Оцените апостериорное распределение Байесовой векторной авторегрессии (VAR) параметры модели
PosteriorMdl = estimate(PriorMdl,Y)PosteriorMdl это характеризует объединенные апостериорные распределения коэффициентов Λ и инновационная ковариационная матрица Σ. PriorMdl задает объединенное предшествующее распределение параметров и структуру модели VAR. Y многомерные данные об ответе. PriorMdl и PosteriorMdl не может быть тот же тип объекта.
NaNs в данных указывают на отсутствующие значения, который estimate удаляет при помощи мудрого списком удаления.
PosteriorMdl = estimate(PriorMdl,Y,Name,Value)'Y0' аргумент пары "имя-значение".
[ также возвращает сводные данные оценки апостериорного распределения PosteriorMdl,Summary]
= estimate(___)Summary, использование любой из комбинаций входных аргументов в предыдущих синтаксисах.
Рассмотрите 3-D модель VAR (4) для инфляции США (INFL), безработица (UNRATE), и федеральные фонды (FEDFUNDS) уровни.
\forall , серия независимых 3-D нормальных инноваций со средним значением 0 и ковариация . Примите что объединенное предшествующее распределение параметров модели VAR является рассеянным.
Загрузите и предварительно обработайте данные
Загрузите США макроэкономический набор данных. Вычислите уровень инфляции. Постройте весь ряд ответа.
load Data_USEconModel seriesnames = ["INFL" "UNRATE" "FEDFUNDS"]; DataTable.INFL = 100*[NaN; price2ret(DataTable.CPIAUCSL)]; figure plot(DataTable.Time,DataTable{:,seriesnames}) legend(seriesnames)

Стабилизируйте показатели безработицы и ставки по федеральным фондам путем применения первого различия для каждого ряда.
DataTable.DUNRATE = [NaN; diff(DataTable.UNRATE)];
DataTable.DFEDFUNDS = [NaN; diff(DataTable.FEDFUNDS)];
seriesnames(2:3) = "D" + seriesnames(2:3);Удалите все отсутствующие значения из данных.
rmDataTable = rmmissing(DataTable);
Создайте предшествующую модель
Создайте рассеянный Байесов VAR (4) предшествующая модель для трех рядов ответа. Задайте имена переменной отклика.
numseries = numel(seriesnames);
numlags = 4;
PriorMdl = bayesvarm(numseries,numlags,'SeriesNames',seriesnames)PriorMdl =
diffusebvarm with properties:
Description: "3-Dimensional VAR(4) Model"
NumSeries: 3
P: 4
SeriesNames: ["INFL" "DUNRATE" "DFEDFUNDS"]
IncludeConstant: 1
IncludeTrend: 0
NumPredictors: 0
AR: {[3x3 double] [3x3 double] [3x3 double] [3x3 double]}
Constant: [3x1 double]
Trend: [3x0 double]
Beta: [3x0 double]
Covariance: [3x3 double]
PriorMdl diffusebvarm объект модели.
Оцените апостериорное распределение
Оцените апостериорное распределение путем передачи предшествующего и целого ряда данных модели estimate.
