Вы можете использовать приложение Regression Learner, чтобы автоматически обучить выбор различных моделей на ваших данных. Используйте автоматическое обучение, чтобы быстро попробовать выбор типов моделей, а затем исследовать перспективные модели в интерактивном режиме. Чтобы начать, сначала попробуйте следующие опции:
| Запуски работы | Описание |
|---|---|
| All Quick-To-Train | Сначала попробуйте кнопку All Quick-To-Train. Приложение обучает все типы моделей, которые обычно быстро обучаются. |
| All | Используйте кнопку All, чтобы обучить все доступные неоптимизируемые типы моделей. Обучает каждый тип независимо от любых ранее обученных моделей. Может быть длительным. |
Чтобы узнать больше об автоматизированном обучении модели, см. «Автоматическое обучение регрессионой модели».
Если вы хотите исследовать модели по одной за раз или если вы уже знаете, какой тип модели вы хотите, можно выбрать отдельные модели или обучить группу того же типа. Чтобы увидеть все доступные опции регрессионной модели, на вкладке Regression Learner, щелкните стреле в разделе Model Type, чтобы развернуть список регрессионых моделей. Неоптимизируемые опции модели в галерее являются предустановленными начальными точками с различными настройками, подходящими для области значений различных задач регрессии. Чтобы использовать оптимизируемые опции модели и настроить гиперпараметры модели автоматически, смотрите Оптимизацию Гипероптимизации параметров управления в Приложении Regression Learner.
Для помощи с выбором лучшего типа модели для вашей задачи смотрите таблицы, показывающие типичные характеристики различных типов регрессионых моделей. Определитесь с компромиссом, который вы хотите в скорости, гибкости и интерпретации. Лучший тип модели зависит от ваших данных.
Совет
Чтобы избежать избыточной подгонки, найдите менее гибкую модель, которая обеспечивает достаточную точность. Например, проверьте простые модели, такие как деревья регрессии, которые быстро и легко интерпретируются. Если модели недостаточно точны, прогнозируя ответ, выберите другие модели с более высокой гибкостью, такие как ансамбли. Для управления гибкостью смотрите детали для каждого типа модели.
Характеристики типов регрессионной модели
| Тип регрессионной модели | Интерпретируемость |
|---|---|
| Модели линейной регрессии
| Легкий |
| Деревья регрессии
| Легкий |
| Машины опорных векторов
| Легкий для линейных SVM. Тяжело для других ядер. |
| Модели регрессии Гауссова процесса
| Трудно |
| Ансамбли деревьев
| Трудно |
| Нейронные сети
| Трудно |
Чтобы считать описание каждой модели в Regression Learner, перейдите к представлению деталей в списке всех наборов стилей модели.
Совет
Неоптимизируемые модели в галерее Model Type являются предустановленными начальными точками с различными настройками. После того, как вы выберете тип модели, такой как деревья регрессии, попробуйте обучить все неоптимизируемые предустановки, чтобы увидеть, какой из них создает лучшую модель с вашими данными.
Для получения инструкций по рабочему процессу см. Train регрессионых моделей» в приложении Regression Learner.
В Regression Learner все типы моделей поддерживают категориальные предикторы.
Совет
Если у вас есть категориальные предикторы со многими уникальными значениями, обучение линейных моделей с взаимодействием или квадратичными терминами и ступенчатыми линейными моделями может использовать много памяти. Если модель не может обучаться, попробуйте удалить эти категориальные предикторы.
Модели линейной регрессии имеют предикторы, которые являются линейными в параметрах модели, легко интерпретируются и быстро делают предсказания. Эти характеристики делают линейные регрессионые модели популярными моделями, чтобы попробовать первыми. Однако высоко ограниченная форма этих моделей означает, что они часто имеют низкую точность прогноза. После подбора кривой линейной регрессионной модели попробуйте создать более гибкие модели, такие как регрессионые деревья, и сравните результаты.
Совет
В Model Type галерее нажмите All Linear
, чтобы попробовать каждый из![]() опций линейной регрессии и увидеть, какие настройки производят лучшую модель с вашими данными. Выберите лучшую модель на панели Models и попытайтесь улучшить эту модель с помощью выбора признаков и изменения некоторых расширенных опций.
