В этом примере показано, как создать и сравнить различные деревья регрессии с помощью приложения Regression Learner и экспортировать обученные модели в рабочую область, чтобы делать предсказания для новых данных.
Можно обучить деревья регрессии прогнозировать отклики на заданные входные данные. Чтобы предсказать реакцию регрессионного дерева, следуйте за деревом от корневого (начального) узла до листового узла. В каждом узле определите, какой ветви следовать, используя правило, сопоставленное с этим узлом. Продолжайте, пока не придете на узел листа. Предсказанная реакция является значением, связанным с этим листовым узлом.
Statistics and Machine Learning Toolbox™ деревьев являются двоичными. Каждый шаг предсказания включает в себя проверку значения одной переменной предиктора. Например, вот простое дерево регрессии:
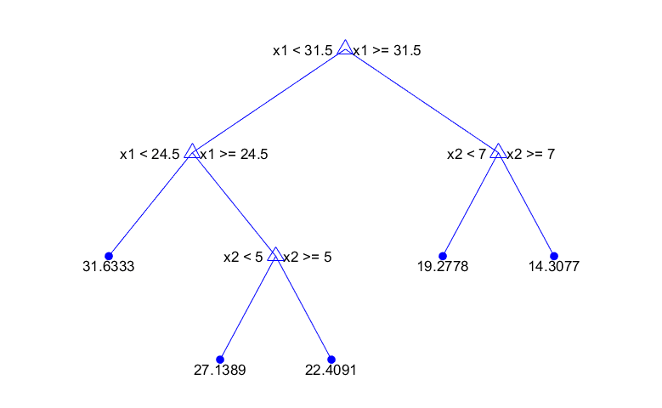
Это дерево предсказывает ответ на основе двух предикторов, x1 и x2. Чтобы предсказать, начните с верхнего узла. В каждом узле проверяйте значения предикторов, чтобы решить, какой ветви следовать. Когда ветви достигают конечного узла, ответ устанавливается на значение, соответствующее этому узлу.
Этот пример использует carbig набор данных. Этот набор данных содержит характеристики различных моделей автомобилей, выпущенных с 1970 по 1982 год, включая:
Ускорение
Количество цилиндров
Рабочий объем двигателя
Степень Engine (Лошадиная сила)
Модельный год
Вес
Страна источника
Мили на галлон (MPG)
Обучите регрессионые деревья, чтобы предсказать расход топлива в милях на галлон модели автомобиля, учитывая другие переменные в качестве входов.
В MATLAB®, загрузите carbig Данные установите и создайте таблицу, содержащую различные переменные:
load carbig cartable = table(Acceleration, Cylinders, Displacement,... Horsepower, Model_Year, Weight, Origin, MPG);
На вкладке Apps, в группе Machine Learning and Deep Learning, нажмите Regression Learner.
На вкладке Regression Learner, в разделе File, выберите New Session > From Workspace.
В разделе Data Set Variable в диалоговом окне «Новый сеанс из рабочей области» выберите cartable из списка таблиц и матриц в рабочей рабочей области.
Заметьте, что приложение имеет предварительно выбранные переменные отклика и предиктора. MPG выбран в качестве отклика, а все другие переменные в качестве предикторов. В данном примере не изменяйте выбор.
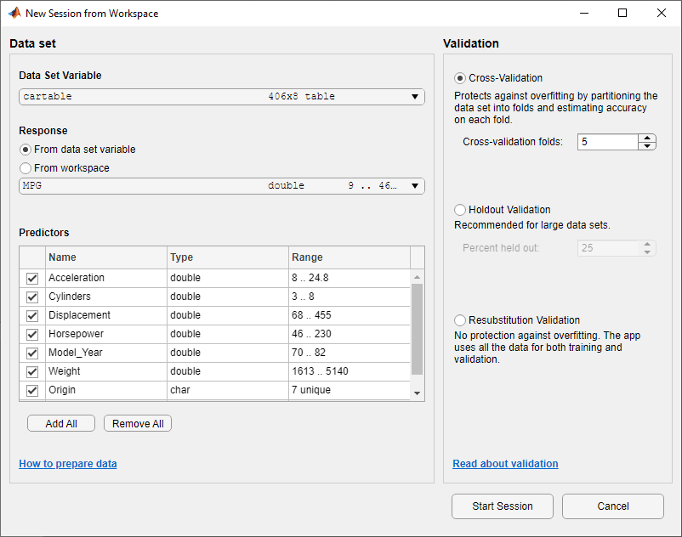
Чтобы принять схему валидации по умолчанию и продолжить, нажмите Start Session. Опция валидации по умолчанию является перекрестной валидацией, чтобы защитить от сверхподбора кривой.
