Движущиеся объекты и блоки вычисляют движущуюся статистику потоковой передачи сигналов с помощью один или оба из метода раздвижного окна и экспоненциального метода взвешивания. Метод раздвижного окна имеет конечную импульсную характеристику, в то время как экспоненциальный метод взвешивания имеет бесконечную импульсную характеристику. Чтобы анализировать статистическую величину по конечной длительности данных, используйте метод раздвижного окна. Экспоненциальный метод взвешивания требует меньшего количества коэффициентов и более подходит для встраиваемых приложений.
| Объект, блок | Метод раздвижного окна | Экспоненциальный метод взвешивания |
|---|---|---|
dsp.MedianFilter, Median Filter | ✓ | |
dsp.MovingAverage, Moving Average | ✓ | ✓ |
dsp.MovingMaximum, Moving Maximum | ✓ | |
dsp.MovingMinimum, Moving Minimum | ✓ | |
dsp.MovingRMS, Moving RMS | ✓ | ✓ |
dsp.MovingStandardDeviation, Moving Standard Deviation | ✓ | ✓ |
dsp.MovingVariance, Moving Variance | ✓ | ✓ |
В методе раздвижного окна окно заданной длины, Len, отодвигается данные, выборка выборкой, и статистическая величина вычисляется по данным в окне. Выход для каждой входной выборки является статистической величиной по окну текущей выборки и Len - 1 предыдущая выборка. На новом шаге чтобы вычислить первый Len - 1 выходные параметры, когда окно еще не имеет достаточного количества данных, алгоритм, заполняют окно нулями. В последующих временных шагах, чтобы заполнить окно, алгоритм использует выборки от предыдущей системы координат данных. Движущиеся статистические алгоритмы имеют состояние и помнят предыдущие данные.
Рассмотрите пример вычисления скользящего среднего значения потоковой передачи входные данные с помощью метода раздвижного окна. Алгоритм использует длину окна 4. С каждой входной выборкой, которая входит, окно длины 4 проходит данные.
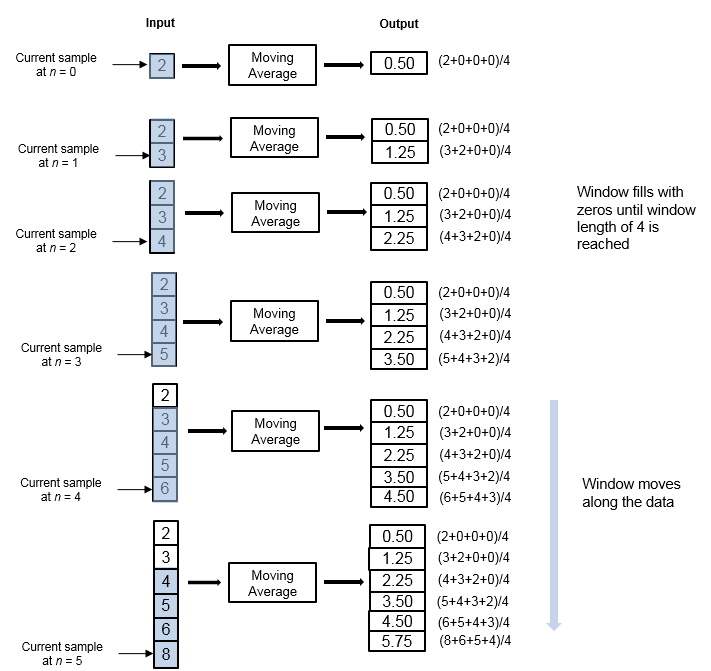
Окно имеет конечную длину, делая алгоритм конечным фильтром импульсной характеристики. Чтобы анализировать статистическую величину по конечной длительности данных, используйте метод раздвижного окна.
Воздействие длины окна
Длина окна задает длину данных, по которым алгоритм вычисляет статистическую величину. Перемещения окна как новые данные входят. Если окно является большим, вычисленная статистическая величина ближе к стационарной статистической величине данных. Для данных, которые не изменяются быстро, используйте длинное окно, чтобы получить более сглаженную статистическую величину. Для данных, которые изменяются быстро, используйте меньшее окно.
Экспоненциальный метод взвешивания имеет бесконечную импульсную характеристику. Алгоритм вычисляет набор весов и применяет эти веса к выборкам данных рекурсивно. Как возраст увеличений данных, величина фактора взвешивания уменьшается экспоненциально и никогда не достигает нуля. Другими словами, недавние данные имеют больше влияния на статистическую величину на текущей выборке, чем более старые данные. Из-за бесконечной импульсной характеристики, алгоритм требует меньшего количества коэффициентов, делая его более подходящим для встраиваемых приложений.