опций линейной регрессии и увидеть, какие настройки производят лучшую модель с вашими данными. Выберите лучшую модель на панели Models и попытайтесь улучшить эту модель с помощью выбора признаков и изменения некоторых расширенных опций.
| Тип регрессионной модели | Интерпретируемость | Моделирование гибкости |
|---|---|---|
| Linear | Легкий | Очень низкий |
| Interactions Linear | Легкий | Среда |
| Robust Linear | Легкий | Очень низкий. Менее чувствителен к выбросам, но может быть медленно тренироваться. |
| Stepwise Linear | Легкий | Среда |
Совет
Пример рабочего процесса см. в разделе Train регрессионных деревьев с использованием приложения Regression Learner.
Regression Learner использует fitlm функция для обучения линейных, взаимодействий линейных и робастных линейных моделей. Приложение использует stepwiselm функция для обучения пошаговых линейных моделей.
Для линейных, взаимодействий линейных и робастных линейных моделей можно задать следующие опции:
Terms
Задайте, какие термины использовать в линейной модели. Вы можете выбрать из:
Linear. Постоянный член и линейные условия в предикторах
Interactions. Постоянный член, линейные условия и условия взаимодействия между предикторами
Pure Quadratic. Постоянный член, линейные условия и условия, которые являются чисто квадратичными в каждом из предикторов
Quadratic. Постоянный член, линейные условия и квадратичные условия (включая взаимодействия)
Robust option
Задайте, использовать ли устойчивую целевую функцию и сделать свою модель менее чувствительной к выбросам. При помощи этой опции метод аппроксимации автоматически присваивает более низкие веса точкам данных, которые с большей вероятностью являются выбросами.
Пошаговая линейная регрессия начинается с начальной модели и систематически добавляет и удаляет условия к модели на основе объяснительной степени этих постепенно больших и меньших моделей. Для пошаговых линейных моделей можно задать следующие опции:
Initial terms
Задайте условия, которые включены в начальную модель пошаговой процедуры. Вы можете выбрать из Constant, Linear, Interactions, Pure Quadratic, и Quadratic.
Upper bound on terms
Задайте наивысший порядок членов, которые пошаговая процедура может добавить в модель. Вы можете выбрать из Linear, Interactions, Pure Quadratic, и Quadratic.
Maximum number of steps
Задайте максимальное количество различных линейных моделей, которые можно попробовать в пошаговой процедуре. Чтобы ускорить обучение, попробуйте уменьшить максимальное количество шагов. Выбор небольшого максимального количества шагов уменьшает ваши шансы найти хорошую модель.
Совет
Если у вас есть категориальные предикторы со многими уникальными значениями, обучение линейных моделей с взаимодействием или квадратичными терминами и ступенчатыми линейными моделями может использовать много памяти. Если модель не может обучаться, попробуйте удалить эти категориальные предикторы.
Деревья регрессии легко интерпретировать, быстро для подбора кривой и предсказания, и с низким уровнем использования памяти. Старайтесь выращивать деревья меньшего размера с меньшим количеством больших листьев, чтобы предотвратить сверхподбор кривой. Управляйте размером листа с помощью настройки Minimum leaf size.
Совет
В галерее Model Type нажмите All Trees
, чтобы попробовать каждый из![]() неоптимизируемых опций регрессионого дерева и увидеть, какие настройки дают лучшую модель с вашими данными. Выберите лучшую модель на панели Models и попытайтесь улучшить эту модель с помощью выбора признаков и изменения некоторых расширенных опций.
неоптимизируемых опций регрессионого дерева и увидеть, какие настройки дают лучшую модель с вашими данными. Выберите лучшую модель на панели Models и попытайтесь улучшить эту модель с помощью выбора признаков и изменения некоторых расширенных опций.
| Тип регрессионной модели | Интерпретируемость | Моделирование гибкости |
|---|---|---|
| Fine Tree | Легкий | Высоко Многие маленькие листья для очень гибкой функции отклика (Минимальный размер листа 4.) |
| Medium Tree | Легкий | Среда Листья среднего размера для менее гибкой функции отклика (Минимальный размер листа 12.) |
| Coarse Tree | Легкий | Низко Немного больших листьев для функции грубой реакции (Минимальный размер листа 36.) |
Чтобы предсказать ответ регрессионного дерева, следуйте за деревом от корневого (начального) узла до листового узла. Узел листа содержит значение отклика.
