Вычислите выход, ошибку и веса адаптивного фильтра LMS
dsp.LMSFilter Система object™ реализует адаптивный фильтр конечной импульсной характеристики (FIR), который сходится входной сигнал к желаемому сигналу с помощью одного из следующих алгоритмов:
LMS
Нормированный LMS
Данные знака LMS
Ошибка знака LMS
Знак знака LMS
Для получения дополнительной информации о каждом из этих методов см. Алгоритмы.
Фильтр адаптирует свои веса до ошибки между сигналом первичного входного параметра, и желаемый сигнал минимален. Среднее квадратичное этой ошибки (MSE) вычисляется с помощью msesim функция. Предсказанная версия MSE определяется с помощью Винера, просачиваются msepred функция. maxstep функция вычисляет максимальный размер шага адаптации, который управляет быстротой сходимости.
Для обзора адаптивной методологии фильтра и наиболее распространенных приложений адаптивные фильтры используются в, видят Обзор Адаптивных Фильтров и Приложения.
Отфильтровать сигнал с помощью адаптивного КИХ-фильтра:
Создайте dsp.LMSFilter объект и набор его свойства.
Вызовите объект с аргументами, как будто это была функция.
Чтобы узнать больше, как Системные объекты работают, смотрите то, Что Системные объекты?
При особых условиях этот Системный объект также поддерживает генерацию кода SIMD. Для получения дополнительной информации смотрите Генерацию кода.
lms = dsp.LMSFilterlms, это вычисляет отфильтрованный выход, ошибку фильтра и веса фильтра для данного входа и желаемого сигнала с помощью алгоритма наименьшее количество средних квадратичных (LMS).
lms = dsp.LMSFilter( возвращает объект фильтра LMS с каждым заданным набором свойств к заданному значению. Заключите каждое имя свойства в одинарные кавычки. Можно использовать этот синтаксис с предыдущим входным параметром.Name,Value)
Если в противном случае не обозначено, свойства являются ненастраиваемыми, что означает, что вы не можете изменить их значения после вызова объекта. Объекты блокируют, когда вы вызываете их, и release функция разблокировала их.
Если свойство является настраиваемым, можно изменить его значение в любое время.
Для получения дополнительной информации об изменении значений свойств смотрите Разработку системы в MATLAB Используя Системные объекты.
Method — Метод, чтобы вычислить веса фильтра'LMS' (значение по умолчанию) | 'Normalized LMS' | 'Sign-Data LMS' | 'Sign-Error LMS' | 'Sign-Sign LMS'Метод, чтобы вычислить веса фильтра в виде одного из следующего:
'LMS' – Решает уравнение Вайнера-Гопфа и находит коэффициенты фильтра для адаптивного фильтра.
'Normalized LMS' – Нормированное изменение LMS-алгоритма.
'Sign-Data LMS' – Коррекция к весам фильтра в каждой итерации зависит от знака входа x.
'Sign-Error LMS' – Коррекция применилась к текущим весам фильтра за каждую последовательную итерацию, зависит от знака ошибки, err.
'Sign-Sign LMS' – Коррекция применилась к текущим весам фильтра за каждую последовательную итерацию, зависит от обоих знак x и знак err.
Для получения дополнительной информации об алгоритмах см. Алгоритмы.
Length — Длина КИХ фильтрует вектор весовДлина КИХ фильтрует вектор весов в виде положительного целого числа.
Пример: 64
Пример: 16
Типы данных: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
StepSizeSource — Метод, чтобы задать размер шага адаптации'Property' (значение по умолчанию) | 'Input port'Метод, чтобы задать размер шага адаптации в виде одного из следующего:
'Property' – Свойство StepSize задает размер каждого шага адаптации.
'Input port' – Задайте размер шага адаптации как одни из входных параметров к объекту.
StepSize — Размер шага адаптацииФактор размера шага адаптации в виде неотрицательного скаляра. Для сходимости нормированного метода LMS размер шага должен быть больше 0 и меньше чем 2.
Размер небольшого шага гарантирует небольшую установившуюся ошибку между выходом y и желаемым сигналом d. Если размер шага мал, быстрота сходимости уменьшений фильтра. Чтобы улучшить быстроту сходимости, увеличьте размер шага. Обратите внимание на то, что, если размер шага является большим, фильтр может стать нестабильным. Чтобы вычислить максимальный размер шага, фильтр может принять, не становясь нестабильным, использовать maxstep функция.
Настраиваемый: да
Это свойство применяется, когда вы устанавливаете StepSizeSource на 'Property'.
Типы данных: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
LeakageFactor — Фактор утечки используется в текучем методе LMS[0 1]Фактор утечки, используемый при реализации текучего метода LMS в виде скаляра в области значений [0 1]. Когда значение равняется 1, в методе адаптации нет никакой утечки. Когда значение меньше 1, фильтр реализует текучий метод LMS.
Пример: 0.5
Настраиваемый: да
Типы данных: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
InitialConditions — Начальные условия весов фильтраНачальные условия весов фильтра в виде скаляра или вектора из длины равняются значению свойства Length. Когда вход действителен, значение этого свойства должно быть действительным.
Пример: 0
Пример: [1 3 1 2 7 8 9 0 2 2 8 2]
Типы данных: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Поддержка комплексного числа: Да
AdaptInputPort — Отметьте, чтобы адаптировать веса фильтраfalse (значение по умолчанию) | trueОтметьте, чтобы адаптировать веса фильтра в виде одного из следующего:
false – Объект постоянно обновляет веса фильтра.
true – Вход управления адаптацией предоставляется объекту, когда вы вызываете его алгоритм. Если значение этого входа является ненулевым, объект постоянно обновляет веса фильтра. Если значение этого входа является нулем, веса фильтра остаются в своем текущем значении.
WeightsResetInputPort — Отметьте, чтобы сбросить веса фильтраfalse (значение по умолчанию) | trueОтметьте, чтобы сбросить веса фильтра в виде одного из следующего:
false – Объект не сбрасывает веса.
true – Вход управления сбросом предоставляется объекту, когда вы вызываете его алгоритм. Эта установка включает свойство WeightsResetCondition. Объект сбрасывает веса фильтра на основе значений WeightsResetCondition свойство и вход сброса предоставляются объектному алгоритму.
WeightsResetCondition — Событие, чтобы сбросить веса фильтра'Non-zero' (значение по умолчанию) | 'Rising edge' | 'Falling edge' | 'Either edge'Событие, которое инициировало сброс весов фильтра в виде одного из следующих. Объект сбрасывает веса фильтра каждый раз, когда событие сброса обнаруживается в его входе сброса.
'Non-zero' – Инициировал операцию сброса на каждой выборке, когда вход сброса не является нулем.
'Rising edge' – Инициировал операцию сброса, когда вход сброса выполняет одно из следующих действий:
Повышения от отрицательной величины или до положительного значения или до нуля.
Повышения от нуля до положительного значения, где повышение не является продолжением повышения от отрицательной величины, чтобы обнулить.
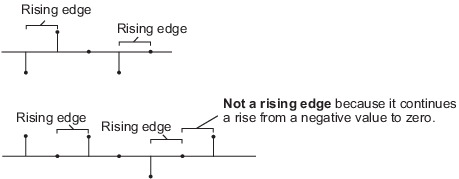
'Falling edge' – Инициировал операцию сброса, когда вход сброса выполняет одно из следующих действий:
Падения от положительного значения до отрицательной величины или нуля.
Падения от нуля до отрицательной величины, где падение не является продолжением падения от положительного значения, чтобы обнулить.
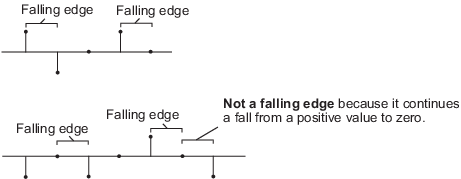
'Either edge' – Инициировал операцию сброса, когда вход сброса является возрастающим ребром или падающим ребром.
Объект сбрасывает веса фильтра на основе значения этого свойства и входа r сброса если к объектному алгоритму.
Это свойство применяется, когда вы устанавливаете свойство WeightsResetInputPort на true.
WeightsOutput — Метод, чтобы вывести адаптированные веса фильтра'Last' (значение по умолчанию) | 'None' | 'All'Метод, чтобы вывести адаптированные веса фильтра в виде одного из следующего:
'Last' (значение по умолчанию) — Объект возвращает вектор-столбец весов, соответствующих последней выборке системы координат данных. Длина вектора весов является значением, данным свойством Length.
'All' — Объект возвращает FrameLength-by-Length матрица весов. Матрица соответствует полной истории выборки выборкой весов для всех выборок FrameLength входных значений. Каждая строка в матрице соответствует набору весов фильтра LMS, вычисленных для соответствующей входной выборки.
'None' — Эта установка отключает веса выход.
RoundingMethod — Округление метода для операций фиксированной точки'Floor' (значение по умолчанию) | 'Ceiling' | 'Convergent' | 'Nearest' | 'Round' | 'Simplest' | 'Zero'Задайте округляющийся режим для операций фиксированной точки. Для получения дополнительной информации смотрите округление режима.
OverflowAction — Действие переполнения для операций фиксированной точки'Wrap' (значение по умолчанию) | 'Saturate'Действие переполнения для операций фиксированной точки в виде одного из следующего:
'Wrap' – Объект переносит результат своих операций фиксированной точки.
'Saturate' – Объект насыщает результат своих операций фиксированной точки.
Для получения дополнительной информации о действиях переполнения смотрите режим переполнения для операций фиксированной точки.
StepSizeDataType — Размер слова размера шага и дробные настройки длины'Same word length as first input' (значение по умолчанию) | 'Custom'Размер слова размера шага и дробные настройки длины в виде одного из следующего:
'Same word length as first input' – Объект задает размер слова размера шага, чтобы совпасть с тем из первого входа. Дробная длина вычисляется, чтобы получить самую лучшую точность.
'Custom' – Тип данных размера шага задан как пользовательский числовой тип через свойство CustomStepSizeDataType.
Для получения дополнительной информации о типе данных размера шага этот объект использование смотрите раздел Fixed Point.
CustomStepSizeDataType — Word и дробные длины размера шагаnumerictype([],16,15) (значение по умолчанию)Word и дробные длины размера шага в виде числового типа автосо знаком с размером слова 16 и дробная длина 15.
Пример: numerictype ([], 32)
Это свойство применяется при следующих условиях:
Набор свойств StepSizeSource к 'Property' и StepSizeDataType устанавливают на 'Custom'.
StepSizeSource набор свойств к 'Input port'.
LeakageFactorDataType — Размер слова фактора утечки и дробные настройки длины'Same word length as first input' (значение по умолчанию) | 'Custom'Размер слова фактора утечки и дробные настройки длины в виде одного из следующего:
'Same word length as first input' – Объект задает размер слова фактора утечки, чтобы совпасть с тем из первого входа. Дробная длина вычисляется, чтобы получить самую лучшую точность.
'Custom' – Тип данных фактора утечки задан как пользовательский числовой тип через свойство CustomLeakageFactorDataType.
Для получения дополнительной информации о типе данных фактора утечки этот объект использование смотрите раздел Fixed Point.
CustomLeakageFactorDataType — Word и дробные продолжительности фактора утечкиnumerictype([],16,15) (значение по умолчанию)Word и дробные продолжительности фактора утечки в виде числового типа автосо знаком с размером слова 16 и дробная длина 15.
Пример: numerictype ([], 32)
Это свойство применяется, когда вы устанавливаете свойство LeakageFactorDataType на 'Custom'.
WeightsDataType — Размер слова весов и дробные настройки длины'Same as first input' (значение по умолчанию) | 'Custom'Размер слова весов и дробные настройки длины в виде одного из следующего:
'Same as first input' – Объект задает тип данных весов фильтра, чтобы совпасть с тем из первого входа.
'Custom' – Тип данных весов фильтра задан как пользовательский числовой тип через свойство CustomWeightsDataType.