Значение фактора упущения определяет скорость изменения факторов взвешивания. Фактор упущения 0,9 дает больше веса более старым данным, чем делает фактор упущения 0,1. Чтобы дать больше веса недавним данным, подвиньте фактор упущения поближе к 0. Для обнаружения маленьких сдвигов в быстро различных данных меньшее значение (ниже 0.5) более подходит. Фактор упущения 1,0 указывает на бесконечную память. Всем предыдущим выборкам дают равный вес. Оптимальное значение для фактора упущения зависит от потока данных. Для потока определенных данных, чтобы вычислить оптимальное значение для упущения фактора, см. [1].
Рассмотрите пример вычисления скользящего среднего значения с помощью экспоненциального метода взвешивания. Фактор упущения 0.9.
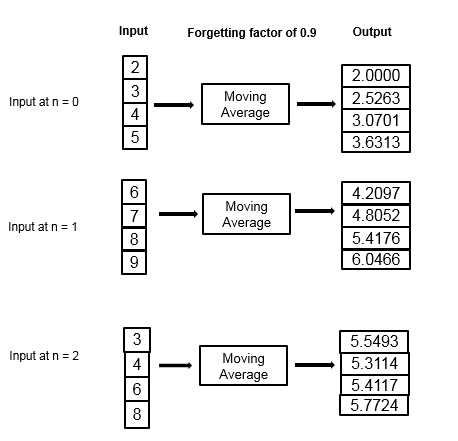
Алгоритм скользящего среднего значения обновляет вес и вычисляет скользящее среднее значение рекурсивно для каждой выборки данных, которая входит при помощи следующих рекурсивных уравнений.
λ — Упущение фактора.
— Взвешивание фактора применилось к текущей выборке данных.
— Текущая выборка ввода данных.
— Скользящее среднее значение на предыдущей выборке.
— Эффект предыдущих данных в среднем.
— Скользящее среднее значение на текущей выборке.
| Данные | Вес | Среднее значение |
|---|---|---|
| Структурируйте 1 | ||
| 2 | 1. Для N = 1, это значение равняется 1. | 2 |
| 3 | 0.9×1+1 = 1.9 | (1– (1/1.9)) ×2 + (1/1.9) ×3 = 2.5263 |
| 4 | 0.9×1.9+1 = 2.71 | (1– (1/2.71)) ×2.52 + (1/2.71) ×4 = 3.0701 |
| 5 | 0.9×2.71+1 = 3.439 | (1– (1/3.439)) ×3.07 + (1/3.439) ×5 = 3.6313 |
| Структурируйте 2 | ||
| 6 | 0.9×3.439+1 = 4.095 | (1– (1/4.095)) ×3.6313 + (1/4.095) ×6 = 4.2097 |
| 7 | 0.9×4.095+1 = 4.6855 | (1– (1/4.6855)) ×4.2097 + (1/4.6855) ×7 = 4.8052 |
| 8 | 0.9×4.6855+1 = 5.217 | (1– (1/5.217)) ×4.8052 + (1/5.217) ×8 = 5.4176 |
| 9 | 0.9×5.217+1 = 5.6953 | (1– (1/5.6953)) ×5.4176 + (1/5.6953) ×9 = 6.0466 |
| Структурируйте 3 | ||
| 3 | 0.9×5.6953+1 = 6.1258 | (1– (1/6.1258)) ×6.0466 + (1/6.1258) ×3 = 5.5493 |
| 4 | 0.9×6.1258+1 = 6.5132 | (1– (1/6.5132)) ×5.5493 + (1/6.5132) ×4 = 5.3114 |
| 6 | 0.9×6.5132+1 = 6.8619 | (1– (1/6.8619)) ×5.3114 + (1/6.8619) ×6 = 5.4117 |
| 8 | 0.9×6.8619+1 = 7.1751 | (1– (1/7.1751)) ×5.4117 + (1/7.1751) ×8 = 5.7724 |
Алгоритм скользящего среднего значения имеет состояние и помнит данные из предыдущего временного шага.
Для первой выборки, когда N = 1, алгоритм выбирает = 1. Для следующей выборки обновляется фактор взвешивания, и среднее значение вычисляется с помощью рекурсивных уравнений.