Regression Learner создает график отклика с номером записи на оси x -.
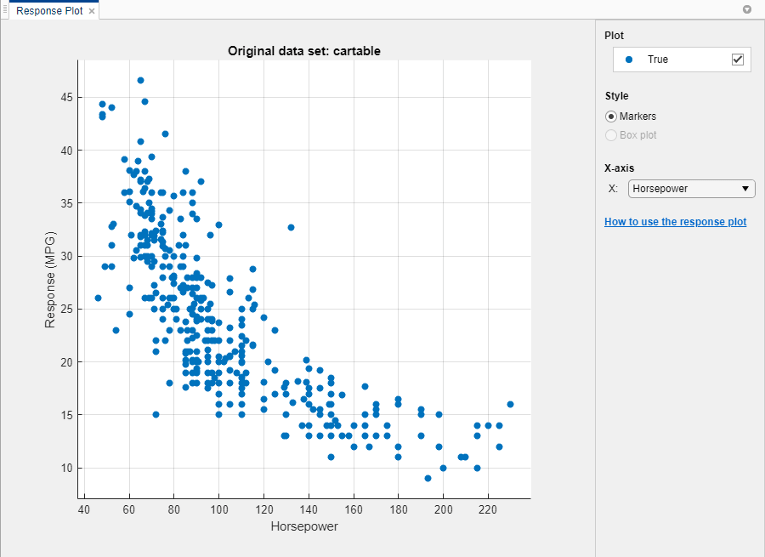
Используйте график отклика, чтобы выяснить, какие переменные полезны для предсказания отклика. Чтобы визуализировать отношение между различными предикторами и ответом, выберите различные переменные в списке X под X-axis.
Наблюдайте, какие переменные наиболее четко коррелируются с ответом. Displacement, Horsepower, и Weight все имеют четко видимое влияние на ответ и все показывают отрицательную связь с ответом.
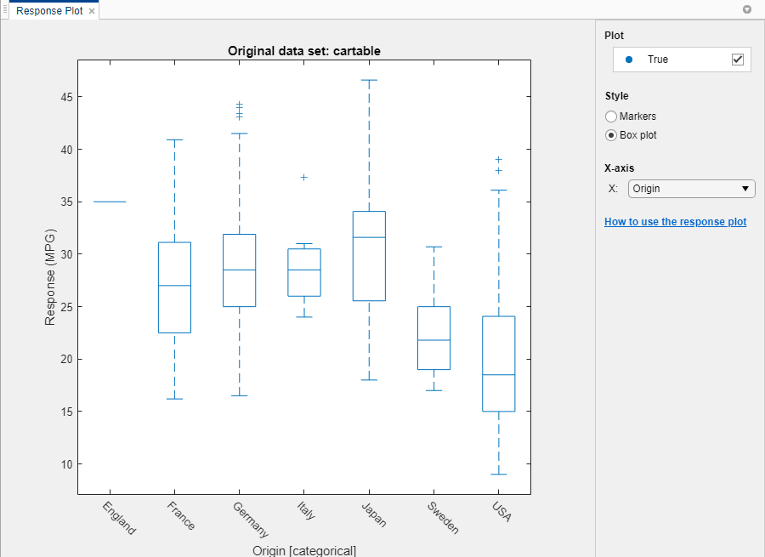
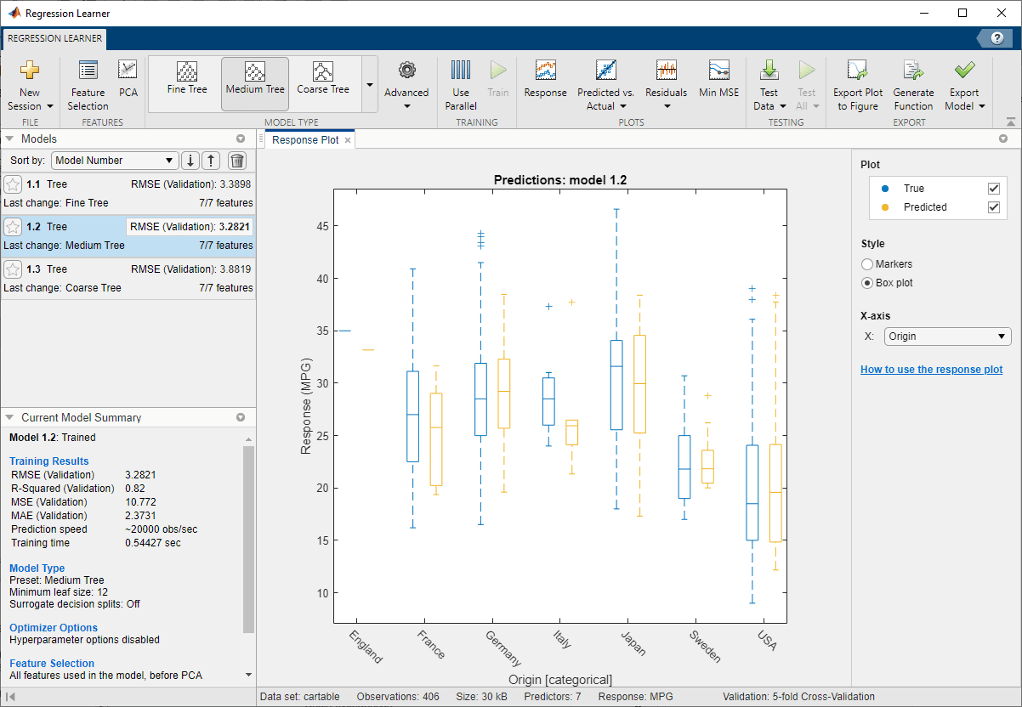
Выберите переменную Origin под X-axis. Автоматически отображается прямоугольный график. Прямоугольный график показывает типичные значения отклика и любые возможные выбросы. Прямоугольный график полезен при построении графиков маркеров, что приводит к перекрытию многих точек. Чтобы показать прямоугольный график, когда переменная на оси x имеет несколько уникальных значений, под Style выберите Box plot .
Создайте набор деревьев регрессии. На вкладке Regression Learner, в разделе Model Type, нажмите All Trees.
![]()
Затем нажмите Train ![]() .
.
Совет
Если у вас есть Parallel Computing Toolbox™, можно обучить все модели (All Trees) одновременно, нажав кнопку Use Parallel в разделе Training перед нажатием Train. После нажатия кнопки Train открывается диалоговое окно Открытие параллельного пула, которое остается открытым, пока приложение открывает параллельный пул работников. В течение этого времени вы не можете взаимодействовать с программным обеспечением. После открытия пула приложение обучает модели одновременно.
