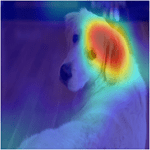
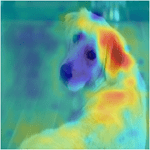
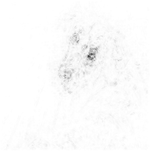
Нейронные сети для глубокого обучения часто описываются как "черные квадраты", потому что причина, что сеть принимает определенное решение, не всегда очевидна. Все больше нейронные сети для глубокого обучения используются в областях от лечения до заявок на кредит, таким образом понимая, почему сеть принимает конкретное решение, крайне важно.
Можно использовать interpretability методы, чтобы перевести сетевое поведение в выход, который может интерпретировать человек. Этот поддающийся толкованию выход может затем ответить на вопросы о предсказаниях сети. Методы Interpretability имеют много приложений, например, верификации, отладки, изучения, оценивая смещение и выбор модели.
Можно применить interpretability методы после сетевого обучения или встроить их в сеть. Преимущество постметодов обучения состоит в том, что вы не должны проводить время, создавая поддающуюся толкованию нейронную сеть для глубокого обучения. Эта тема фокусируется на постметодах обучения, которые используют тестовые изображения, чтобы объяснить предсказания сети, обученной на данных изображения.
Методы визуализации являются типом interpretability метода, которые объясняют сетевые предсказания с помощью визуальных представлений того, на что смотрит сеть. Существует много методов для визуализации сетевого поведения, таких как тепло сопоставляет, карты выступа, карты важности функции и низко-размерные проекции.
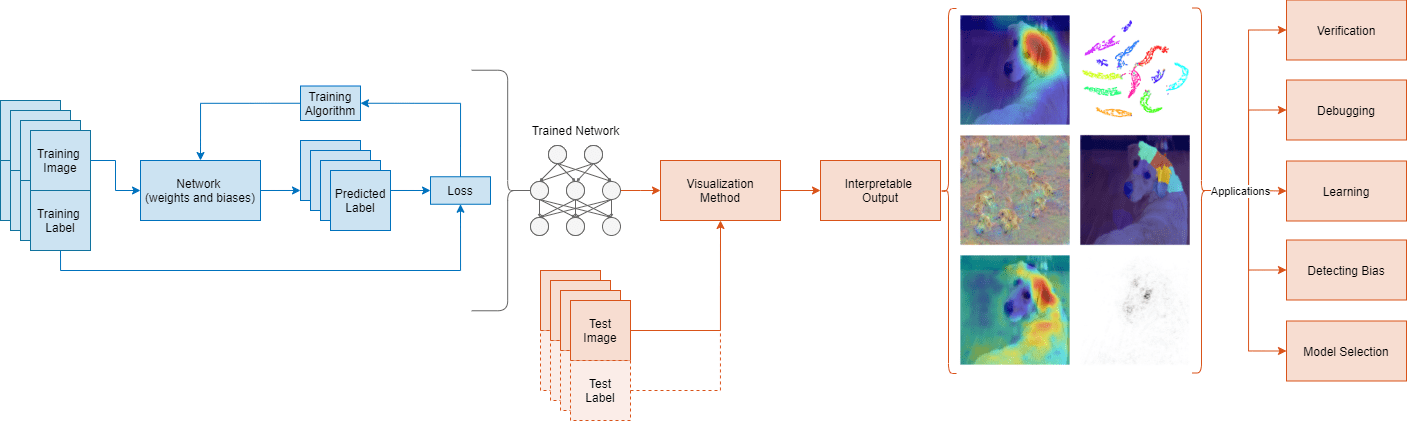
Методы Interpretability имеют различные характеристики; какой метод, который вы используете, будет зависеть от интерпретации, которую вы хотите и сеть, которую вы обучили. Методы могут быть локальными и только исследовать сетевое поведение для определенного входа или глобальной переменной и исследовать сетевое поведение через целый набор данных.
Каждый метод визуализации имеет определенный подход, который определяет выход, который он производит. Общее различие между методами - то, если они - градиент или базирующееся возмущение. Основанные на градиенте методы backpropagate сигнал от выхода назад к входу. Основанные на возмущении методы тревожат вход к сети и рассматривают эффект возмущения на предсказании. Другой подход к interpretability методу включает отображение или аппроксимацию комплексной сетевой модели к более поддающемуся толкованию пробелу. Например, некоторые методы аппроксимируют сетевые предсказания с помощью более простого, большего количества поддающейся толкованию модели. Другие методы используют методы сокращения размерности, чтобы уменьшать высоко-размерные активации вниз до 2D поддающегося толкованию или трехмерное пространство.