Для получения дополнительной информации о типе данных весов фильтра этот объект использование смотрите раздел Fixed Point.
CustomWeightsDataType — Word и дробные длины весов фильтраnumerictype([],16,15) (значение по умолчанию)Word и дробные длины весов фильтра в виде числового типа автосо знаком с размером слова 16 и дробная длина 15.
Пример: numerictype ([], 32,20)
Это свойство применяется, когда вы устанавливаете свойство WeightsDataType на 'Custom'.
EnergyProductDataType — Размер слова энергетического продукта и дробные настройки длины'Same as first input' (значение по умолчанию) | 'Custom'Размер слова энергетического продукта и дробные настройки длины в виде одного из следующего:
'Same as first input' – Объект задает тип данных энергетического продукта, чтобы совпасть с тем из первого входа.
'Custom' – Тип данных энергетического продукта задан как пользовательский числовой тип через свойство CustomEnergyProductDataType.
Для получения дополнительной информации о типе данных энергетического продукта этот объект использование смотрите раздел Fixed Point.
Это свойство применяется, когда вы устанавливаете свойство Method на 'Normalized LMS'.
CustomEnergyProductDataType — Word и дробные длины энергетического продуктаnumerictype([],32,20) (значение по умолчанию)Word и дробные длины энергетического продукта в виде числового типа автосо знаком с размером слова 32 и дробная длина 20.
Это свойство применяется, когда вы устанавливаете свойство Method на 'Normalized LMS' и свойство EnergyProductDataType к 'Custom'.
EnergyAccumulatorDataType — Энергетический размер слова аккумулятора и дробные настройки длины'Same as first input' (значение по умолчанию) | 'Custom'Энергетический размер слова аккумулятора и дробные настройки длины в виде одного из следующего:
'Same as first input' – Объект задает тип данных энергетического аккумулятора, чтобы совпасть с тем из первого входа.
'Custom' – Тип данных энергетического аккумулятора задан как пользовательский числовой тип через свойство CustomEnergyAccumulatorDataType.
Для получения дополнительной информации об энергетическом типе данных аккумулятора этот объект использование смотрите раздел Fixed Point.
Это свойство применяется, когда вы устанавливаете свойство Method на 'Normalized LMS'.
CustomEnergyAccumulatorDataType — Word и дробные длины энергетического аккумулятораnumerictype([],32,20) (значение по умолчанию)Word и дробные длины энергетического аккумулятора в виде числового типа автосо знаком с размером слова 32 и дробная длина 20.
Это свойство применяется, когда вы устанавливаете свойство Method на 'Normalized LMS' и свойство EnergyAccumulatorDataType к 'Custom'.
ConvolutionProductDataType — Размер слова продукта свертки и дробные настройки длины'Same as first input' (значение по умолчанию) | 'Custom'Размер слова продукта свертки и дробные настройки длины в виде одного из следующего:
'Same as first input' – Объект задает тип данных продукта свертки, чтобы совпасть с тем из первого входа.
'Custom' – Тип данных продукта свертки задан как пользовательский числовой тип через свойство CustomConvolutionProductDataType.
Для получения дополнительной информации о типе данных продукта свертки этот объект использование смотрите раздел Fixed Point.
CustomConvolutionProductDataType — Word и дробные длины продукта сверткиnumerictype([],32,20) (значение по умолчанию)Word и дробные длины продукта свертки в виде числового типа автосо знаком с размером слова 32 и дробная длина 20.
Это свойство применяется, когда вы устанавливаете свойство ConvolutionProductDataType на 'Custom'.
ConvolutionAccumulatorDataType — Размер слова аккумулятора свертки и дробные настройки длины'Same as first input' (значение по умолчанию) | 'Custom'Размер слова аккумулятора свертки и дробные настройки длины в виде одного из следующего:
'Same as first input' – Объект задает тип данных аккумулятора свертки, чтобы совпасть с тем из первого входа.
'Custom' – Тип данных аккумулятора свертки задан как пользовательский числовой тип через свойство CustomConvolutionAccumulatorDataType.
Для получения дополнительной информации о типе данных аккумулятора свертки этот объект использование смотрите раздел Fixed Point.
CustomConvolutionAccumulatorDataType — Word и дробные длины аккумулятора сверткиnumerictype([],32,20) (значение по умолчанию)Word и дробные длины аккумулятора свертки в виде числового типа автосо знаком с размером слова 32 и дробная длина 20.
Это свойство применяется, когда вы устанавливаете свойство ConvolutionAccumulatorDataType на 'Custom'.
StepSizeErrorProductDataType — Ошибочный размер слова продукта размера шага и дробные настройки длины'Same as first input' (значение по умолчанию) | 'Custom'Ошибочный размер слова продукта размера шага и дробные настройки длины в виде одного из следующего:
'Same as first input' – Объект задает тип данных ошибочного продукта размера шага, чтобы совпасть с тем из первого входа.
'Custom' – Тип данных ошибочного продукта размера шага задан как пользовательский числовой тип через свойство CustomStepSizeErrorProductDataType.
Для получения дополнительной информации об ошибочном типе данных продукта размера шага этот объект использование смотрите раздел Fixed Point.
CustomStepSizeErrorProductDataType — Word и дробные длины ошибочного продукта размера шагаnumerictype([],32,20) (значение по умолчанию)Word и дробные длины ошибочного продукта размера шага в виде числового типа автосо знаком с размером слова 32 и дробная длина 20.
Это свойство применяется, когда вы устанавливаете свойство StepSizeErrorProductDataType на 'Custom'.
WeightsUpdateProductDataType — Отфильтруйте размер слова продукта обновления весов и дробные настройки длины'Same as first input' (значение по умолчанию) | 'Custom'Word и дробные настройки длины весов фильтра обновляют продукт в виде одного из следующего:
'Same as first input' – Объект указывает, что тип данных весов фильтра обновляет продукт, чтобы совпасть с тем из первого входа.
'Custom' – Тип данных весов фильтра обновляется, продукт задан как пользовательский числовой тип через свойство CustomWeightsUpdateProductDataType.
Для получения дополнительной информации о фильтре веса обновляют тип данных продукта этот объект использование, видят раздел Fixed Point.
CustomWeightsUpdateProductDataType — Word и дробные длины весов фильтра обновляют продуктnumerictype([],32,20) (значение по умолчанию)Word и дробные длины весов фильтра обновляют продукт в виде числового типа автосо знаком с размером слова 32 и дробной длиной 20.
Это свойство применяется, когда вы устанавливаете свойство WeightsUpdateProductDataType на 'Custom'.
QuotientDataType — Размер слова частного и дробные настройки длины'Same as first input' (значение по умолчанию) | 'Custom'Размер слова частного и дробные настройки длины в виде одного из следующего:
'Same as first input' – Объект задает тип данных частного, чтобы совпасть с тем из первого входа.
'Custom' – Тип данных частного задан как пользовательский числовой тип через свойство CustomQuotientDataType.
Для получения дополнительной информации о типе данных частного этот объект использование смотрите раздел Fixed Point.
Это свойство применяется, когда вы устанавливаете свойство Method на 'Normalized LMS'.
CustomQuotientDataType — Word и дробные длины частногоnumerictype([],32,20) (значение по умолчанию)Word и дробные длины весов фильтра обновляют продукт в виде числового типа автосо знаком с размером слова 32 и дробной длиной 20.
Это свойство применяется, когда вы устанавливаете свойство Method на 'Normalized LMS' и свойство QuotientDataType к 'Custom'.
[ фильтрует входной сигнал, y,err,wts] = lms(x,d)x, использование d как желаемый сигнал, и возвращает отфильтрованный выходной параметр в y, ошибка фильтра в err, и предполагаемые веса фильтра в wts. Объект фильтра LMS оценивает, что веса фильтра должны были минимизировать ошибку между выходным сигналом и желаемым сигналом.
[ фильтрует входной сигнал, y,err] = lms(x,d)x, использование d как желаемый сигнал, и возвращает отфильтрованный выходной параметр в y и ошибка фильтра в err когда свойство WeightsOutput установлено в 'None'.
[___] = lms( фильтрует входной сигнал, x,d,mu)x, использование d как желаемый сигнал и mu как размер шага, когда свойство StepSizeSource установлено в 'Input port'. Эти входные параметры могут использоваться с любым из предыдущих наборов выходных параметров.
[___] = lms( фильтрует входной сигнал, x,d,a)x, использование d как желаемый сигнал и a как управление адаптацией, когда свойство AdaptInputPort установлено в true. Когда a является ненулевым, Системный объект постоянно обновляет веса фильтра. Когда a нуль, веса фильтра остаются постоянными.
[___] = lms( фильтрует входной сигнал, x,d,r)x, использование d как желаемый сигнал и r как сброс сигнализируют, когда свойство WeightsResetInputPort установлено в true. Свойство WeightsResetCondition может использоваться, чтобы установить триггерное условие сброса. Если событие сброса происходит, Системный объект сбрасывает веса фильтра к их начальным значениям.
Чтобы использовать объектную функцию, задайте Системный объект как первый входной параметр. Например, чтобы выпустить системные ресурсы Системного объекта под названием obj, используйте этот синтаксис:
release(obj)
Среднеквадратическая ошибка (MSE) измеряет среднее значение квадратов ошибок между желаемым сигналом и первичным входом сигнала к адаптивному фильтру. Сокращение этой ошибки сходится первичный входной параметр к желаемому сигналу. Определите ожидаемое значение MSE и симулированное значение MSE в каждый раз мгновенное использование msepred и msesim функции. Сравните эти значения MSE друг с другом и относительно минимального MSE и установившихся значений MSE. Кроме того, вычислите сумму квадратов содействующих ошибок, данных трассировкой содействующей ковариационной матрицы.
Примечание: Если вы используете R2016a или более ранний релиз, заменяете каждый вызов объекта с эквивалентным синтаксисом шага. Например, obj(x) становится step(obj,x).
Инициализация
Создайте dsp.FIRFilter Система object™, который представляет неизвестную систему. Передайте сигнал, x, к КИХ-фильтру. Выход неизвестной системы является желаемым сигналом, d, который является суммой выхода неизвестной системы (КИХ-фильтр) и аддитивный шумовой сигнал, n.
num = fir1(31,0.5); fir = dsp.FIRFilter('Numerator',num); iir = dsp.IIRFilter('Numerator',sqrt(0.75),... 'Denominator',[1 -0.5]); x = iir(sign(randn(2000,25))); n = 0.1*randn(size(x)); d = fir(x) + n;
Фильтр LMS
Создайте dsp.LMSFilter Системный объект, чтобы создать фильтр, который адаптируется, чтобы вывести желаемый сигнал. Установите длину адаптивного фильтра к 32 касаниям, размера шага к 0,008, и фактор децимации для анализа и симуляции к 5. Переменная simmse представляет симулированный MSE между выходом неизвестной системы, d, и выход адаптивного фильтра. Переменная mse дает соответствующее ожидаемое значение.
l = 32; mu = 0.008; m = 5; lms = dsp.LMSFilter('Length',l,'StepSize',mu); [mmse,emse,meanW,mse,traceK] = msepred(lms,x,d,m); [simmse,meanWsim,Wsim,traceKsim] = msesim(lms,x,d,m);
Постройте результаты MSE
Сравните значения симулированного MSE, предсказал MSE, минимальный MSE и итоговый MSE. Итоговое значение MSE дано суммой минимального MSE и избыточного MSE.
nn = m:m:size(x,1); semilogy(nn,simmse,[0 size(x,1)],[(emse+mmse)... (emse+mmse)],nn,mse,[0 size(x,1)],[mmse mmse]) title('Mean Squared Error Performance') axis([0 size(x,1) 0.001 10]) legend('MSE (Sim.)','Final MSE','MSE','Min. MSE') xlabel('Time Index') ylabel('Squared Error Value')

