Оцените порог кластеризации окружения
epsilon = clusterDBSCAN.estimateEpsilon(X,MinNumPoints,MaxNumPoints)epsilon, используемый в основанной на плотности пространственной кластеризации приложений с шумом (DBSCAN) алгоритм. epsilon вычисляется из входных данных X использование k - ближайших соседей (k-NN) поиск. MinNumPoints и MaxNumPoints установите область значений k-значений, для которых вычисляется эпсилон. Область значений расширяет от MinNumPoints – 1 через MaxNumPoints – 1. k является количеством соседей точки, которая является той меньше, чем число точек в окружении.
clusterDBSCAN.estimateEpsilon( отображает фигуру, показывающую кривые поиска k-NN и предполагаемый эпсилон.X,MinNumPoints,MaxNumPoints)
Создайте симулированные целевые данные и используйте clusterDBSCAN.estimateEpsilon функция, чтобы вычислить соответствующий порог эпсилона.
Создайте целевые данные как xy Декартовы координаты.
X = [randn(20,2) + [11.5,11.5]; randn(20,2) + [25,15]; ...
randn(20,2) + [8,20]; 10*rand(10,2) + [20,20]];Установите область значений значений для поиска k-NN.
minNumPoints = 15; maxNumPoints = 20;
Оцените кластеризирующийся пороговый эпсилон и отобразите его значение на графике.
clusterDBSCAN.estimateEpsilon(X,minNumPoints,maxNumPoints)

Используйте предполагаемое значение Эпсилона, 3.62, в clusterDBSCAN clusterer. Затем постройте кластеры.
clusterer = clusterDBSCAN('MinNumPoints',6,'Epsilon',3.62, ... 'EnableDisambiguation',false); [idx,cidx] = clusterer(X); plot(clusterer,X,idx)

Кластеризация DBSCAN требует значения для параметра размера окружения ε. clusterDBSCAN возразите и clusterDBSCAN.estimateEpsilon функционируйте используют k - само-соседний поиск, чтобы оценить скалярный эпсилон. Позвольте D быть расстоянием любой точки P к ее kth nearestNeighbor. Задайте Dk (P) - окружение как окружение, окружающее P, который содержит его k - ближайших соседей. Существует k + 1 точка в Dk (P) - окружение включая саму точку P. Схема алгоритма оценки:
Для каждой точки найдите все точки в ее Dk (P) - окружение
Накопите расстояния во всем Dk (P) - окружения для всех точек в один вектор.
Сортировка вектора путем увеличения расстояния.
Постройте отсортированный k-dist график, который является отсортированным расстоянием против номера точки.
Найдите колено кривой. Значение расстояния в той точке является оценкой эпсилона.
Рисунок здесь показывает расстояние, построенное против индекса точки для k = 20. Колено происходит приблизительно в 1,5. Любые точки ниже этого порога принадлежат кластеру. Любые точки выше этого значения являются шумом.
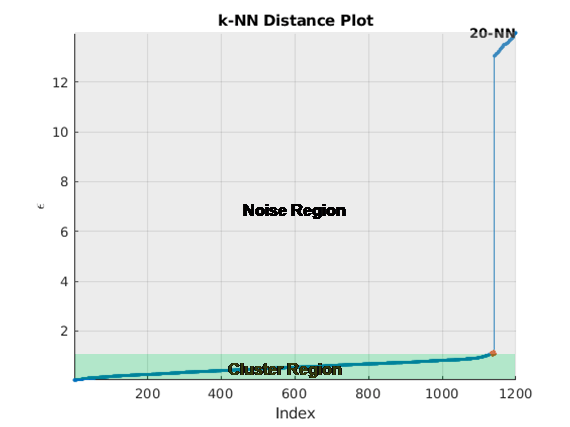
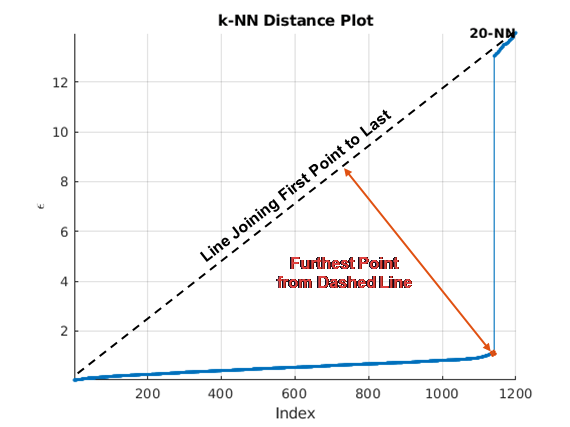
Существует несколько методов, чтобы найти колено кривой. clusterDBSCAN и clusterDBSCAN.estimateEpsilon сначала задайте линию, соединяющую первые и последние точки кривой. Ордината точки на отсортированном k-dist график дальше всего от линии и перпендикуляра к линии задает эпсилон.
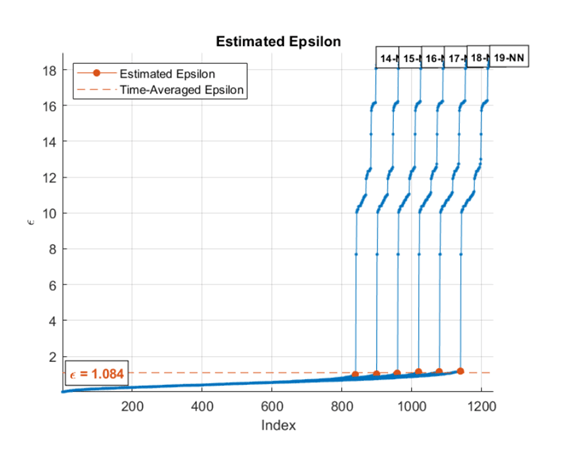
Когда вы указываете диапазон значений k, алгоритм составляет в среднем оценочные значения эпсилона для всех кривых. Этот рисунок показывает, что эпсилон довольно нечувствителен к k для k в пределах от 14 - 19.
Чтобы создать один k график расстояния-NN, установите MinNumPoints свойство, равное MaxNumPoints свойство.
clusterDBSCAN.discoverClusters | clusterDBSCAN.plot | clusterDBSCAN