Statistics and Machine Learning Toolbox™ деревьев являются двоичными. Каждый шаг предсказания включает в себя проверку значения одной переменной предиктора. Например, вот простое дерево регрессии
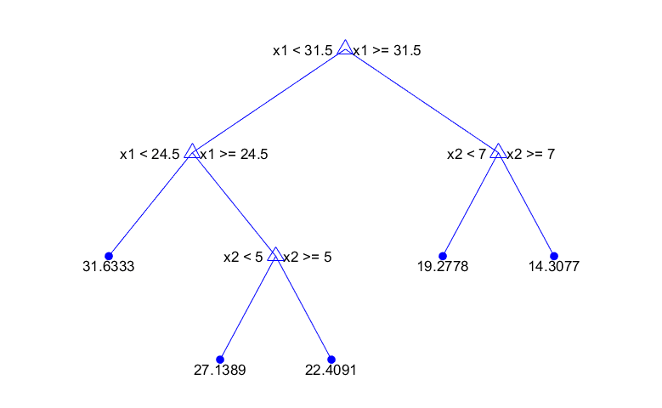
Это дерево предсказывает ответ на основе двух предикторов, x1 и x2. Чтобы сделать предсказание, начните с верхнего узла. В каждом узле проверяйте значения предикторов, чтобы решить, какой ветви следовать. Когда ветви достигают конечного узла, ответ устанавливается на значение, соответствующее этому узлу.
Можно визуализировать модель дерева регрессии, экспортировав модель из приложения и затем введя:
view(trainedModel.RegressionTree,'Mode','graph')
Совет
Пример рабочего процесса см. в разделе Train регрессионных деревьев с использованием приложения Regression Learner.
Приложение Regression Learner использует fitrtree функция для обучения регрессионных деревьев. Можно задать следующие опции:
Minimum leaf size
Укажите минимальное количество обучающих выборок, используемых для вычисления отклика каждого узла листа. Когда вы выращиваете дерево регрессии, учитывайте его простоту и прогнозирующую степень. Чтобы изменить минимальный размер листа, нажмите кнопки или введите положительное целое значение в Minimum leaf size поле.
Мелкое дерево со многими маленькими листьями обычно очень точно на обучающих данных. Однако дерево может не показать сопоставимую точность на независимом тестовом наборе. Очень листовое дерево имеет тенденцию к избыточной подгонке, и его точность валидации часто намного ниже, чем его точность обучения (или реституции).
Напротив, крупное дерево с меньшим количеством крупных листьев не достигает высокой точности обучения. Но крупное дерево может быть более надежным, поскольку его точность обучения может быть близка к точности обучения репрезентативного тестового набора.
Совет
Уменьшите Minimum leaf size, чтобы создать более гибкую модель.
Surrogate decision splits - только для отсутствующих данных.
Укажите использование суррогата для разделения решений. Если у вас есть данные с отсутствующими значениями, используйте суррогатные разделения, чтобы улучшить точность предсказаний.
Когда вы задаете Surrogate decision splits Onдерево регрессии находит самое большее 10 суррогатных разделений в каждом узле ветви. Чтобы изменить количество суррогатных разделений, нажмите кнопки или введите положительное целое значение в Maximum surrogates per node поле.
Когда вы задаете Surrogate decision splits Find Allдерево регрессии находит все суррогатные расщепления в каждом узле ветви. The Find All настройка может использовать значительное время и память.
Кроме того, вы можете позволить приложению автоматически выбрать некоторые из этих опций модели с помощью оптимизации гипероптимизации параметров управления. Смотрите Оптимизацию Гипероптимизации параметров управления в Приложении Regression Learner.