Предсказанный MSE следует за той же траекторией как симулированный MSE. Обе этих траектории сходятся с установившимся (итоговым) MSE.
Постройте содействующие траектории
meanWsim среднее значение симулированных коэффициентов, данных msesim. meanW среднее значение предсказанных коэффициентов, данных msepred.
Сравните симулированные и предсказанные средние значения коэффициентов фильтра LMS 12,13,14, и 15.
plot(nn,meanWsim(:,12),'b',nn,meanW(:,12),'r',nn,... meanWsim(:,13:15),'b',nn,meanW(:,13:15),'r') PlotTitle ={'Average Coefficient Trajectories for';... 'W(12), W(13), W(14), and W(15)'}
PlotTitle = 2x1 cell
{'Average Coefficient Trajectories for'}
{'W(12), W(13), W(14), and W(15)' }
title(PlotTitle) legend('Simulation','Theory') xlabel('Time Index') ylabel('Coefficient Value')

В устойчивом состоянии оба сходятся траектории.
Сумма содействующих ошибок в квадрате
Сравните сумму содействующих ошибок в квадрате, данных msepred и msesim. Эти значения даны трассировкой содействующей ковариационной матрицы.
semilogy(nn,traceKsim,nn,traceK,'r') title('Sum-of-Squared Coefficient Errors') axis([0 size(x,1) 0.0001 1]) legend('Simulation','Theory') xlabel('Time Index') ylabel('Squared Error Value')