Regression Learner создает и обучает три дерева регрессии: Fine Tree, Medium Tree и Coarse Tree.
Три модели появляются на панели Models. Проверьте RMSE (Validation) (среднюю квадратную ошибку корня валидации) моделей. Лучший счет подсвечивается в кубе.
Fine Tree и Medium Tree имеют сходные RMSE, в то время как Coarse Tree менее точен.
Regression Learner строит графики как истинной реакции обучения, так и предсказанной реакции выбранной на данный момент модели.
Примечание
Если вы используете валидацию, в результатах есть некоторая случайность, и поэтому счет валидации вашей модели может отличаться от показанных результатов.
Выберите модель на панели Models, чтобы просмотреть результаты этой модели. В группе X-axis выберите Horsepower и исследуйте график отклика. И истинный, и предсказанный отклики теперь построены. Отобразите предсказания ошибки, нарисованные как вертикальные линии между предсказанной и истинной характеристиками, установив флажок Errors.
Дополнительные сведения о выбранной модели см. на панели Current Model Summary. Проверяйте и сравните дополнительные характеристики модели, такие как R-квадрат (коэффициент детерминации), MAE (средняя абсолютная ошибка) и скорость предсказания. Дополнительные сведения см. в разделе Просмотр и сравнение статистики модели. На панели Current Model Summary также можно найти подробности о выбранном типе модели, например, опции, используемые для настройки модели.