PosteriorMdl = estimate(PriorMdl,rmDataTable{:,seriesnames})Bayesian VAR under diffuse priors
Effective Sample Size: 197
Number of equations: 3
Number of estimated Parameters: 39
| Mean Std
-------------------------------
Constant(1) | 0.1007 0.0832
Constant(2) | -0.0499 0.0450
Constant(3) | -0.4221 0.1781
AR{1}(1,1) | 0.1241 0.0762
AR{1}(2,1) | -0.0219 0.0413
AR{1}(3,1) | -0.1586 0.1632
AR{1}(1,2) | -0.4809 0.1536
AR{1}(2,2) | 0.4716 0.0831
AR{1}(3,2) | -1.4368 0.3287
AR{1}(1,3) | 0.1005 0.0390
AR{1}(2,3) | 0.0391 0.0211
AR{1}(3,3) | -0.2905 0.0835
AR{2}(1,1) | 0.3236 0.0868
AR{2}(2,1) | 0.0913 0.0469
AR{2}(3,1) | 0.3403 0.1857
AR{2}(1,2) | -0.0503 0.1647
AR{2}(2,2) | 0.2414 0.0891
AR{2}(3,2) | -0.2968 0.3526
AR{2}(1,3) | 0.0450 0.0413
AR{2}(2,3) | 0.0536 0.0223
AR{2}(3,3) | -0.3117 0.0883
AR{3}(1,1) | 0.4272 0.0860
AR{3}(2,1) | -0.0389 0.0465
AR{3}(3,1) | 0.2848 0.1841
AR{3}(1,2) | 0.2738 0.1620
AR{3}(2,2) | 0.0552 0.0876
AR{3}(3,2) | -0.7401 0.3466
AR{3}(1,3) | 0.0523 0.0428
AR{3}(2,3) | 0.0008 0.0232
AR{3}(3,3) | 0.0028 0.0917
AR{4}(1,1) | 0.0167 0.0901
AR{4}(2,1) | 0.0285 0.0488
AR{4}(3,1) | -0.0690 0.1928
AR{4}(1,2) | -0.1830 0.1520
AR{4}(2,2) | -0.1795 0.0822
AR{4}(3,2) | 0.1494 0.3253
AR{4}(1,3) | 0.0067 0.0395
AR{4}(2,3) | 0.0088 0.0214
AR{4}(3,3) | -0.1372 0.0845
Innovations Covariance Matrix
| INFL DUNRATE DFEDFUNDS
-------------------------------------------
INFL | 0.3028 -0.0217 0.1579
| (0.0321) (0.0124) (0.0499)
DUNRATE | -0.0217 0.0887 -0.1435
| (0.0124) (0.0094) (0.0283)
DFEDFUNDS | 0.1579 -0.1435 1.3872
| (0.0499) (0.0283) (0.1470)
PosteriorMdl =
conjugatebvarm with properties:
Description: "3-Dimensional VAR(4) Model"
NumSeries: 3
P: 4
SeriesNames: ["INFL" "DUNRATE" "DFEDFUNDS"]
IncludeConstant: 1
IncludeTrend: 0
NumPredictors: 0
Mu: [39x1 double]
V: [13x13 double]
Omega: [3x3 double]
DoF: 184
AR: {[3x3 double] [3x3 double] [3x3 double] [3x3 double]}
Constant: [3x1 double]
Trend: [3x0 double]
Beta: [3x0 double]
Covariance: [3x3 double]
PosteriorMdl conjugatebvarm объект модели; следующее аналитически послушно. Командная строка отображает следующие средние значения (Mean) и стандартные отклонения (Std) из всех коэффициентов и инновационной ковариационной матрицы. Строка AR{k}(i,j) содержит следующие оценки , задержка k Коэффициент AR переменной отклика j в ответ уравнение i. По умолчанию, estimate использует первые четыре наблюдения в качестве предварительной выборки, чтобы инициализировать модель.
Отобразите следующие средние значения содействующих матриц AR при помощи записи через точку.
AR1 = PosteriorMdl.AR{1}AR1 = 3×3
0.1241 -0.4809 0.1005
-0.0219 0.4716 0.0391
-0.1586 -1.4368 -0.2905
AR2 = PosteriorMdl.AR{2}AR2 = 3×3
0.3236 -0.0503 0.0450
0.0913 0.2414 0.0536
0.3403 -0.2968 -0.3117
AR3 = PosteriorMdl.AR{3}AR3 = 3×3
0.4272 0.2738 0.0523
-0.0389 0.0552 0.0008
0.2848 -0.7401 0.0028
AR4 = PosteriorMdl.AR{4}AR4 = 3×3
0.0167 -0.1830 0.0067
0.0285 -0.1795 0.0088
-0.0690 0.1494 -0.1372
Рассмотрите 3-D модель VAR (4) Оценочного Апостериорного распределения. В этом случае подбирайте модель к данным, запускающимся в 1 970.