maxstep функция вычисляет максимальный размер шага адаптивного фильтра. Этот размер шага сохраняет стабильность фильтра в максимальной возможной быстроте сходимости. Создайте сигнал первичного входного параметра, x, путем передачи случайного сигнала со знаком БИХ-фильтру. x сигнала содержит 50 систем координат 2 000 выборок каждая система координат. Создайте фильтр LMS с 32 касаниями и размером шага 0,1.
x = zeros(2000,50); IIRFilter = dsp.IIRFilter('Numerator',sqrt(0.75),... 'Denominator',[1 -0.5]); for k = 1:size(x,2) x(:,k) = IIRFilter(sign(randn(size(x,1),1))); end mu = 0.1; LMSFilter = dsp.LMSFilter('Length',32,... 'StepSize',mu);
Вычислите максимальный размер шага адаптации и максимальный размер шага в среднеквадратическом смысле с помощью maxstep функция.
[mumax,mumaxmse] = maxstep(LMSFilter,x)
mumax = 0.0625
mumaxmse = 0.0536
Система идентификации является процессом идентификации коэффициентов неизвестной системы с помощью адаптивного фильтра. Общий обзор процесса, как показывают, в System Identification – Используя Адаптивный Фильтр Идентифицирует Неизвестную Систему. Основные включенные компоненты:
Адаптивный алгоритм фильтра. В этом примере, набор Method свойство dsp.LMSFilter к 'LMS' выбрать адаптивный алгоритм фильтра LMS.
Неизвестная система или процесс, чтобы адаптироваться к. В этом примере фильтр спроектирован fircband неизвестная система.
Соответствующие входные данные, чтобы осуществить процесс адаптации. Для типовой модели LMS это желаемый сигнал и входной сигнал .
Цель адаптивного фильтра состоит в том, чтобы минимизировать сигнал ошибки между выходом адаптивного фильтра и выход неизвестной системы (или системы, которая будет идентифицирована) . Если сигнал ошибки минимизирован, адаптированный фильтр напоминает неизвестную систему. Коэффициенты обоих фильтры соответствуют тесно.
Примечание: Если вы используете R2016a или более ранний релиз, заменяете каждый вызов объекта с эквивалентным синтаксисом шага. Например, obj(x) становится step(obj,x).
Неизвестная система
Создайте dsp.FIRFilter объект, который представляет систему, которая будет идентифицирована. Используйте fircband функционируйте, чтобы спроектировать коэффициенты фильтра. Спроектированный фильтр является фильтром lowpass, ограниченным к 0,2 пульсациям в полосе задерживания.
filt = dsp.FIRFilter; filt.Numerator = fircband(12,[0 0.4 0.5 1],[1 1 0 0],[1 0.2],... {'w' 'c'});
Передайте x сигнала к КИХ-фильтру. Желаемый d сигнала сумма выхода неизвестной системы (КИХ-фильтр), и аддитивный шум сигнализируют о n.
x = 0.1*randn(250,1); n = 0.01*randn(250,1); d = filt(x) + n;
Адаптивный фильтр
С неизвестным спроектированным фильтром и желаемый сигнал на месте, создайте и примените адаптивный объект фильтра LMS, чтобы идентифицировать неизвестный фильтр.
Подготовка адаптивного объекта фильтра требует начальных значений для оценок коэффициентов фильтра и размера шага LMS (mu). Можно начать с некоторого набора ненулевых значений как оценки для коэффициентов фильтра. Этот пример использует нули для 13 начальных весов фильтра. Установите InitialConditions свойство dsp.LMSFilter к желаемым начальным значениям весов фильтра. Для размера шага, 0.8 хороший компромисс между тем, чтобы быть достаточно большим, чтобы сходиться хорошо в 250 итерациях (250 входных точек выборки) и достаточно маленький, чтобы создать точную оценку неизвестного фильтра.
Создайте dsp.LMSFilter объект представлять адаптивный фильтр, который использует адаптивный алгоритм LMS. Установите длину адаптивного фильтра к 13 касаниям и размера шага к 0,8.
mu = 0.8;
lms = dsp.LMSFilter(13,'StepSize',mu)lms =
dsp.LMSFilter with properties:
Method: 'LMS'
Length: 13
StepSizeSource: 'Property'
StepSize: 0.8000
LeakageFactor: 1
InitialConditions: 0
AdaptInputPort: false
WeightsResetInputPort: false
WeightsOutput: 'Last'
Show all properties
Передайте сигнал первичного входного параметра x и желаемый d сигнала к фильтру LMS. Запустите адаптивный фильтр, чтобы определить неизвестную систему. Выход y из адаптивного фильтра сигнал, сходившийся к желаемому сигналу d, таким образом, минимизирующему ошибку e между двумя сигналами.
Постройте график результатов. Выходной сигнал не совпадает с желаемым сигналом как ожидалось, совершая ошибку между нетривиальными двумя.
[y,e,w] = lms(x,d); plot(1:250, [d,y,e]) title('System Identification of an FIR filter') legend('Desired','Output','Error') xlabel('Time index') ylabel('Signal value')

Сравните веса
Вектор весов w представляет коэффициенты фильтра LMS, который адаптируется, чтобы напомнить неизвестную систему (КИХ-фильтр). Чтобы подтвердить сходимость, сравните числитель КИХ-фильтра и предполагаемые веса адаптивного фильтра.
Предполагаемые веса фильтра тесно не совпадают с фактическими весами фильтра, подтверждая результаты, замеченные в предыдущем графике сигнала.
stem([(filt.Numerator).' w]) title('System Identification by Adaptive LMS Algorithm') legend('Actual filter weights','Estimated filter weights',... 'Location','NorthEast')

Изменение размера шага
Как эксперимент, измените размер шага в 0,2. Повторение примера с mu = 0.2 результаты в следующей диаграмме стебель-листья. Фильтры не сходятся, и предполагаемые веса не являются хорошим approxmations фактического веса.
mu = 0.2; lms = dsp.LMSFilter(13,'StepSize',mu); [~,~,w] = lms(x,d); stem([(filt.Numerator).' w]) title('System Identification by Adaptive LMS Algorithm') legend('Actual filter weights','Estimated filter weights',... 'Location','NorthEast')

Увеличьте число выборок данных
Увеличьте формат кадра желаемого сигнала. Даже при том, что это увеличивает включенный расчет, LMS-алгоритм теперь имеет больше данных, которые могут использоваться для адаптации. С 1 000 выборок данных сигнала и размером шага 0,2, коэффициенты выравниваются ближе, чем прежде, указывая на улучшенную сходимость.
release(filt); x = 0.1*randn(1000,1); n = 0.01*randn(1000,1); d = filt(x) + n; [y,e,w] = lms(x,d); stem([(filt.Numerator).' w]) title('System Identification by Adaptive LMS Algorithm') legend('Actual filter weights','Estimated filter weights',... 'Location','NorthEast')

Увеличьте число выборок данных далее путем введения данных через итерации. Запустите алгоритм на 4 000 выборок данных, переданных LMS-алгоритму в пакетах 1 000 выборок более чем 4 итерации.
Сравните веса фильтра. Веса фильтра LMS совпадают с весами КИХ-фильтра очень тесно, указывая на хорошую сходимость.
release(filt); n = 0.01*randn(1000,1); for index = 1:4 x = 0.1*randn(1000,1); d = filt(x) + n; [y,e,w] = lms(x,d); end stem([(filt.Numerator).' w]) title('System Identification by Adaptive LMS Algorithm') legend('Actual filter weights','Estimated filter weights',... 'Location','NorthEast')

Выходной сигнал совпадает с желаемым сигналом очень тесно, совершая ошибку между двумя близко к нулю.
plot(1:1000, [d,y,e]) title('System Identification of an FIR filter') legend('Desired','Output','Error') xlabel('Time index') ylabel('Signal value')