Можно обучить регрессионные машины опорных векторов (SVM) в Regression Learner. Линейные SVM легко интерпретируются, но могут иметь низкую точность прогноза. Нелинейные SVM труднее интерпретировать, но могут быть более точными.
Совет
В галерее Model Type щелкните All SVMs
, чтобы попробовать каждый из![]() неоптимизируемых опций SVM и увидеть, какие настройки дают лучшую модель с вашими данными. Выберите лучшую модель на панели Models и попытайтесь улучшить эту модель с помощью выбора признаков и изменения некоторых расширенных опций.
неоптимизируемых опций SVM и увидеть, какие настройки дают лучшую модель с вашими данными. Выберите лучшую модель на панели Models и попытайтесь улучшить эту модель с помощью выбора признаков и изменения некоторых расширенных опций.
| Тип регрессионной модели | Интерпретируемость | Моделирование гибкости |
|---|---|---|
| Linear SVM | Легкий | Низко |
| Quadratic SVM | Трудно | Среда |
| Cubic SVM | Трудно | Среда |
| Fine Gaussian SVM | Трудно | Высоко Позволяет быстро изменяться в функции отклика. Шкала ядра установлена в sqrt(P)/4, где P - количество предикторов. |
| Medium Gaussian SVM | Трудно | Среда Дает менее гибкую функцию отклика. Шкала ядра установлена в sqrt(P). |
| Coarse Gaussian SVM | Трудно | Низко Задает функцию жесткого отклика. Шкала ядра установлена в sqrt(P)*4. |
Statistics and Machine Learning Toolbox реализует линейную регрессию SVM, не чувствительную к эпсилонам. Этот SVM игнорирует ошибки предсказания, которые меньше, чем некоторое фиксированное число support vectors являются точками данных, которые имеют ошибки больше, чем Функция, которую SVM использует для предсказания новых значений, зависит только от векторов поддержки. Дополнительные сведения о регрессии SVM см. в разделе «Общие сведения о регрессии машины опорных векторов».
Совет
Пример рабочего процесса см. в разделе Train регрессионных деревьев с использованием приложения Regression Learner.
Regression Learner использует fitrsvm функция для обучения регрессионных моделей SVM.
Вы можете задать эти опции в приложении:
Kernel function
Функция ядра определяет нелинейное преобразование, примененное к данным, прежде чем SVM будет обучен. Вы можете выбрать из:
Gaussian или ядра функции радиального базиса (RBF)
Linear ядро, самое простое в интерпретации
Quadratic ядро
Cubic ядро
Box constraint mode
Прямоугольное ограничение управляет штрафом, налагаемым на наблюдения с большими невязками. Большее прямоугольное ограничение дает более гибкую модель. Меньшее значение дает более жесткую модель, менее чувствительную к сверхподбору кривой.
Когда Box constraint mode установлено на Autoприложение использует эвристическую процедуру, чтобы выбрать прямоугольное ограничение.
Попробуйте подстроить модель, задав прямоугольное ограничение вручную. Установите Box constraint mode значение Manual и задайте значение. Измените значение, нажав кнопки или введя положительную скалярную величину значение в поле Manual box constraint. Приложение автоматически заранее выбирает для вас разумное значение. Попытайтесь немного увеличить или уменьшить это значение и увидеть, улучшает ли это вашу модель.
Совет
Увеличьте прямоугольное значение ограничения, чтобы создать более гибкую модель.
Epsilon mode
Ошибки предсказания, которые меньше, чем значение эпсилона (,), игнорируются и рассматриваются как равные нулю. Меньшее значение эпсилона дает более гибкую модель.
Когда Epsilon mode установлено на Auto, приложение использует эвристическую процедуру, чтобы выбрать шкалу ядра.
Попробуйте подстроить модель, задав значение эпсилона вручную. Установите Epsilon mode значение Manual и задайте значение. Измените значение, нажав кнопки или введя положительную скалярную величину значение в поле Manual epsilon. Приложение автоматически заранее выбирает для вас разумное значение. Попытайтесь немного увеличить или уменьшить это значение и увидеть, улучшает ли это вашу модель.