Загрузите и предварительно обработайте данные
Загрузите США макроэкономический набор данных. Вычислите уровень инфляции, стабилизируйте показатели безработицы и ставки по федеральным фондам, и удалите отсутствующие значения.
load Data_USEconModel seriesnames = ["INFL" "UNRATE" "FEDFUNDS"]; DataTable.INFL = 100*[NaN; price2ret(DataTable.CPIAUCSL)]; DataTable.DUNRATE = [NaN; diff(DataTable.UNRATE)]; DataTable.DFEDFUNDS = [NaN; diff(DataTable.FEDFUNDS)]; seriesnames(2:3) = "D" + seriesnames(2:3); rmDataTable = rmmissing(DataTable);
Создайте предшествующую модель
Создайте рассеянный Байесов VAR (4) предшествующая модель для трех рядов ответа. Задайте имена переменной отклика.
numseries = numel(seriesnames);
numlags = 4;
PriorMdl = diffusebvarm(numseries,numlags,'SeriesNames',seriesnames);Основа времени раздела для подвыборок
Модель VAR (4) требует, чтобы p = 4 преддемонстрационных наблюдения инициализировал компонент AR для оценки. Задайте наборы индекса, соответствующие необходимым выборкам предварительной выборки и оценки.
idxpre = rmDataTable.Time < datetime('1970','InputFormat','yyyy'); % Presample indices idxest = ~idxpre; % Estimation sample indices T = sum(idxest)
T = 157
Эффективным объемом выборки является 157 наблюдения.
Оцените апостериорное распределение
Оцените апостериорное распределение. Задайте только необходимые преддемонстрационные наблюдения при помощи 'Y0' аргумент пары "имя-значение".
Y0 = rmDataTable{find(idxpre,PriorMdl.P,'last'),seriesnames};
PosteriorMdl = estimate(PriorMdl,rmDataTable{idxest,seriesnames},...
'Y0',Y0);Bayesian VAR under diffuse priors
Effective Sample Size: 157
Number of equations: 3
Number of estimated Parameters: 39
| Mean Std
-------------------------------
Constant(1) | 0.1431 0.1134
Constant(2) | -0.0132 0.0588
Constant(3) | -0.6864 0.2418
AR{1}(1,1) | 0.1314 0.0869
AR{1}(2,1) | -0.0187 0.0450
AR{1}(3,1) | -0.2009 0.1854
AR{1}(1,2) | -0.5009 0.1834
AR{1}(2,2) | 0.4881 0.0950
AR{1}(3,2) | -1.6913 0.3912
AR{1}(1,3) | 0.1089 0.0446
AR{1}(2,3) | 0.0555 0.0231
AR{1}(3,3) | -0.3588 0.0951
AR{2}(1,1) | 0.2942 0.1012
AR{2}(2,1) | 0.0786 0.0524
AR{2}(3,1) | 0.3767 0.2157
AR{2}(1,2) | 0.0208 0.2042
AR{2}(2,2) | 0.3238 0.1058
AR{2}(3,2) | -0.4530 0.4354
AR{2}(1,3) | 0.0634 0.0487
AR{2}(2,3) | 0.0747 0.0252
AR{2}(3,3) | -0.3594 0.1038
AR{3}(1,1) | 0.4503 0.1002
AR{3}(2,1) | -0.0388 0.0519
AR{3}(3,1) | 0.3580 0.2136
AR{3}(1,2) | 0.3119 0.2008
AR{3}(2,2) | 0.0966 0.1040
AR{3}(3,2) | -0.8212 0.4282
AR{3}(1,3) | 0.0659 0.0502
AR{3}(2,3) | 0.0155 0.0260
AR{3}(3,3) | -0.0269 0.1070
AR{4}(1,1) | -0.0141 0.1046
AR{4}(2,1) | 0.0105 0.0542
AR{4}(3,1) | 0.0263 0.2231
AR{4}(1,2) | -0.2274 0.1875
AR{4}(2,2) | -0.1734 0.0972
AR{4}(3,2) | 0.1328 0.3999
AR{4}(1,3) | 0.0028 0.0456
AR{4}(2,3) | 0.0094 0.0236
AR{4}(3,3) | -0.1487 0.0973
Innovations Covariance Matrix
| INFL DUNRATE DFEDFUNDS
-------------------------------------------
INFL | 0.3597 -0.0333 0.1987
| (0.0433) (0.0161) (0.0672)
DUNRATE | -0.0333 0.0966 -0.1647
| (0.0161) (0.0116) (0.0365)
DFEDFUNDS | 0.1987 -0.1647 1.6355
| (0.0672) (0.0365) (0.1969)
Рассмотрите 3-D модель VAR (4) Оценочного Апостериорного распределения.
