего набора данных:
Щелкните стреле в крайнем правом углу раздела Model Type, чтобы развернуть список классификаторов.
Нажмите All, затем нажмите Train.
Чтобы узнать о других типах классификаторов, см. Train классификационных моделей» в приложении Classification Learner.