Постройте график предсказанного отклика от истинного отклика. На вкладке Regression Learner, в разделе Plots, нажмите Predicted vs. Actual и выберите Validation Data. Используйте этот график, чтобы понять, насколько хорошо регрессионая модель делает предсказания для различных значений отклика.
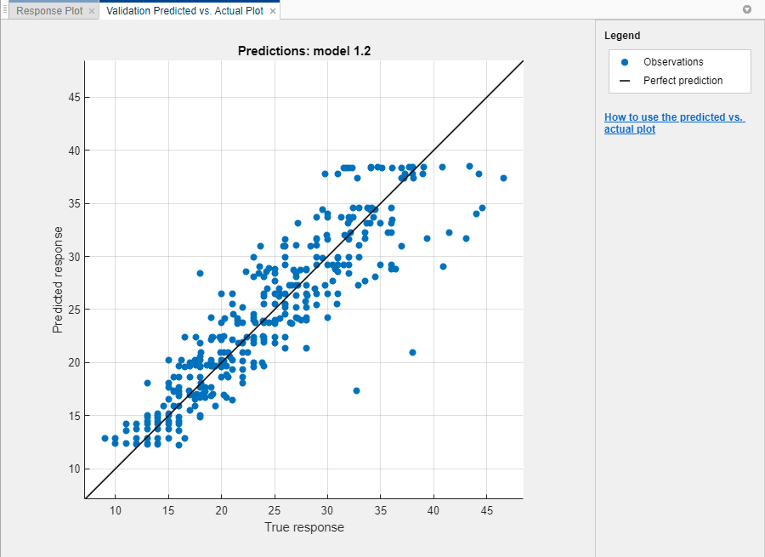
Совершенная регрессионая модель предсказала ответ, равный истинной реакции, поэтому все точки лежат на диагональной линии. Расстояние по вертикали от линии до любой точки является ошибкой предсказания для этой точки. Хорошая модель имеет небольшие ошибки, поэтому предсказания разбросаны около линии. Обычно хорошая модель имеет точки, разбросанные примерно симметрично вокруг диагональной линии. Если вы можете увидеть какие-либо четкие шаблоны на графике, вероятно, что вы можете улучшить свою модель.
Выберите другие модели на панели Models и сравните предсказанные и фактические графики.
В Model Type галерее снова выберите All Trees. Чтобы попытаться улучшить модель, попробуйте включить различные функции в модель. Посмотрите, можно ли улучшить модель, удалив функции с низкой прогностической степенью. На вкладке Regression Learner, в разделе Features, нажмите Feature Selection.

В диалоговом окне Выборе признаков снимите флажки для Acceleration и Cylinders, чтобы исключить их из предикторов.
Нажмите Train , ![]() чтобы обучить новые деревья регрессии с помощью новых настроек предиктора.
чтобы обучить новые деревья регрессии с помощью новых настроек предиктора.
Наблюдайте новые модели на панели Models. Эти модели являются такими же деревьями регрессии, как и прежде, но обучены с использованием только пяти из семи предикторов. Приложение отображает, сколько предикторов используется. Чтобы проверить, какие предикторы используются, щелкните модель на панели Models и наблюдайте флажки в диалоговом окне Выбора признаков.
Модели с удаленными двумя функциями работают сопоставимо с моделями, использующими все предикторы. Модели предсказывают не лучшее использование всех предикторов по сравнению с использованием только подмножества предикторов. Если набор данных является дорогим или трудным, вы можете предпочитать модель, которая работает удовлетворительно без некоторых предикторов.
Обучите три предустановки дерева регрессии, используя только Horsepower как предиктор. Измените выбор в диалоговом окне Выбора признаков и нажатия кнопки Train.
Использование только степени двигателя в качестве предиктора приводит к моделям с более низкой точностью. Однако модели работают хорошо, учитывая, что они используют только один предиктор. С этим простым одномерным пространством предикторов крупное дерево теперь выполняет так же, как среднее и мелкое деревья.
Выберите лучшую модель на панели Models и просмотрите график невязок. На вкладке Regression Learner, в разделе Plots, нажмите Residuals и выберите Validation Data. График невязок отображает различие между предсказанной и истинной характеристиками. Чтобы отобразить невязки в качестве линейного графика, в Style разделе, выберите Lines.