Чтобы улучшать производительность сходимости LMS-алгоритма, нормированный вариант (NLMS) использует адаптивный размер шага на основе степени сигнала. Когда степень входного сигнала изменяется, алгоритм вычисляет входную мощность и настраивает размер шага, чтобы обеспечить соответствующее значение. Изменения размера шага со временем, и в результате нормированный алгоритм сходятся быстрее с меньшим количеством выборок во многих случаях. Для входных сигналов, которые изменяются медленно в зависимости от времени, нормированный LMS-алгоритм может быть более эффективным подходом LMS.
Для примера с помощью подхода LMS смотрите System Identification КИХ-Фильтра Используя LMS-алгоритм.
Примечание: Если вы используете R2016a или более ранний релиз, заменяете каждый вызов объекта с эквивалентным синтаксисом шага. Например, obj(x) становится step(obj,x).
Неизвестная система
Создайте dsp.FIRFilter объект, который представляет систему, которая будет идентифицирована. Используйте fircband функционируйте, чтобы спроектировать коэффициенты фильтра. Спроектированный фильтр является фильтром lowpass, ограниченным к 0,2 пульсациям в полосе задерживания.
filt = dsp.FIRFilter; filt.Numerator = fircband(12,[0 0.4 0.5 1],[1 1 0 0],[1 0.2],... {'w' 'c'});
Передайте x сигнала к КИХ-фильтру. Желаемый d сигнала сумма выхода неизвестной системы (КИХ-фильтр), и аддитивный шум сигнализируют о n.
x = 0.1*randn(1000,1); n = 0.001*randn(1000,1); d = filt(x) + n;
Адаптивный фильтр
Чтобы использовать нормированное изменение LMS-алгоритма, установите Method свойство на dsp.LMSFilter к 'Normalized LMS'. Установите длину адаптивного фильтра к 13 касаниям и размера шага к 0,2.
mu = 0.2; lms = dsp.LMSFilter(13,'StepSize',mu,'Method',... 'Normalized LMS');
Передайте сигнал первичного входного параметра x и желаемый d сигнала к фильтру LMS.
[y,e,w] = lms(x,d);
Выход y из адаптивного фильтра сигнал, сходившийся к желаемому сигналу d, таким образом, минимизирующему ошибку e между двумя сигналами.
plot(1:1000, [d,y,e]) title('System Identification by Normalized LMS Algorithm') legend('Desired','Output','Error') xlabel('Time index') ylabel('Signal value')

Сравните адаптированный фильтр с неизвестной системой
Вектор весов w представляет коэффициенты фильтра LMS, который адаптируется, чтобы напомнить неизвестную систему (КИХ-фильтр). Чтобы подтвердить сходимость, сравните числитель КИХ-фильтра и предполагаемые веса адаптивного фильтра.
stem([(filt.Numerator).' w]) title('System Identification by Normalized LMS Algorithm') legend('Actual filter weights','Estimated filter weights',... 'Location','NorthEast')

Адаптивный фильтр адаптирует свои коэффициенты фильтра, чтобы совпадать с коэффициентами неизвестной системы. Цель состоит в том, чтобы минимизировать сигнал ошибки между выходом неизвестной системы и выходом адаптивного фильтра. Когда эти два выходных параметров сходятся и соответствуют тесно для того же входа, коэффициенты, как говорят, соответствуют тесно. Адаптивный фильтр в этом состоянии напоминает неизвестную систему. Этот пример сравнивает уровень, на котором эта сходимость происходит для нормированного LMS (NLMS) алгоритм и LMS-алгоритм без нормализации.
Неизвестная система
Создайте dsp.FIRFilter это представляет неизвестную систему. Передайте x сигнала как вход к неизвестной системе. Желаемый d сигнала сумма выхода неизвестной системы (КИХ-фильтр), и аддитивный шум сигнализируют о n.
filt = dsp.FIRFilter; filt.Numerator = fircband(12,[0 0.4 0.5 1],[1 1 0 0],[1 0.2],... {'w' 'c'}); x = 0.1*randn(1000,1); n = 0.001*randn(1000,1); d = filt(x) + n;
Адаптивный фильтр
Создайте два dsp.LMSFilter объекты, с одним набором к LMS-алгоритму и другим набором к нормированному LMS-алгоритму. Выберите размер шага адаптации 0,2 и установите длину адаптивного фильтра к 13 касаниям.
mu = 0.2; lms_nonnormalized = dsp.LMSFilter(13,'StepSize',mu,... 'Method','LMS'); lms_normalized = dsp.LMSFilter(13,'StepSize',mu,... 'Method','Normalized LMS');
Передайте сигнал первичного входного параметра x и желаемый d сигнала обоим изменения LMS-алгоритма. Переменные e1 и e2 представляйте ошибку между желаемым сигналом и выходом нормированных и ненормированных фильтров, respecitvely.
[~,e1,~] = lms_normalized(x,d); [~,e2,~] = lms_nonnormalized(x,d);
Постройте сигналы ошибки для обоих изменений. Сигнал ошибки для варианта NLMS сходится, чтобы обнулить намного быстрее, чем сигнал ошибки для варианта LMS. Нормированная версия адаптируется в гораздо меньшем количестве итераций к результату, почти столь же хорошему как ненормированная версия.
plot([e1,e2]); title('Comparing the LMS and NLMS Conversion Performance'); legend('NLMS derived filter weights', ... 'LMS derived filter weights','Location', 'NorthEast'); xlabel('Time index') ylabel('Signal value')

Отмените аддитивный шум, n, добавленный к неизвестной системе с помощью адаптивного фильтра LMS. Фильтр LMS адаптирует свои коэффициенты, пока его передаточная функция не совпадает с передаточной функцией неизвестной системы максимально тесно. Различие между выходом адаптивного фильтра и выходом неизвестной системы представляет сигнал ошибки, e. Минимизация этого сигнала ошибки является целью адаптивного фильтра.
Неизвестная система и фильтр LMS обрабатывают тот же входной сигнал, x, и произведите выходные параметры d и y, соответственно. Если коэффициенты адаптивного фильтра совпадают с коэффициентами неизвестной системы, ошибки, e, в действительности представляет аддитивный шум.
Примечание: Если вы используете R2016a или более ранний релиз, заменяете каждый вызов объекта с эквивалентным синтаксисом шага. Например, obj(x) становится step(obj,x).
Создайте dsp.FIRFilter Системный объект, чтобы представлять неизвестную систему. Создайте dsp.LMSFilter объект и набор длина к 11 касаниям и размер шага к 0,05. Создайте синусоиду, чтобы представлять шум, добавленный к неизвестной системе. Просмотрите сигналы в осциллографе времени.
FrameSize = 100; NIter = 10; lmsfilt2 = dsp.LMSFilter('Length',11,'Method','Normalized LMS', ... 'StepSize',0.05); firfilt2 = dsp.FIRFilter('Numerator', fir1(10,[.5, .75])); sinewave = dsp.SineWave('Frequency',0.01, ... 'SampleRate',1,'SamplesPerFrame',FrameSize); scope = timescope('TimeUnits','Seconds',... 'YLimits',[-3 3],'BufferLength',2*FrameSize*NIter, ... 'ShowLegend',true,'ChannelNames', ... {'Noisy signal', 'Error signal'});
Создайте случайный входной сигнал, x и передайте сигнал КИХ-фильтру. Добавьте синусоиду в выход КИХ-фильтра, чтобы сгенерировать сигнал с шумом, d. Сигналом, d является выход неизвестной системы. Передайте сигнал с шумом и сигнал первичного входного параметра к фильтру LMS. Просмотрите сигнал с шумом и сигнал ошибки в осциллографе времени.
for k = 1:NIter x = randn(FrameSize,1); d = firfilt2(x) + sinewave(); [y,e,w] = lmsfilt2(x,d); scope([d,e]) end release(scope)