Совет
Уменьшите значение эпсилона, чтобы создать более гибкую модель.
Kernel scale mode
Шкала ядра управляет масштабом предикторов, на которых ядро значительно изменяется. Меньшая шкала ядра дает более гибкую модель.
Когда Kernel scale mode установлено на Auto, приложение использует эвристическую процедуру, чтобы выбрать шкалу ядра.
Попробуйте подстроить модель, задав шкалу ядра вручную. Установите Kernel scale mode значение Manual и задайте значение. Измените значение, нажав кнопки или введя положительную скалярную величину значение в поле Manual kernel scale. Приложение автоматически заранее выбирает для вас разумное значение. Попытайтесь немного увеличить или уменьшить это значение и увидеть, улучшает ли это вашу модель.
Совет
Уменьшите значение шкалы ядра, чтобы создать более гибкую модель.
Standardize
Стандартизация предикторов преобразует их так, чтобы они имели среднее 0 и стандартное отклонение 1. Стандартизация удаляет зависимость от произвольных шкал в предикторах и обычно улучшает эффективность.
Кроме того, вы можете позволить приложению автоматически выбрать некоторые из этих опций модели с помощью оптимизации гипероптимизации параметров управления. Смотрите Оптимизацию Гипероптимизации параметров управления в Приложении Regression Learner.
Можно обучить модели регрессии Гауссова процесса (GPR) в Regression Learner. Модели GPR часто являются высокоточными, но могут быть трудными для интерпретации.
Совет
В галерее Model Type нажмите All GPR Models
, чтобы попробовать каждый из![]() неоптимизируемых опций модели GPR и увидеть, какие настройки производят лучшую модель с вашими данными. Выберите лучшую модель на панели Models и попытайтесь улучшить эту модель с помощью выбора признаков и изменения некоторых расширенных опций.
неоптимизируемых опций модели GPR и увидеть, какие настройки производят лучшую модель с вашими данными. Выберите лучшую модель на панели Models и попытайтесь улучшить эту модель с помощью выбора признаков и изменения некоторых расширенных опций.
| Тип регрессионной модели | Интерпретируемость | Моделирование гибкости |
|---|---|---|
| Rational Quadratic | Трудно | Автоматический |
| Squared Exponential | Трудно | Автоматический |
| Matern 5/2 | Трудно | Автоматический |
| Exponential | Трудно | Автоматический |
В регрессии Гауссова процесса ответ моделируется с помощью распределения вероятностей по пространству функций. Гибкость предустановок в галерее Model Type автоматически выбирается, чтобы дать небольшую ошибку обучения и, одновременно, защиту от сверхподбора кривой. Чтобы узнать больше о регрессии Гауссова процесса, см. Gaussian Process Regression Models.
Совет
Пример рабочего процесса см. в разделе Train регрессионных деревьев с использованием приложения Regression Learner.
Regression Learner использует fitrgp функция для обучения моделей GPR.
Вы можете задать эти опции в приложении:
Basis function
Функция базиса задает форму предшествующей средней функции модели регрессии Гауссова процесса. Вы можете выбрать из Zero, Constant, и Linear. Попробуйте выбрать другую функцию базиса и увидеть, улучшает ли это вашу модель.
Kernel function
Функция ядра определяет корреляцию в отклике как функцию от расстояния между значениями предиктора. Вы можете выбрать из Rational Quadratic, Squared Exponential, Matern 5/2, Matern 3/2, и Exponential.
Дополнительные сведения о функциях ядра см. в разделе Ковариации функций ядра ( Опций).
Use isotropic kernel
Если вы используете изотропное ядро, шкалы длины корреляции одинаковы для всех предикторов. С неизотропным ядром каждая переменная предиктора имеет свою собственную отдельную шкалу длины корреляции.
Использование анизотропного ядра может улучшить точность вашей модели, но может сделать модель медленной в соответствии.
Чтобы узнать больше о неизотропных ядрах, см. Ковариацию функции ядра ( Опций).