Следующая таблица сравнивает визуализацию interpretability методы для моделей глубокого обучения для классификации изображений. Для примера, показывающего, как использовать методы визуализации, чтобы исследовать предсказания сети классификации изображений, смотрите, Исследуют Сетевые Предсказания Используя Методы Визуализации Глубокого обучения.
Методы визуализации глубокого обучения для классификации изображений
| Метод | Визуализация в качестве примера | Функция | Местность | Подход | Разрешение | Требует настройки | Описание |
|---|---|---|---|---|---|---|---|
| Активации |
| Локальный | Визуализация активации | Низко | Нет | Визуализация активаций является простым способом изучить сетевое поведение. Большинство сверточных нейронных сетей учится обнаруживать функции как цвет и ребра в их первых сверточных слоях. В более глубоких сверточных слоях сеть учится обнаруживать более сложные функции. Для получения дополнительной информации смотрите, Визуализируют Активации Сверточной нейронной сети. | |
| CAM |
| Нет | Локальный | Основанная на градиенте активация класса нагревает карту | Низко | Нет | Отображение активации класса (CAM) является простым методом для генерации визуальных объяснений предсказаний сверточных нейронных сетей [1]. CAM использует глобальный средний слой объединения в сверточной нейронной сети, чтобы сгенерировать карту, которая подсвечивает, какие части изображения сеть использует относительно конкретной метки класса. Для получения дополнительной информации смотрите, Исследуют Сетевые Предсказания Используя Отображение Активации Класса. |
| CAM градиента |
| Локальный | Основанная на градиенте активация класса нагревает карту | Низко | Нет | Взвешенное градиентом отображение активации класса (CAM градиента) является обобщением метода CAM, который использует градиент классификационной оценки относительно сверточных функций, полных решимости сетью понять, какие части изображения являются самыми важными для классификации [2]. Места, где градиент является большим, являются местами, где итоговый счет зависит больше всего от данных. CAM градиента дает подобные результаты CAM без ограничений архитектуры CAM. Для получения дополнительной информации смотрите, что CAM градиента Показывает, Почему Позади Решений Глубокого обучения и Исследуют Сеть Семантической Сегментации Используя CAM градиента. | |
| Чувствительность поглощения газов |
| Локальный | Основанная на возмущении карта тепла | Низкий и средний | Да | Чувствительность поглощения газов измеряет сетевую чувствительность к небольшим возмущениям во входных данных. Метод тревожит небольшие районы входа, заменяя его на маску закрытия, обычно серый квадрат. Когда маска преодолевает изображение, метод измеряет изменение в счете вероятности к данному классу. Можно использовать чувствительность поглощения газов, чтобы подсветить, какие части изображения являются самыми важными для классификации. Чтобы получить лучшие результаты чувствительности поглощения газов, необходимо выбрать правильные значения для Для получения дополнительной информации смотрите, Изучают Сетевые Предсказания Используя Поглощение газов. | |
| ИЗВЕСТЬ |
| Локальный | Основанная на возмущении модель прокси, покажите важность | Низко к высоко | Да | Метод LIME аппроксимирует поведение классификации нейронной сети для глубокого обучения с помощью более простого, большего количества поддающейся толкованию модели, такой как линейная модель или дерево регрессии [3]. Простая модель определяет важность функций входных данных как прокси для важности функций к нейронной сети для глубокого обучения. Для получения дополнительной информации смотрите, Изучают Сетевые Предсказания Используя LIME и Исследуют Классификации Спектрограмм Используя LIME. | |
| Приписывание градиента |
| Нет | Локальный | Основанная на градиенте карта выступа | Высоко | Нет | Методы приписывания градиента предоставляют карты пиксельного разрешения, показывающие, какие пиксели являются самыми важными для сетевых решений классификации [4][5]. Эти методы вычисляют градиент счета класса относительно входных пикселей. Интуитивно, карты показывают, какие пиксели больше всего влияют на счет класса, когда изменено. Методы приписывания градиента производят, сопоставляет тот же размер как входное изображение. Поэтому карты приписывания градиента имеют высокое разрешение, но они имеют тенденцию быть намного более шумными, когда хорошо обученная глубокая сеть не строго зависит от точного значения определенных пикселей. Для получения дополнительной информации смотрите, Исследуют Решения Классификации Используя Методы Приписывания Градиента. |
