Пакет Reinforcement Learning Toolbox™ обеспечивает несколько предопределенных сред системы управления, для которых уже заданы действия, наблюдения, вознаграждения и динамика. Можно использовать эти окружения для:
Изучения концепций обучения с подкреплением.
Ознакомления с особенностями пакета Reinforcement Learning Toolbox.
Тестирования своих агентов обучения с подкреплением.
Можно загрузить следующий предопределенный MATLAB® среды системы управления с помощью rlPredefinedEnv функция.
| Среда | Задача агента |
|---|---|
| Тележка с шестом | Сбалансируйте полюс на движущейся тележке, прикладывая силы к тележке с помощью или дискретного или непрерывного пространства действий. |
| Двойной интегратор | Управляйте динамической системой второго порядка с помощью или дискретного или непрерывного пространства действий. |
| Математический маятник с наблюдением изображений | Swing и баланс математический маятник с помощью или дискретного или непрерывного пространства действий. |
Можно также загрузить, предопределил среды мира сетки MATLAB. Для получения дополнительной информации смотрите Загрузку Предопределенные Среды Мира Сетки.
Цель агента в предопределенных окружениях тележки с шестом - сбалансировать шест на движущейся тележке, прикладывая горизонтальные силы к тележке. Считается, что шест успешно сбалансирован, если оба из следующих условий удовлетворены:
Угол шеста остается внутри заданного порога вертикального положения, где вертикальное положение соответствует углу ноль радиан.
Амплитуда отклонения тележки остается ниже заданного порога.
Существует два варианта окружения тележки с шестом, которые различаются пространством действий агента.
Дискретное - Агент может прикладывать силу или Fmax или-Fmax к тележке, где Fmax является MaxForce свойство среды.
Непрерывное — Агент может прикладывать любую силу в области значений [-Fmax, Fmax].
Для создания окружение тележки используйте rlPredefinedEnv функция.
Дискретное пространство действий
env = rlPredefinedEnv('CartPole-Discrete');Непрерывное пространство действий
env = rlPredefinedEnv('CartPole-Continuous');Можно визуализировать среду тележки с шестом с помощью plot функция. График отображает тележку как синий квадрат и полюс как красный прямоугольник.
plot(env)
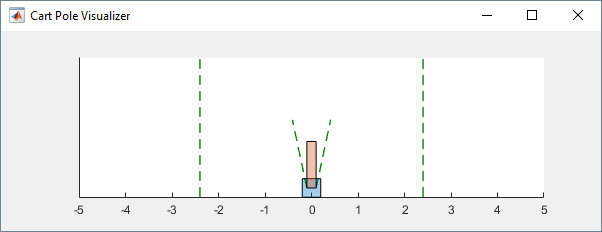
Чтобы визуализировать среду во время обучения, вызвать plot перед обучением и следят за открытой фигурой визуализации.
Для примеров, показывающих, как обучить агентов в средах тележки с шестом, смотрите следующее:
| Свойство | Описание | Значение по умолчанию |
|---|---|---|
Gravity | Ускорение из-за силы тяжести в метрах в секунду придало квадратную форму | 9.8 |
MassCart | Масса тележки в килограммах | 1 |
MassPole | Масса полюса в килограммах | 0.1 |
Length | Половина длины полюса в метрах | 0.5 |
MaxForce | Максимальная горизонталь обеспечивает величину в ньютонах | 10 |
Ts | Шаг расчета в секундах | 0.02 |
ThetaThresholdRadians | Угловой порог полюса в радианах | 0.2094 |
XThreshold | Порог положения тележки в метрах | 2.4 |
RewardForNotFalling | Вознаградите за каждый временной шаг, полюс сбалансирован | 1 |
PenaltyForFalling | Вознаградите штраф за то, чтобы не удаваться сбалансировать полюс | Дискретное - Непрерывное — |
State | Состояние среды в виде вектор-столбца со следующими переменными состояния:
| [0 0 0 0]' |
В средах тележки с шестом агент взаимодействует со средой с помощью одного сигнала действия, горизонтальная сила применилась к тележке. Окружение содержит объект спецификации для этого сигнала действия. Для окружения с:
Дискретное пространство действий, спецификация rlFiniteSetSpec объект.
Непрерывное пространство действий, спецификация rlNumericSpec объект.
Для получения дополнительной информации о получении спецификаций действий от окружения смотрите getActionInfo.
В системе тележки с шестом агент может наблюдать все переменные состояния среды в env.State. Для каждой переменной состояния среда содержит rlNumericSpec спецификация наблюдений. Все состояния непрерывны и неограниченны.
Для получения дополнительной информации о получении спецификаций наблюдений средой смотрите getObservationInfo.
Сигнал вознаграждения для этой среды состоит из двух компонентов.
Положительное вознаграждение за каждый временной шаг, что полюс сбалансирован, то есть, тележка и полюс оба, остается в их указанных пороговых диапазонах. Это вознаграждение накапливается по целому эпизоду тренировки. Чтобы управлять размером этого вознаграждения, используйте RewardForNotFalling свойство среды.
Однократный отрицательный штраф, если или полюс или тележка перемещаются за пределами их пороговой области значений. На данном этапе остановки эпизода тренировки. Чтобы управлять размером этого штрафа, используйте PenaltyForFalling свойство среды.
Цель агента в предопределенных двойных средах интегратора состоит в том, чтобы управлять положением массы в системе второго порядка путем применения входа силы. А именно, система второго порядка является двойным интегратором с усилением.
Эпизоды тренировки для этих сред заканчиваются, когда любое из следующих событий имеет место:
Масса перемещается вне заданного порога от источника.
Норма вектора состояния меньше заданного порога.
Существует два двойных варианта среды интегратора, которые отличаются пространством действий агента.