Сигнал ошибки, e, синусоидальный шум, добавленный к неизвестной системе. Минимизация сигнала ошибки минимизирует шум, добавленный к системе.
Когда объем расчета, требуемого выводить адаптивный фильтр, управляет вашим процессом разработки, вариантом данных знака LMS (SDLMS) алгоритм может быть очень хороший выбор, как продемонстрировано в этом примере.
В стандартных и нормированных изменениях адаптивного фильтра LMS коэффициенты для адаптирующегося фильтра являются результатом среднеквадратичной погрешности между желаемым сигналом и выходным сигналом неизвестной системы. Алгоритм данных знака изменяет вычисление среднеквадратичной погрешности при помощи знака входных данных изменить коэффициенты фильтра.
Когда ошибка положительна, новые коэффициенты являются предыдущими коэффициентами плюс ошибка, умноженная на размер шага µ. Если ошибка отрицательна, новые коэффициенты являются снова предыдущими коэффициентами минус ошибка, умноженная на µ — обращают внимание на изменения знака.
Когда вход является нулем, новые коэффициенты совпадают с предыдущим набором.
В векторной форме LMS-алгоритм данных знака:
где
с вектором содержание весов применилось к коэффициентам фильтра и вектору содержа входные данные. Вектор ошибка между желаемым сигналом и отфильтрованным сигналом. Цель алгоритма SDLMS состоит в том, чтобы минимизировать эту ошибку. Размер шага представлен .
С меньшим , коррекция к весам фильтра становится меньшей для каждой выборки, и ошибка SDLMS падает более медленно. Большее изменяет веса больше для каждого шага, таким образом, ошибка падает более быстро, но получившаяся ошибка не приближается к идеальному решению как тесно. Чтобы гарантировать хороший уровень сходимости и устойчивость, выбрать в следующих практических границах.
где количество отсчетов в сигнале. Кроме того, задайте как степень двойки для эффективного вычисления.
Примечание: Как вы устанавливаете начальные условия алгоритма данных знака, глубоко влияет на эффективность процесса адаптации. Поскольку алгоритм по существу квантует входной сигнал, алгоритм может стать нестабильным легко.
Серия больших входных значений, вместе с процессом квантования может привести к ошибке при росте вне всех границ. Ограничьте тенденцию алгоритма данных знака выйти из-под контроля путем выбора размера небольшого шага и устанавливание начальных условий для алгоритма к ненулевым положительным и отрицательным величинам.
В этом примере подавления помех, набор Method свойство dsp.LMSFilter к 'Sign-Data LMS'. Этот пример требует двух наборов входных данных:
Данные, содержащие сигнал, повреждаются шумом. В блок-схеме при Шумовой или Интерференционной Отмене – Используя Адаптивный Фильтр, чтобы Удалить Шум из Неизвестной Системы, это - желаемый сигнал . Процесс подавления помех удаляет шум из сигнала.
Данные, содержащие случайный шум. В блок-схеме при Шумовой или Интерференционной Отмене – Используя Адаптивный Фильтр, чтобы Удалить Шум из Неизвестной Системы, это . Сигнал коррелируется с шумом, который повреждает данные сигнала. Без корреляции между шумовыми данными адаптирующийся алгоритм не может удалить шум из сигнала.
Для сигнала используйте синусоиду. Обратите внимание на то, что signal вектор-столбец 1 000 элементов.
signal = sin(2*pi*0.055*(0:1000-1)');
Теперь добавьте коррелируемый белый шум в signal. Чтобы гарантировать, что шум коррелируется, передайте шум через КИХ lowpass, фильтруют и затем добавляют отфильтрованный шум в сигнал.
noise = randn(1000,1); filt = dsp.FIRFilter; filt.Numerator = fir1(11,0.4); fnoise = filt(noise); d = signal + fnoise;
fnoise коррелированый шум и d теперь желаемый вход к алгоритму данных знака.
Подготовить dsp.LMSFilter объект для обработки, установленный начальные условия весов фильтра и mu Неродной размер). Как отмечено ранее в этом разделе, значения вы устанавливаете для coeffs и mu определите, может ли адаптивный фильтр удалить шум из пути прохождения сигнала.
В System Identification КИХ-Фильтра Используя LMS-алгоритм вы создали фильтр по умолчанию, который устанавливает коэффициенты фильтра на нули. В большинстве случаев тот подход не работает на алгоритм данных знака. Чем ближе вы устанавливаете свои начальные коэффициенты фильтра на ожидаемые значения, тем более вероятно случается так, что алгоритм остается хорошего поведения и сходится к решению для фильтра, которое удаляет шум эффективно.
В данном примере начните с коэффициентов, используемых в шумовом фильтре (filt.Numerator), и измените их немного, таким образом, алгоритм должен адаптироваться.
coeffs = (filt.Numerator).'-0.01; % Set the filter initial conditions. mu = 0.05; % Set the step size for algorithm updating.
С необходимыми входными параметрами для dsp.LMSFilter подготовленный, создайте объект фильтра LMS, запустите адаптацию и просмотрите результаты.
lms = dsp.LMSFilter(12,'Method','Sign-Data LMS',... 'StepSize',mu,'InitialConditions',coeffs); [~,e] = lms(noise,d); L = 200; plot(0:L-1,signal(1:L),0:L-1,e(1:L)); title('Noise Cancellation by the Sign-Data Algorithm'); legend('Actual signal','Result of noise cancellation',... 'Location','NorthEast'); xlabel('Time index') ylabel('Signal values')

Когда dsp.LMSFilter запуски, это использует гораздо меньше операций умножения, чем любой из стандартных LMS-алгоритмов. Кроме того, выполнение адаптации данных знака требует только умножения переменой бита, когда размер шага является степенью двойки.
Несмотря на то, что эффективность алгоритма данных знака как показано в этом графике довольно хороша, алгоритм данных знака намного менее устойчив, чем стандартные изменения LMS. В этом примере подавления помех обработанный сигнал является очень хорошим соответствием к входному сигналу, но алгоритм мог очень легко вырасти без связанного, а не достигнуть хорошей эффективности.
Изменение начальных условий веса (InitialConditions) и mu Неродной размер), или даже lowpass фильтрует вас, раньше создавал коррелированый шум, может заставить подавление помех перестать работать.
В стандартных и нормированных изменениях адаптивного фильтра LMS коэффициенты для адаптирующегося фильтра являются результатом вычисления среднеквадратичной погрешности между желаемым сигналом и выходным сигналом неизвестной системы и применением результата к текущим коэффициентам фильтра. Ошибка знака LMS (SELMS) алгоритм заменяет вычисление среднеквадратичной погрешности при помощи знака ошибки изменить коэффициенты фильтра.
Когда ошибка положительна, новые коэффициенты являются предыдущими коэффициентами плюс ошибка, умноженная на размер шага . Если ошибка отрицательна, новые коэффициенты являются предыдущими коэффициентами минус ошибка, умноженная на — обратите внимание на изменения знака. Когда вход является нулем, новые коэффициенты совпадают с предыдущим набором.
В векторной форме LMS-алгоритм ошибки знака:
,
где
с вектором содержание весов применилось к коэффициентам фильтра и вектору содержа входные данные. Вектор ошибка между желаемым сигналом и отфильтрованным сигналом. Цель алгоритма SELMS состоит в том, чтобы минимизировать эту ошибку.
С меньшим , коррекция к весам фильтра становится меньшей для каждой выборки, и ошибка SELMS падает более медленно. Большее изменяет веса больше для каждого шага, таким образом, ошибка падает более быстро, но получившаяся ошибка не приближается к идеальному решению как тесно. Чтобы гарантировать хороший уровень сходимости и устойчивость, выбрать в следующих практических границах.
где количество отсчетов в сигнале. Кроме того, задайте как степень двойки для эффективного расчета.
Примечание: Как вы устанавливаете начальные условия алгоритма ошибки знака, глубоко влияет на эффективность процесса адаптации. Поскольку алгоритм по существу квантует сигнал ошибки, алгоритм может стать нестабильным легко.
Серия больших ошибочных значений, вместе с процессом квантования может привести к ошибке при росте вне всех границ. Ограничьте тенденцию алгоритма ошибки знака стать нестабильными путем выбора размера небольшого шага и устанавливание начальных условий для алгоритма к ненулевым положительным и отрицательным величинам.
В этом примере подавления помех, набор Method свойство dsp.LMSFilter к 'Sign-Error LMS'. Этот пример требует двух наборов входных данных:
Данные, содержащие сигнал, повреждаются шумом. В блок-схеме при Шумовой или Интерференционной Отмене – Используя Адаптивный Фильтр, чтобы Удалить Шум из Неизвестной Системы, это - желаемый сигнал . Процесс подавления помех удаляет шум из сигнала.
Данные, содержащие случайный шум. В блок-схеме при Шумовой или Интерференционной Отмене – Используя Адаптивный Фильтр, чтобы Удалить Шум из Неизвестной Системы, это . Сигнал коррелируется с шумом, который повреждает данные сигнала. Без корреляции между шумовыми данными адаптирующийся алгоритм не может удалить шум из сигнала.
Для сигнала используйте синусоиду. Обратите внимание на то, что signal вектор-столбец 1 000 элементов.
signal = sin(2*pi*0.055*(0:1000-1)');
Теперь добавьте коррелируемый белый шум в signal. Чтобы гарантировать, что шум коррелируется, передайте шум через КИХ lowpass, фильтруют и затем добавляют отфильтрованный шум в сигнал.
noise = randn(1000,1); filt = dsp.FIRFilter; filt.Numerator = fir1(11,0.4); fnoise = filt(noise); d = signal + fnoise;
fnoise коррелированый шум и d теперь желаемый вход к алгоритму ошибки знака.
Подготовить dsp.LMSFilter объект для обработки, установленный начальные условия весов фильтра (InitialConditions) и mu Неродной размер). Как отмечено ранее в этом разделе, значения вы устанавливаете для coeffs и mu определите, может ли адаптивный фильтр удалить шум из пути прохождения сигнала.
В System Identification КИХ-Фильтра Используя LMS-алгоритм вы создали фильтр по умолчанию, который устанавливает коэффициенты фильтра на нули. В большинстве случаев тот подход не работает на алгоритм ошибки знака. Чем ближе вы устанавливаете свои начальные коэффициенты фильтра на ожидаемые значения, тем более вероятно случается так, что алгоритм остается хорошего поведения и сходится к решению для фильтра, которое удаляет шум эффективно.
В данном примере начните с коэффициентов, используемых в шумовом фильтре (filt.Numerator) и измените их немного, таким образом, алгоритм должен адаптироваться.
coeffs = (filt.Numerator).'-0.01; % Set the filter initial conditions. mu = 0.05; % Set the step size for algorithm updating.
С необходимыми входными параметрами для dsp.LMSFilter подготовленный, запустите адаптацию и просмотрите результаты.
lms = dsp.LMSFilter(12,'Method','Sign-Error LMS',... 'StepSize',mu,'InitialConditions',coeffs); [~,e] = lms(noise,d); L = 200; plot(0:199,signal(1:200),0:199,e(1:200)); title('Noise cancellation performance by the sign-error LMS algorithm'); legend('Actual signal','Error after noise reduction',... 'Location','NorthEast') xlabel('Time index') ylabel('Signal value')