В разделе X-axis выберите переменную для построения графика на оси x -. Выберите или истинную реакцию, предсказанную реакцию, номер записи или один из ваших предикторов.
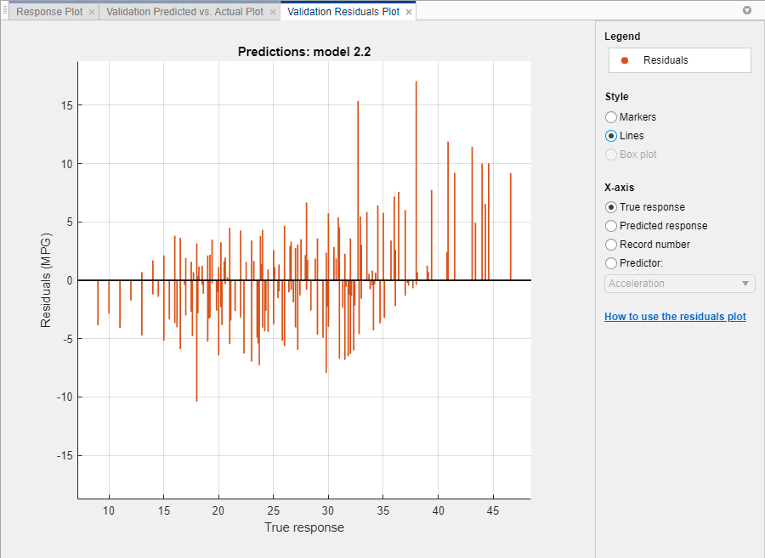
Обычно хорошая модель имеет невязки, рассеянные примерно симметрично около 0. Если вы можете увидеть какие-либо четкие шаблоны в невязках, вероятно, что вы можете улучшить свою модель.
Чтобы узнать о настройках модели, выберите лучшую модель на панели Models и просмотрите дополнительные настройки. Опции неоптимизируемой модели в галерее Model Type являются предустановленными начальными точками, и можно изменить дополнительные настройки. На вкладке Regression Learner, в разделе Model Type, нажмите Advanced. Сравните различные модели дерева регрессии на панели Models и наблюдайте различия в диалоговом окне Advanced Regression Tree Options. Настройка Minimum leaf size управляет размером листьев дерева, а через это - размером и глубиной дерева регрессии.
Чтобы попытаться улучшить модель дальше, измените настройку Minimum leaf size на 8, а затем обучите новую модель, нажав Train.
Просмотрите настройки выбранной обученной модели на панели Current Model Summary или в диалоговом окне Расширенные параметры регрессионного дерева (Advanced Regression Tree Options).
Дополнительные сведения о настройках дерева регрессии см. в разделе «Деревья регрессии».
Экспорт выбранной модели в рабочую область. На вкладке Regression Learner, в разделе Export, нажмите Export Model. В диалоговом окне «Экспорт модели» нажмите кнопку OK, чтобы принять имя переменной по умолчанию trainedModel.
Чтобы увидеть информацию о результатах, смотрите в командном окне.
Используйте экспортированную модель, чтобы делать предсказания на новых данных. Для примера, чтобы сделать предсказания для cartable данные в рабочей рабочей области, введите:
yfit = trainedModel.predictFcn(cartable)
yfit содержит предсказанный ответ для каждой точки данных.Если вы хотите автоматизировать обучение той же модели с новыми данными или узнать, как программно обучить регрессионые модели, можно сгенерировать код из приложения. Чтобы сгенерировать код для наилучшей обученной модели, на вкладке Regression Learner, в разделе Export, нажмите Generate Function.
Приложение генерирует код из вашей модели и отображает файл в РЕДАКТОРА MATLAB. Дополнительные сведения см. в разделе Генерация кода MATLAB для обучения модели с новыми данными.
Совет
Используйте тот же рабочий процесс, что и в этом примере, чтобы вычислить и сравнить другие типы регрессионых моделей, которые можно обучить в Regression Learner.
Обучите все доступные наборы неоптимизируемых регрессионых моделей:
В крайнем правом углу Model Type раздела щелкните стреле, чтобы развернуть список регрессионых моделей.
Нажмите All
, а затем нажмите Train.![]()
Чтобы узнать о других типах регрессионных моделей, см. Train регрессионых моделей» в приложении Regression Learner.