Дискретное - Агент может прикладывать силу или Fmax или-Fmax к тележке, где Fmax является MaxForce свойство среды.
Непрерывное — Агент может прикладывать любую силу в области значений [-Fmax, Fmax].
Чтобы создать двойную среду интегратора, используйте rlPredefinedEnv функция.
Дискретное пространство действий
env = rlPredefinedEnv('DoubleIntegrator-Discrete');Непрерывное пространство действий
env = rlPredefinedEnv('DoubleIntegrator-Continuous');Можно визуализировать двойную среду интегратора с помощью plot функция. График отображает массу как красный прямоугольник.
plot(env)
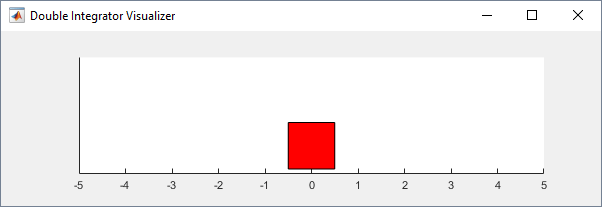
Чтобы визуализировать среду во время обучения, вызвать plot перед обучением и следят за открытой фигурой визуализации.
Для примеров, показывающих, как обучить агентов в двойных средах интегратора, смотрите следующее:
| Свойство | Описание | Значение по умолчанию |
|---|---|---|
Gain | Получите для двойного интегратора | 1 |
Ts | Шаг расчета в секундах | 0.1 |
MaxDistance | Порог величины расстояния в метрах | 5 |
GoalThreshold | Порог нормы состояния | 0.01 |
Q | Матрица веса для компонента наблюдения сигнала вознаграждения | [10 0; 0 1] |
R | Матрица веса для компонента действия сигнала вознаграждения | 0.01 |
MaxForce | Максимальная входная сила в ньютонах | Дискретный: Непрерывный: |
State | Состояние среды в виде вектор-столбца со следующими переменными состояния:
| [0 0]' |
В двойных средах интегратора агент взаимодействует со средой с помощью одного сигнала действия, сила применилась к массе. Окружение содержит объект спецификации для этого сигнала действия. Для окружения с:
Дискретное пространство действий, спецификация rlFiniteSetSpec объект.
Непрерывное пространство действий, спецификация rlNumericSpec объект.
Для получения дополнительной информации о получении спецификаций действий от окружения смотрите getActionInfo.
В двойной системе интегратора агент может наблюдать обе из переменных состояния среды в env.State. Для каждой переменной состояния среда содержит rlNumericSpec спецификация наблюдений. Оба состояния непрерывны и неограниченны.
Для получения дополнительной информации о получении спецификаций наблюдений средой смотрите getObservationInfo.
Сигналом вознаграждения для этой среды является дискретное время, эквивалентное из следующего вознаграждения непрерывного времени, которое походит на функцию стоимости контроллера LQR.
Здесь:
Q и R свойства среды.
x является вектором состояния среды.
u является входной силой.
Это вознаграждение является вознаграждением эпизода, другими словами, совокупным вознаграждением за целый эпизод обучения.
Эта среда является простым лишенным трения маятником, который является, первоначально висит в нисходящем положении. Цель обучения должна заставить маятник стоять вертикально, не падая и используя минимальные усилия по управлению.
Существует два варианта окружения математического маятника, которые отличаются пространством действий агента.
Дискретное - Агент может применить крутящий момент -2, -1, 0, 1, или 2 к маятнику.
Непрерывное — Агент может применить любой крутящий момент в области значений [-2,2].
Чтобы создать окружение математического маятника, используйте rlPredefinedEnv функция.
Дискретное пространство действий
env = rlPredefinedEnv('SimplePendulumWithImage-Discrete');Непрерывное пространство действий
env = rlPredefinedEnv('SimplePendulumWithImage-Continuous');Для примеров, показывающих, как обучить агента в этой среде, смотрите следующее:
| Свойство | Описание | Значение по умолчанию |
|---|---|---|
Mass | Масса маятника | 1 |
RodLength | Длина маятника | 1 |
RodInertia | Момент маятника инерции | 0 |
Gravity | Ускорение из-за силы тяжести в метрах в секунду придало квадратную форму | 9.81 |
DampingRatio | Затухание на движении маятника | 0 |
MaximumTorque | Максимальный входной крутящий момент в ньютонах | 2 |
Ts | Шаг расчета в секундах | 0.05 |
State | Состояние среды в виде вектор-столбца со следующими переменными состояния:
| [0 0 ]' |
Q | Матрица веса для компонента наблюдения сигнала вознаграждения | [1 0;0 0.1] |
R | Матрица веса для компонента действия сигнала вознаграждения | 1e-3 |
В окружениях математического маятника агент взаимодействует с окружением с помощью единственного сигнала действия, крутящего момента, приложенного к основанию маятника. Окружение содержит объект спецификации для этого сигнала действия. Для окружения с:
Дискретное пространство действий, спецификация rlFiniteSetSpec объект.
Непрерывное пространство действий, спецификация rlNumericSpec объект.
Для получения дополнительной информации о получении спецификаций действий от окружения смотрите getActionInfo.
В окружении математического маятника агент получает следующие сигналы наблюдения:
50 50 полутоновое изображение положения маятника
Производная угла маятника
Для каждого сигнала наблюдения среда содержит rlNumericSpec спецификация наблюдений. Все наблюдения непрерывны и неограниченны.
Для получения дополнительной информации о получении спецификаций наблюдений средой смотрите getObservationInfo.
Сигнал вознаграждения для этой среды
Здесь:
θt является углом смещения маятника от вертикального положения.
производная угла маятника.
ut-1 является усилием по управлению от предыдущего временного шага.