Когда LMS-алгоритм ошибки знака запускается, он использует гораздо меньше операций умножения, чем любой из стандартных LMS-алгоритмов. Кроме того, выполнение адаптации ошибки знака требует только множителей сдвига бита, когда размер шага является степенью двойки.
Несмотря на то, что эффективность алгоритма ошибки знака как показано в этом графике довольно хороша, алгоритм ошибки знака намного менее устойчив, чем стандартные изменения LMS. В этом примере подавления помех адаптированный сигнал является очень хорошим соответствием к входному сигналу, но алгоритм мог очень легко стать нестабильным, а не достигнуть хорошей эффективности.
Изменение начальных условий веса (InitialConditions) и mu Неродной размер), или даже lowpass фильтрует вас, раньше создавал коррелированый шум, может заставить подавление помех перестать работать и алгоритм, чтобы стать бесполезным.
LMS-алгоритм знака знака (SSLMS) заменяет вычисление среднеквадратичной погрешности при помощи знака входных данных изменить коэффициенты фильтра. Когда ошибка положительна, новые коэффициенты являются предыдущими коэффициентами плюс ошибка, умноженная на размер шага . Если ошибка отрицательна, новые коэффициенты являются предыдущими коэффициентами минус ошибка, умноженная на — обратите внимание на изменения знака. Когда вход является нулем, новые коэффициенты совпадают с предыдущим набором.
В сущности алгоритм квантует и ошибку и вход путем применения оператора знака к ним.
В векторной форме LMS-алгоритм знака знака:
где
Вектор содержит веса, применился к коэффициентам фильтра и вектору содержит входные данные. Вектор ошибка между желаемым сигналом и отфильтрованным сигналом. Цель алгоритма SSLMS состоит в том, чтобы минимизировать эту ошибку.
С меньшим , коррекция к весам фильтра становится меньшей для каждой выборки, и ошибка SSLMS падает более медленно. Большее изменяет веса больше для каждого шага, таким образом, ошибка падает более быстро, но получившаяся ошибка не приближается к идеальному решению как тесно. Чтобы гарантировать хороший уровень сходимости и устойчивость, выбрать в следующих практических границах.
где количество отсчетов в сигнале. Кроме того, задайте как степень двойки для эффективного расчета
Примечание:
Как вы устанавливаете начальные условия алгоритма знака знака, глубоко влияет на эффективность процесса адаптации. Поскольку алгоритм по существу квантует входной сигнал и сигнал ошибки, алгоритм может стать нестабильным легко.
Серия больших ошибочных значений, вместе с процессом квантования может привести к ошибке при росте вне всех границ. Ограничьте тенденцию алгоритма знака знака стать нестабильными путем выбора размера небольшого шага и устанавливание начальных условий для алгоритма к ненулевым положительным и отрицательным величинам.
В этом примере подавления помех, набор Method свойство dsp.LMSFilter к 'Sign-Sign LMS'. Этот пример требует двух наборов входных данных:
Данные, содержащие сигнал, повреждаются шумом. В блок-схеме при Шумовой или Интерференционной Отмене – Используя Адаптивный Фильтр, чтобы Удалить Шум из Неизвестной Системы, это - желаемый сигнал . Процесс подавления помех удаляет шум из сигнала.
Данные, содержащие случайный шум. В блок-схеме при Шумовой или Интерференционной Отмене – Используя Адаптивный Фильтр, чтобы Удалить Шум из Неизвестной Системы, это . Сигнал коррелируется с шумом, который повреждает данные сигнала. Без корреляции между шумовыми данными адаптирующийся алгоритм не может удалить шум из сигнала.
Для сигнала используйте синусоиду. Обратите внимание на то, что signal вектор-столбец 1 000 элементов.
signal = sin(2*pi*0.055*(0:1000-1)');
Теперь добавьте коррелируемый белый шум в signal. Чтобы гарантировать, что шум коррелируется, передайте шум через КИХ-фильтр lowpass, затем добавьте отфильтрованный шум в сигнал.
noise = randn(1000,1); filt = dsp.FIRFilter; filt.Numerator = fir1(11,0.4); fnoise = filt(noise); d = signal + fnoise;
fnoise коррелированый шум и d теперь желаемый вход к алгоритму знака знака.
Подготовить dsp.LMSFilter объект для обработки, установленный начальные условия весов фильтра (InitialConditions) и mu Неродной размер). Как отмечено ранее в этом разделе, значения вы устанавливаете для coeffs и mu определите, может ли адаптивный фильтр удалить шум из пути прохождения сигнала. В System Identification КИХ-Фильтра Используя LMS-алгоритм вы создали фильтр по умолчанию, который устанавливает коэффициенты фильтра на нули. Обычно тот подход не работает на алгоритм знака знака.
Чем ближе вы устанавливаете свои начальные коэффициенты фильтра на ожидаемые значения, тем более вероятно случается так, что алгоритм остается хорошего поведения и сходится к решению для фильтра, которое удаляет шум эффективно. В данном примере вы начинаете с коэффициентов, используемых в шумовом фильтре (filt.Numerator), и измените их немного, таким образом, алгоритм должен адаптироваться.
coeffs = (filt.Numerator).' -0.01; % Set the filter initial conditions.
mu = 0.05;С необходимыми входными параметрами для dsp.LMSFilter подготовленный, запустите адаптацию и просмотрите результаты.
lms = dsp.LMSFilter(12,'Method','Sign-Sign LMS',... 'StepSize',mu,'InitialConditions',coeffs); [~,e] = lms(noise,d); L = 200; plot(0:199,signal(1:200),0:199,e(1:200)); title('Noise cancellation performance by the sign-sign LMS algorithm'); legend('Actual signal','Error after noise reduction',... 'Location','NorthEast') xlabel('Time index') ylabel('Signal value')

Когда dsp.LMSFilter запуски, это использует гораздо меньше операций умножения, чем любой из стандартных LMS-алгоритмов. Кроме того, выполнение адаптации знака знака требует только множителей сдвига бита, когда размер шага является степенью двойки.
Несмотря на то, что эффективность алгоритма знака знака как показано в этом графике довольно хороша, алгоритм знака знака намного менее устойчив, чем стандартные изменения LMS. В этом примере подавления помех адаптированный сигнал является очень хорошим соответствием к входному сигналу, но алгоритм мог очень легко стать нестабильным, а не достигнуть хорошей эффективности.
Изменение начальных условий веса (InitialConditions) и mu (StepSize), или даже lowpass фильтрует вас, раньше создавал коррелированый шум, может заставить подавление помех перестать работать и алгоритм, чтобы стать бесполезным.
Примечание: Этот пример запускается только в R2017a или позже. Если вы используете релиз ранее, чем R2017a, объект не выводит полную историю выборки выборкой весов фильтра. Если вы используете релиз ранее, чем R2016b, заменяете каждый вызов функции с эквивалентным step синтаксис. Например, myObject(x) становится step(myObject,x).
Инициализируйте dsp.LMSFilter Системный объект и набор WeightsOutput свойство к 'All'. Эта установка позволяет фильтру LMS вывести матрицу весов с размерностями [FrameLength Length], соответствие полной истории выборки выборкой весов для всего FrameLength выборки входных значений.
FrameSize = 15000; lmsfilt3 = dsp.LMSFilter('Length',63,'Method','LMS', ... 'StepSize',0.001,'LeakageFactor',0.99999, ... 'WeightsOutput','All'); % full Weights history w_actual = fir1(64,[0.5 0.75]); firfilt3 = dsp.FIRFilter('Numerator',w_actual); sinewave = dsp.SineWave('Frequency',0.01, ... 'SampleRate',1,'SamplesPerFrame',FrameSize); scope = timescope('TimeUnits','Seconds', ... 'YLimits',[-0.25 0.75],'BufferLength',2*FrameSize, ... 'ShowLegend',true,'ChannelNames', ... {'Coeff 33 Estimate','Coeff 34 Estimate','Coeff 35 Estimate', ... 'Coeff 33 Actual','Coeff 34 Actual','Coeff 35 Actual'});
Запустите одну систему координат и выведите полную адаптивную историю весов, w.
x = randn(FrameSize,1); % Input signal d = firfilt3(x) + sinewave(); % Noise + Signal [~,~,w] = lmsfilt3(x,d);
Каждая строка в w набор весов, оцененных для соответствующей входной выборки. Каждый столбец в w дает полную историю определенного веса. Постройте фактический вес и целую историю 33-го, 34-го, и 35-го веса. В графике вы видите, что предполагаемый вес, выход в конечном счете сходится с фактическим весом как адаптивный фильтр, получает входные выборки и продолжает адаптироваться.
idxBeg = 33; idxEnd = 35; scope([w(:,idxBeg:idxEnd), repmat(w_actual(idxBeg:idxEnd),FrameSize,1)])