Kernel mode
Можно вручную задать начальные значения параметров ядра Kernel scale и Signal standard deviation. Стандартное отклонение сигнала является предшествующим стандартным отклонением значений отклика. По умолчанию приложение локально оптимизирует параметры ядра, начиная с начальных значений. Чтобы использовать параметры фиксированного ядра, снимите флажок Optimize numeric parameters в расширенных опциях.
Когда Kernel scale mode установлено на Auto, приложение использует эвристическую процедуру, чтобы выбрать начальные параметры ядра.
Если вы задаете Kernel scale mode Manualможно задать начальные значения. Нажмите кнопки или введите положительную скалярную величину значение в поле Kernel scale и поле Signal standard deviation.
Если вы снимаете флажок Use isotropic kernel, вы не можете задать начальные параметры ядра вручную.
Sigma mode
Можно вручную задать начальное значение стандартного Sigma отклонения шума наблюдения. По умолчанию приложение оптимизирует стандартное отклонение шума наблюдения, начиная с начального значения. Чтобы использовать параметры фиксированного ядра, снимите флажок Optimize numeric parameters в расширенных опциях.
Когда Sigma mode установлено на Autoприложение использует эвристическую процедуру, чтобы выбрать начальное стандартное отклонение шума наблюдения.
Если вы задаете Sigma mode Manualможно задать начальные значения. Нажмите кнопки или введите положительную скалярную величину значение в Sigma поле.
Standardize
Стандартизация предикторов преобразует их так, чтобы они имели среднее 0 и стандартное отклонение 1. Стандартизация удаляет зависимость от произвольных шкал в предикторах и обычно улучшает эффективность.
Optimize numeric parameters
При помощи этой опции приложение автоматически оптимизирует числовые параметры модели GPR. Оптимизированными параметрами являются коэффициенты Basis function, параметры ядра Kernel scale и Signal standard deviation, и Sigma стандартного отклонения шума наблюдения.
Кроме того, вы можете позволить приложению автоматически выбрать некоторые из этих опций модели с помощью оптимизации гипероптимизации параметров управления. Смотрите Оптимизацию Гипероптимизации параметров управления в Приложении Regression Learner.
Вы можете обучать ансамбли регрессионных деревьев в Regression Learner. Модели ансамбля объединяют результаты многих слабых учащихся в одну качественную модель ансамбля.
Совет
В Model Type галерее нажмите All Ensembles
, чтобы попробовать каждый из![]() неоптимизируемых опций ансамбля и увидеть, какие настройки дают лучшую модель с вашими данными. Выберите лучшую модель на панели Models и попытайтесь улучшить эту модель с помощью выбора признаков и изменения некоторых расширенных опций.
неоптимизируемых опций ансамбля и увидеть, какие настройки дают лучшую модель с вашими данными. Выберите лучшую модель на панели Models и попытайтесь улучшить эту модель с помощью выбора признаков и изменения некоторых расширенных опций.
| Тип регрессионной модели | Интерпретируемость | Метод ансамбля | Моделирование гибкости |
|---|---|---|---|
| Boosted Trees | Трудно | Ускорение методом наименьших квадратов ( | От среднего до высокого |
| Bagged Trees | Трудно | Bootstrap, агрегирующий или мешающий, с учащимися дерева регрессии. | Высоко |
Совет
Пример рабочего процесса см. в разделе Train регрессионных деревьев с использованием приложения Regression Learner.
Regression Learner использует fitrensemble функция для обучения моделей ансамбля. Можно задать следующие опции:
Minimum leaf size
Укажите минимальное количество обучающих выборок, используемых для вычисления отклика каждого узла листа. Когда вы выращиваете дерево регрессии, учитывайте его простоту и прогнозирующую степень. Чтобы изменить минимальный размер листа, нажмите кнопки или введите положительное целое значение в Minimum leaf size поле.
Мелкое дерево со многими маленькими листьями обычно очень точно на обучающих данных. Однако дерево может не показать сопоставимую точность на независимом тестовом наборе. Очень листовое дерево имеет тенденцию к избыточной подгонке, и его точность валидации часто намного ниже, чем его точность обучения (или реституции).
