Наиболее частые значения в массиве
M = mode(A)A, который является наиболее часто происходящим значением в A. Когда существует несколько значений, происходящих одинаково часто, mode возвращает самое маленькое из тех значений. Для комплексных входных параметров наименьшее значение является первым значением в отсортированном списке.
Если A вектор, затем mode(A) возвращает наиболее частое значение A.
Если A непустая матрица, затем mode(A) возвращает вектор-строку, содержащий режим каждого столбца A.
Если A пустая матрица 0 на 0, mode(A) возвращает NaN.
Если A многомерный массив, затем mode(A) обрабатывает значения вдоль первого измерения массива, размер которого не равняется 1 как векторы и возвращает массив наиболее частых значений. Размер этой размерности становится 1 в то время как размеры всех других размерностей остаются то же самое.
A — Входной массивВходной массив, заданный как векторный, матричный или многомерный массив. A может быть числовой массив, категориальный массив, массив datetime или массив длительности.
NaN или NaT (Не Время) значения во входном массиве, A, проигнорированы. Неопределенные значения в категориальных массивах похожи на NaNs в числовых массивах.
dim — Размерность, которая задает направление расчетаВеличина для работы, заданная как положительный целый скаляр. Если значение не задано, то по умолчанию это первый размер массива, не равный 1.
Размерность dim указывает на размерность, длина которой уменьшает до 1. size(M,dim) 1, в то время как размеры всех других размерностей остаются то же самое.
Рассмотрите двумерный входной массив, A.
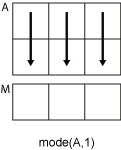
Если dim = 1, затем mode(A,1) возвращает вектор-строку, содержащий наиболее частое значение в каждом столбце.
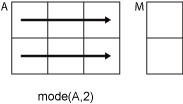
Если dim = 2, затем mode(A,2) возвращает вектор-столбец, содержащий наиболее частое значение в каждой строке.
mode возвращает A если dim больше ndims(A).
Типы данных: double | single | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
vecdim — Вектор из размерностейВектор из размерностей в виде вектора из положительных целых чисел. Каждый элемент представляет размерность входного массива. Продолжительности выхода в заданных операционных размерностях равняются 1, в то время как другие остаются то же самое.
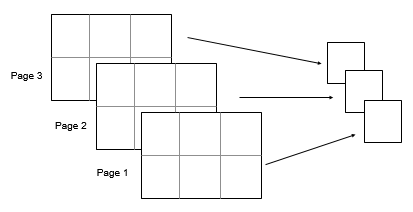
Рассмотрите 2 3х3 входным массивом, A. Затем mode(A,[1 2]) возвращает 1 1 3 массивами, элементами которых являются режимы каждой страницы A.
Типы данных: double | single | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
mode функция является самой полезной с дискретными или грубо округленными данными. Режим для непрерывного вероятностного распределения задан как пик его функции плотности. Применение mode функция к выборке от того распределения вряд ли обеспечит хорошую оценку пика; было бы лучше вычислить гистограмму, или плотность оценивают и вычисляют пик той оценки. Кроме того, mode функция не подходит для нахождения peaks в распределениях, имеющих несколько режимов.
mean | median | histogram | histcounts | sort