Алгоритм фильтра LMS задан следующими уравнениями.
Различные адаптивные алгоритмы фильтра LMS, доступные в этом Системном объекте, заданы как:
LMS – Решает уравнение Вайнера-Гопфа и находит коэффициенты фильтра для адаптивного фильтра.
Нормированный LMS – Нормированное изменение LMS-алгоритма.
В Нормированном LMS, чтобы преодолеть потенциальную числовую нестабильность в обновлении весов, маленькая положительная константа, ε, была добавлена в знаменателе. Для входа с плавающей точкой с двойной точностью ε является 2.2204460492503131e-016. Для входа с плавающей точкой с одинарной точностью ε является 1.192092896e-07. Для входа фиксированной точки ε 0.
Sign-Data LMS – Коррекция к весам фильтра в каждой итерации зависит от знака входа u (n).
где u (n) действителен.
Sign-Error LMS – Коррекция применилась к текущим весам фильтра за каждую последовательную итерацию, зависит от знака ошибки, e (n).
Sign-Sign LMS – Коррекция применилась к текущим весам фильтра за каждую последовательную итерацию, зависит и от знака u (n) и от знака e (n).
где u (n) действителен.
Переменные следующие:
| Переменная | Описание |
|---|---|
|
n |
Индекс текущего времени |
|
u (n) |
Вектор из буферизированных входных выборок на шаге n |
|
u* (n) |
Сопряженное комплексное число вектора из буферизированных входных выборок на шаге n |
|
w (n) |
Вектор из веса фильтра оценивает на шаге n |
|
y(n) |
Отфильтрованный выход на шаге n |
|
e(n) |
Ошибка расчета на шаге n |
|
d(n) |
Желаемый ответ на шаге n |
|
µ |
Размер шага адаптации |
α | Фактор утечки (0 <α ≤ 1) |
ε | Константа, которая корректирует любую потенциальную числовую нестабильность, которая происходит во время обновления весов. |
[1] Hayes, M.H. Статистическая цифровая обработка сигналов и моделирование. Нью-Йорк: John Wiley & Sons, 1996.
Указания и ограничения по применению:
Смотрите системные объекты в Генерации кода MATLAB (MATLAB Coder).
dsp.LMSFilter Системный объект поддерживает использование генерации кода SIMD технология Intel AVX2 при этих условиях:
Method установлен в 'LMS' или 'Normalized LMS'.
WeightsOutput установлен в 'None' или 'Last'.
Входной сигнал с действительным знаком.
Входной сигнал имеет тип данных single или double.
Технология SIMD значительно улучшает производительность сгенерированного кода.
Следующие схемы показывают типы данных, используемые в dsp.LMSFilter объект для сигналов фиксированной точки. Таблица суммирует определения переменных, используемых в схемах:
| Переменная | Определение |
|---|---|
u | Входной вектор |
W | Вектор из весов фильтра |
µ | Неродной размер |
e | Ошибка |
Q | Частное, |
Продукт u'u | Тип данных продукта в энергетической схеме вычисления |
Аккумулятор u'u | Тип данных аккумулятора в энергетической схеме вычисления |
Продукт W'u | Тип данных продукта в схеме Свертки |
Аккумулятор W'u | Тип данных аккумулятора в схеме Свертки |
Продукт | Тип данных продукта в продукте схемы размера и ошибки шага |
Продукт | Продукт и тип данных аккумулятора в Весе обновляют схему. 1 |
1Тип данных аккумулятора для этого количества автоматически собирается совпасть с типом данных продукта. Минимум, максимум и информация о переполнении для этого аккумулятора регистрируются как часть информации о продукте. Автомасштабирование обрабатывает этот продукт и аккумулятор как один тип данных.
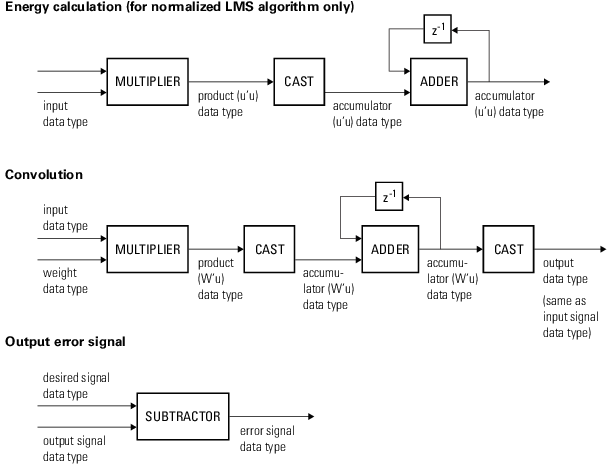
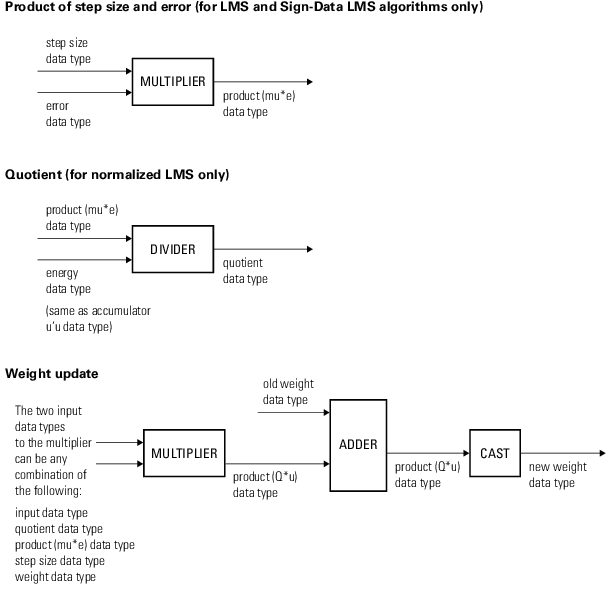
Можно установить тип данных свойств, весов, продуктов, частного и аккумуляторов в свойствах Системного объекта. Входные параметры фиксированной точки, выходные параметры и свойства Системного объекта должны иметь следующие характеристики:
Входной сигнал и желаемый сигнал должны иметь тот же размер слова, но их дробные длины могут отличаться.
Размер шага и фактор утечки должны иметь тот же размер слова, но их дробные длины могут отличаться.
Выходной сигнал и сигнал ошибки имеют тот же размер слова и ту же дробную длину как желаемый сигнал.
Частное и продукт выход u'u, W'u, , и операции должны иметь тот же размер слова, но их дробные длины могут отличаться.
Тип данных аккумулятора u'u и операций W'u должен иметь тот же размер слова, но их дробные длины могут отличаться.
Выход множителя находится в типе выходных данных продукта, если по крайней мере одни из входных параметров ко множителю действительны. Если оба из входных параметров ко множителю являются комплексными, результат умножения находится в типе данных аккумулятора. Для получения дополнительной информации на комплексном выполняемом умножении, смотрите Типы данных Умножения.
dsp.BlockLMSFilter | dsp.FIRFilter | dsp.FilteredXLMSFilter | dsp.FrequencyDomainAdaptiveFilter | dsp.AdaptiveLatticeFilter | dsp.AffineProjectionFilter | dsp.FastTransversalFilter | dsp.RLSFilter