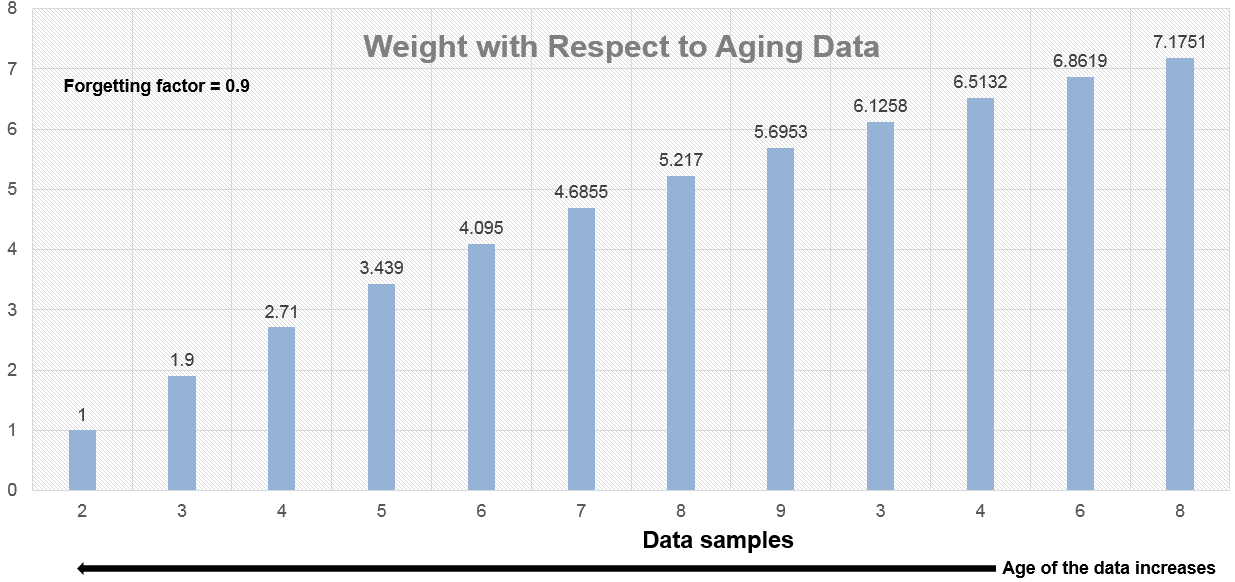
Как возраст увеличений данных, величина фактора взвешивания уменьшается экспоненциально и никогда не достигает нуля. Другими словами, недавние данные имеют больше влияния на текущее среднее значение, чем более старые данные.
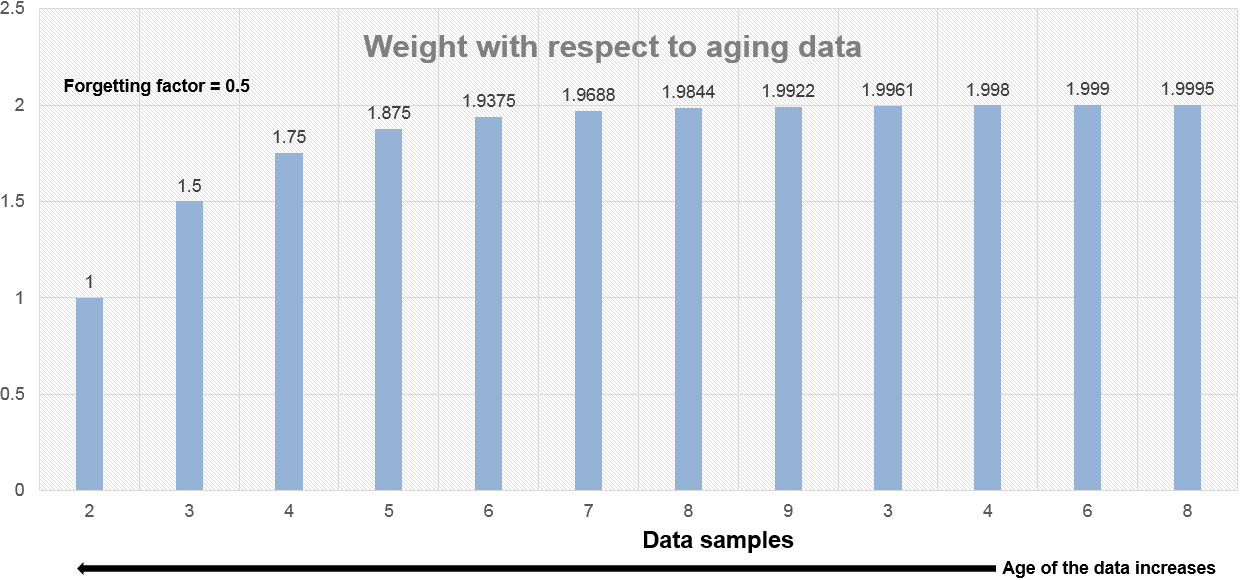
Когда фактор упущения 0.5, веса применились к более старым данным, ниже чем тогда, когда фактор упущения 0.9.