Загрузите США макроэкономический набор данных. Вычислите уровень инфляции, стабилизируйте показатели безработицы и ставки по федеральным фондам, и удалите отсутствующие значения.
load Data_USEconModel seriesnames = ["INFL" "UNRATE" "FEDFUNDS"]; DataTable.INFL = 100*[NaN; price2ret(DataTable.CPIAUCSL)]; DataTable.DUNRATE = [NaN; diff(DataTable.UNRATE)]; DataTable.DFEDFUNDS = [NaN; diff(DataTable.FEDFUNDS)]; seriesnames(2:3) = "D" + seriesnames(2:3); rmDataTable = rmmissing(DataTable);
Создайте рассеянный Байесов VAR (4) предшествующая модель для трех рядов ответа. Задайте имена переменной отклика.
numseries = numel(seriesnames);
numlags = 4;
PriorMdl = diffusebvarm(numseries,numlags,'SeriesNames',seriesnames);Можно отобразить оценку выход тремя способами или выключить отображение. Сравните типы дисплея.
estimate(PriorMdl,rmDataTable{:,seriesnames}); % 'table', the defaultBayesian VAR under diffuse priors
Effective Sample Size: 197
Number of equations: 3
Number of estimated Parameters: 39
| Mean Std
-------------------------------
Constant(1) | 0.1007 0.0832
Constant(2) | -0.0499 0.0450
Constant(3) | -0.4221 0.1781
AR{1}(1,1) | 0.1241 0.0762
AR{1}(2,1) | -0.0219 0.0413
AR{1}(3,1) | -0.1586 0.1632
AR{1}(1,2) | -0.4809 0.1536
AR{1}(2,2) | 0.4716 0.0831
AR{1}(3,2) | -1.4368 0.3287
AR{1}(1,3) | 0.1005 0.0390
AR{1}(2,3) | 0.0391 0.0211
AR{1}(3,3) | -0.2905 0.0835
AR{2}(1,1) | 0.3236 0.0868
AR{2}(2,1) | 0.0913 0.0469
AR{2}(3,1) | 0.3403 0.1857
AR{2}(1,2) | -0.0503 0.1647
AR{2}(2,2) | 0.2414 0.0891
AR{2}(3,2) | -0.2968 0.3526
AR{2}(1,3) | 0.0450 0.0413
AR{2}(2,3) | 0.0536 0.0223
AR{2}(3,3) | -0.3117 0.0883
AR{3}(1,1) | 0.4272 0.0860
AR{3}(2,1) | -0.0389 0.0465
AR{3}(3,1) | 0.2848 0.1841
AR{3}(1,2) | 0.2738 0.1620
AR{3}(2,2) | 0.0552 0.0876
AR{3}(3,2) | -0.7401 0.3466
AR{3}(1,3) | 0.0523 0.0428
AR{3}(2,3) | 0.0008 0.0232
AR{3}(3,3) | 0.0028 0.0917
AR{4}(1,1) | 0.0167 0.0901
AR{4}(2,1) | 0.0285 0.0488
AR{4}(3,1) | -0.0690 0.1928
AR{4}(1,2) | -0.1830 0.1520
AR{4}(2,2) | -0.1795 0.0822
AR{4}(3,2) | 0.1494 0.3253
AR{4}(1,3) | 0.0067 0.0395
AR{4}(2,3) | 0.0088 0.0214
AR{4}(3,3) | -0.1372 0.0845
Innovations Covariance Matrix
| INFL DUNRATE DFEDFUNDS
-------------------------------------------
INFL | 0.3028 -0.0217 0.1579
| (0.0321) (0.0124) (0.0499)
DUNRATE | -0.0217 0.0887 -0.1435
| (0.0124) (0.0094) (0.0283)
DFEDFUNDS | 0.1579 -0.1435 1.3872
| (0.0499) (0.0283) (0.1470)
estimate(PriorMdl,rmDataTable{:,seriesnames},...