| Глубокая мечта |
| Глобальная переменная | Основанная на градиенте максимизация активации | Низко к высоко | Да | Глубокая Мечта является методом визуализации функции, который синтезирует изображения, которые строго активируют слоя сети [6]. Путем визуализации этих изображений можно подсветить функции изображений, изученные сетью. Эти изображения полезны для понимания и диагностирования сетевого поведения. Для получения дополнительной информации смотрите, что Глубокие Изображения Мечты Используют GoogLeNet. | |
| t-SNE |
|
| Глобальная переменная | Сокращение размерности | N/A | Нет | t-SNE является методом сокращения размерности, который сохраняет расстояния так, чтобы точки друг около друга в представлении высокой размерности также нашлись друг около друга в низко-размерном представлении [7]. Можно использовать t-SNE, чтобы визуализировать, как нейронные сети для глубокого обучения изменяют представление входных данных, когда это проходит через слоя сети. Для получения дополнительной информации, Поведение Сети вида на море Используя tsne. |
| Максимальные и минимальные изображения активации |
| Нет | Глобальная переменная | Основанная на градиенте максимизация активации | N/A | Нет | Визуализация изображений, которые строго или слабо активируют сеть для каждого класса, является простым способом преуменьшить вашу сеть. Изображения, которые строго активируют подсветку, что сеть думает "типичное" изображение от того класса, похожи. Изображения, которые слабо активируются, могут помочь вам обнаружить, почему ваша сеть делает неправильные предсказания классификации. Для получения дополнительной информации смотрите, Визуализируют Классификации Изображений Используя Максимальные и Минимальные Изображения Активации. |
Много interpretability фокусируются на интерпретации классификации изображений или сетей регрессии. Интерпретация данных неизображений часто более сложна из-за невидимой природы данных. Чтобы исследовать активации сети LSTM, используйте activations и tsne Функции Statistics and Machine Learning Toolbox. Для примера, показывающего, как исследовать предсказания сети LSTM, смотрите, Визуализируют Активации Сети LSTM. Чтобы исследовать поведение сети, обученной на табличных функциях, используйте lime (Statistics and Machine Learning Toolbox) и shapley Функции Statistics and Machine Learning Toolbox. Для примера, показывающего, как интерпретировать входную сеть функции, смотрите, Интерпретируют Глубокие Сетевые Предсказания на Табличных данных Используя LIME. Для получения дополнительной информации об интерпретации моделей машинного обучения, смотрите, Интерпретируют Модели Машинного обучения (Statistics and Machine Learning Toolbox).
[1] Чжоу, Bolei, Aditya Khosla, Агата Лапедриса, Од Олива и Антонио Торрэлба. "Изучая Глубокие Функции Отличительной Локализации". В 2 016 Продолжениях Конференции по IEEE по Компьютерному зрению и Распознаванию образов: 2921–2929. Лас-Вегас: IEEE, 2016.
[2] Selvaraju, Рэмпрасаэт Р., Майкл Когсвелл, Десять кубометров Abhishek, Рамакришна Ведэнтэм, Devi Parikh и Dhruv Batra. “CAM градиента: Визуальные Объяснения от Глубоких Сетей через Основанную на градиенте Локализацию”. В 2 017 Продолжениях Конференции по IEEE по Компьютерному зрению: 618–626. Венеция, Италия: IEEE, 2017. https://doi.org/10.1109/ICCV.2017.74.
[3] Рибейру, Марко Тулио, Сэмир Сингх и Карлос Гуестрин. “‘Почему я должен Доверять Вам?’: Объяснение Предсказаний Любого Классификатора”. В Продолжениях 22-й Международной конференции ACM SIGKDD по вопросам Открытия Знаний и Анализа данных (2016): 1135–1144. Нью-Йорк, Нью-Йорк: Ассоциация вычислительной техники, 2016. https://doi.org/10.1145/2939672.2939778.
[4] Симонян, Карен, Андреа Ведальди и Эндрю Зиссермен. “Глубоко В Сверточных Сетях: Визуализация Моделей Классификации Изображений и Карт Выступа”. Предварительно распечатайте, представленный 19 апреля 2014. https://arxiv.org/abs/1312.6034.
[5] Tomsett, Ричард, Дэн Харборн, Supriyo Chakraborty, Прадхви Геррэм и Алан Прис. “Проверки работоспособности на Метрики Выступа”. Продолжения Конференции AAAI по Искусственному интеллекту, 34, № 04, (апрель 2020): 6021–29, https://doi.org/10.1609/aaai.v34i04.6064.
[6] TensorFlow. "DeepDreaming с TensorFlow". https://github.com/tensorflow/docs/blob/master/site/en/tutorials/generative/deepdream.ipynb.
[7] ван дер Маатен, Лоренс и Джеффри Хинтон. "Визуализируя Данные Используя t-SNE". Журнал Исследования Машинного обучения, 9 (2008): 2579–2605.
gradCAM | imageLIME | occlusionSensitivity | deepDreamImage | tsne (Statistics and Machine Learning Toolbox) | activations