Когда фактор упущения равняется 1, все выборки данных взвешены одинаково. В этом случае экспоненциально взвешенный метод совпадает с методом раздвижного окна с бесконечной длиной окна.
Когда сигнал изменится быстро, используйте более низкий фактор упущения. Когда фактор упущения является низким, эффект прошлых данных меньше на текущем среднем значении. Это делает переходный процесс более резким. Как пример, рассмотрите быстро различный шумный сигнал шага.
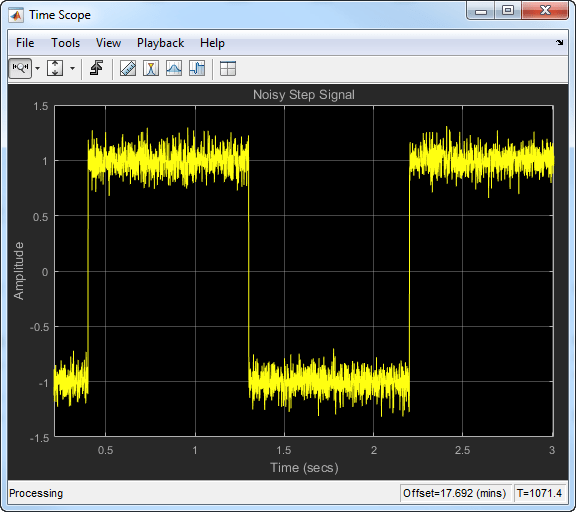
Вычислите скользящее среднее значение этого сигнала с помощью экспоненциально взвешенного метода. Сравните эффективность алгоритма с упущением факторов 0.8, 0.9, и 0.99.
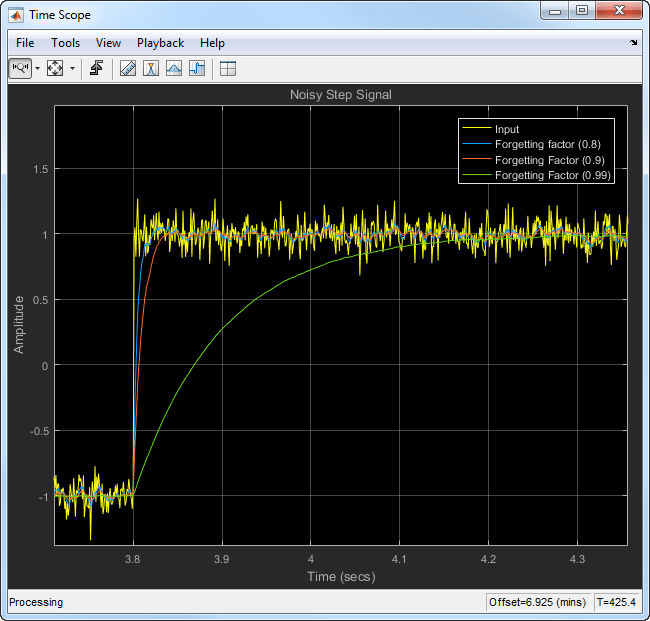
Когда вы увеличиваете масштаб графика, вы видите, что переходный процесс в скользящем среднем значении резок, когда фактор упущения является низким. Это делает его более подходящим для данных, которые изменяются быстро.
Для получения дополнительной информации об алгоритме скользящего среднего значения смотрите раздел Algorithms в dsp.MovingAverage Система object™ или страница блока Moving Average.
Для получения дополнительной информации о других движущихся статистических алгоритмах смотрите раздел Algorithms в соответствующем Системном объекте и страницах блока.
[1] Боденхэм, декан. “Адаптивное обнаружение фильтрации и изменения для потоковой передачи данных”. PH.D. Тезис. Имперский колледж, Лондон, 2012.