'Display','equation');Bayesian VAR under diffuse priors
Effective Sample Size: 197
Number of equations: 3
Number of estimated Parameters: 39
VAR Equations
| INFL(-1) DUNRATE(-1) DFEDFUNDS(-1) INFL(-2) DUNRATE(-2) DFEDFUNDS(-2) INFL(-3) DUNRATE(-3) DFEDFUNDS(-3) INFL(-4) DUNRATE(-4) DFEDFUNDS(-4) Constant
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
INFL | 0.1241 -0.4809 0.1005 0.3236 -0.0503 0.0450 0.4272 0.2738 0.0523 0.0167 -0.1830 0.0067 0.1007
| (0.0762) (0.1536) (0.0390) (0.0868) (0.1647) (0.0413) (0.0860) (0.1620) (0.0428) (0.0901) (0.1520) (0.0395) (0.0832)
DUNRATE | -0.0219 0.4716 0.0391 0.0913 0.2414 0.0536 -0.0389 0.0552 0.0008 0.0285 -0.1795 0.0088 -0.0499
| (0.0413) (0.0831) (0.0211) (0.0469) (0.0891) (0.0223) (0.0465) (0.0876) (0.0232) (0.0488) (0.0822) (0.0214) (0.0450)
DFEDFUNDS | -0.1586 -1.4368 -0.2905 0.3403 -0.2968 -0.3117 0.2848 -0.7401 0.0028 -0.0690 0.1494 -0.1372 -0.4221
| (0.1632) (0.3287) (0.0835) (0.1857) (0.3526) (0.0883) (0.1841) (0.3466) (0.0917) (0.1928) (0.3253) (0.0845) (0.1781)
Innovations Covariance Matrix
| INFL DUNRATE DFEDFUNDS
-------------------------------------------
INFL | 0.3028 -0.0217 0.1579
| (0.0321) (0.0124) (0.0499)
DUNRATE | -0.0217 0.0887 -0.1435
| (0.0124) (0.0094) (0.0283)
DFEDFUNDS | 0.1579 -0.1435 1.3872
| (0.0499) (0.0283) (0.1470)
estimate(PriorMdl,rmDataTable{:,seriesnames},...
'Display','matrix');Bayesian VAR under diffuse priors
Effective Sample Size: 197
Number of equations: 3
Number of estimated Parameters: 39
VAR Coefficient Matrix of Lag 1
| INFL(-1) DUNRATE(-1) DFEDFUNDS(-1)
--------------------------------------------------
INFL | 0.1241 -0.4809 0.1005
| (0.0762) (0.1536) (0.0390)
DUNRATE | -0.0219 0.4716 0.0391
| (0.0413) (0.0831) (0.0211)
DFEDFUNDS | -0.1586 -1.4368 -0.2905
| (0.1632) (0.3287) (0.0835)
VAR Coefficient Matrix of Lag 2
| INFL(-2) DUNRATE(-2) DFEDFUNDS(-2)
--------------------------------------------------
INFL | 0.3236 -0.0503 0.0450
| (0.0868) (0.1647) (0.0413)
DUNRATE | 0.0913 0.2414 0.0536
| (0.0469) (0.0891) (0.0223)
DFEDFUNDS | 0.3403 -0.2968 -0.3117
| (0.1857) (0.3526) (0.0883)
VAR Coefficient Matrix of Lag 3
| INFL(-3) DUNRATE(-3) DFEDFUNDS(-3)
--------------------------------------------------
INFL | 0.4272 0.2738 0.0523
| (0.0860) (0.1620) (0.0428)
DUNRATE | -0.0389 0.0552 0.0008
| (0.0465) (0.0876) (0.0232)
DFEDFUNDS | 0.2848 -0.7401 0.0028
| (0.1841) (0.3466) (0.0917)
VAR Coefficient Matrix of Lag 4
| INFL(-4) DUNRATE(-4) DFEDFUNDS(-4)
--------------------------------------------------
INFL | 0.0167 -0.1830 0.0067
| (0.0901) (0.1520) (0.0395)
DUNRATE | 0.0285 -0.1795 0.0088
| (0.0488) (0.0822) (0.0214)
DFEDFUNDS | -0.0690 0.1494 -0.1372
| (0.1928) (0.3253) (0.0845)
Constant Term
INFL | 0.1007
| (0.0832)
DUNRATE | -0.0499
| 0.0450
DFEDFUNDS | -0.4221
| 0.1781
Innovations Covariance Matrix
| INFL DUNRATE DFEDFUNDS
-------------------------------------------
INFL | 0.3028 -0.0217 0.1579
| (0.0321) (0.0124) (0.0499)
DUNRATE | -0.0217 0.0887 -0.1435
| (0.0124) (0.0094) (0.0283)
DFEDFUNDS | 0.1579 -0.1435 1.3872
| (0.0499) (0.0283) (0.1470)
Возвратите сводные данные оценки, которые являются структурой, которая содержит ту же информацию независимо от типа дисплея.