Напротив, крупное дерево с меньшим количеством крупных листьев не достигает высокой точности обучения. Но крупное дерево может быть более надежным, поскольку его точность обучения может быть близка к точности обучения репрезентативного тестового набора.
Совет
Уменьшите Minimum leaf size, чтобы создать более гибкую модель.
Number of learners
Попробуйте изменить количество учащихся, чтобы увидеть, можете ли вы улучшить модель. Многие учащиеся могут получить высокую точность, но могут быть длительными, чтобы соответствовать.
Совет
Увеличьте Number of learners, чтобы создать более гибкую модель.
Learning rate
Для усиленных деревьев укажите скорость обучения для усадки. Если вы задаете скорость обучения менее 1, ансамбль требует больше итераций обучения, но часто достигает лучшей точности. 0,1 является популярным начальным выбором.
Кроме того, вы можете позволить приложению автоматически выбрать некоторые из этих опций модели с помощью оптимизации гипероптимизации параметров управления. Смотрите Оптимизацию Гипероптимизации параметров управления в Приложении Regression Learner.
Модели нейронной сети обычно имеют хорошую точность прогноза; однако их нелегко интерпретировать.
Гибкость модели увеличивается с размером и количеством полносвязных слоев в нейронной сети.
Совет
В Model Type галерее нажмите All Neural Networks
, чтобы попробовать каждый из![]() предустановленных опций нейронной сети и увидеть, какие настройки производят лучшую модель с вашими данными. Выберите лучшую модель на панели Models и попытайтесь улучшить эту модель с помощью выбора признаков и изменения некоторых расширенных опций.
предустановленных опций нейронной сети и увидеть, какие настройки производят лучшую модель с вашими данными. Выберите лучшую модель на панели Models и попытайтесь улучшить эту модель с помощью выбора признаков и изменения некоторых расширенных опций.
| Тип регрессионной модели | Интерпретируемость | Моделирование гибкости |
|---|---|---|
| Narrow Neural Network | Трудно | Среда - увеличивается с Size of each fully connected layer настройкой |
| Medium Neural Network | Трудно | Среда - увеличивается с Size of each fully connected layer настройкой |
| Wide Neural Network | Трудно | Среда - увеличивается с Size of each fully connected layer настройкой |
| Bilayered Neural Network | Трудно | Высокий - увеличивается с Size of each fully connected layer настройкой |
| Trilayered Neural Network | Трудно | Высокий - увеличивается с Size of each fully connected layer настройкой |
Каждая модель является прямой, полностью связанной нейронной сетью для регрессии. Первый полностью соединенный слой нейронной сети имеет соединение с сетевого входа (данные предиктора), и каждый последующий слой имеет соединение с предыдущего уровня. Каждый полносвязный слой умножает вход на весовую матрицу и затем добавляет вектор смещения. Функция активации следует за каждым полносвязным слоем, исключая последний. Конечный полностью соединенный слой создает выход сети, а именно предсказанные значения отклика. Для получения дополнительной информации см. «Нейронные Структуры сети».
Для получения примера смотрите Train Регрессионные нейронные сети с использованием приложения Regression Learner.
Regression Learner использует fitrnet функция для обучения моделей нейронной сети. Можно задать следующие опции:
Number of fully connected layers - Задайте количество полносвязных слоев в нейронной сети, исключая конечный полносвязной слой для регрессии. Можно выбрать не более трех полносвязных слоев.
Size of each fully connected layer - Задает размер каждого полносвязного слоя, исключая конечный полносвязной слой. Если вы принимаете решение создать нейронную сеть с несколькими полносвязными слоями, рассмотрите определение слоев с уменьшающимися размерами.
Activation - Задайте функцию активации для всех полносвязных слоев, исключая конечный полносвязной слой. Выберите из следующих функций активации ReLU, Tanh, Sigmoid, и None.
Iteration limit - Задайте максимальное количество итераций обучения.
Regularization term strength - Укажите срок штрафа за регуляризацию гребня (L2).
Standardize data - Укажите, следует ли стандартизировать числовые предикторы. Если предикторы имеют широко различные шкалы, стандартизация может улучшить подгонку. Стандартизация данных настоятельно рекомендуется.