[PosteriorMdl,Summary] = estimate(PriorMdl,rmDataTable{:,seriesnames});Bayesian VAR under diffuse priors
Effective Sample Size: 197
Number of equations: 3
Number of estimated Parameters: 39
| Mean Std
-------------------------------
Constant(1) | 0.1007 0.0832
Constant(2) | -0.0499 0.0450
Constant(3) | -0.4221 0.1781
AR{1}(1,1) | 0.1241 0.0762
AR{1}(2,1) | -0.0219 0.0413
AR{1}(3,1) | -0.1586 0.1632
AR{1}(1,2) | -0.4809 0.1536
AR{1}(2,2) | 0.4716 0.0831
AR{1}(3,2) | -1.4368 0.3287
AR{1}(1,3) | 0.1005 0.0390
AR{1}(2,3) | 0.0391 0.0211
AR{1}(3,3) | -0.2905 0.0835
AR{2}(1,1) | 0.3236 0.0868
AR{2}(2,1) | 0.0913 0.0469
AR{2}(3,1) | 0.3403 0.1857
AR{2}(1,2) | -0.0503 0.1647
AR{2}(2,2) | 0.2414 0.0891
AR{2}(3,2) | -0.2968 0.3526
AR{2}(1,3) | 0.0450 0.0413
AR{2}(2,3) | 0.0536 0.0223
AR{2}(3,3) | -0.3117 0.0883
AR{3}(1,1) | 0.4272 0.0860
AR{3}(2,1) | -0.0389 0.0465
AR{3}(3,1) | 0.2848 0.1841
AR{3}(1,2) | 0.2738 0.1620
AR{3}(2,2) | 0.0552 0.0876
AR{3}(3,2) | -0.7401 0.3466
AR{3}(1,3) | 0.0523 0.0428
AR{3}(2,3) | 0.0008 0.0232
AR{3}(3,3) | 0.0028 0.0917
AR{4}(1,1) | 0.0167 0.0901
AR{4}(2,1) | 0.0285 0.0488
AR{4}(3,1) | -0.0690 0.1928
AR{4}(1,2) | -0.1830 0.1520
AR{4}(2,2) | -0.1795 0.0822
AR{4}(3,2) | 0.1494 0.3253
AR{4}(1,3) | 0.0067 0.0395
AR{4}(2,3) | 0.0088 0.0214
AR{4}(3,3) | -0.1372 0.0845
Innovations Covariance Matrix
| INFL DUNRATE DFEDFUNDS
-------------------------------------------
INFL | 0.3028 -0.0217 0.1579
| (0.0321) (0.0124) (0.0499)
DUNRATE | -0.0217 0.0887 -0.1435
| (0.0124) (0.0094) (0.0283)
DFEDFUNDS | 0.1579 -0.1435 1.3872
| (0.0499) (0.0283) (0.1470)
Summary
Summary = struct with fields:
Description: "3-Dimensional VAR(4) Model"
NumEstimatedParameters: 39
Table: [39x2 table]
CoeffMap: [39x1 string]
CoeffMean: [39x1 double]
CoeffStd: [39x1 double]
SigmaMean: [3x3 double]
SigmaStd: [3x3 double]
CoeffMap поле содержит список содействующих имен. Порядок имен соответствует порядку всех вводов и выводов вектора коэффициентов. Отобразите CoeffMap.
Summary.CoeffMap
ans = 39x1 string
"AR{1}(1,1)"
"AR{1}(1,2)"
"AR{1}(1,3)"
"AR{2}(1,1)"
"AR{2}(1,2)"
"AR{2}(1,3)"
"AR{3}(1,1)"
"AR{3}(1,2)"
"AR{3}(1,3)"
"AR{4}(1,1)"
"AR{4}(1,2)"
"AR{4}(1,3)"
"Constant(1)"
"AR{1}(2,1)"
"AR{1}(2,2)"
"AR{1}(2,3)"
"AR{2}(2,1)"
"AR{2}(2,2)"
"AR{2}(2,3)"
"AR{3}(2,1)"
"AR{3}(2,2)"
"AR{3}(2,3)"
"AR{4}(2,1)"
"AR{4}(2,2)"
"AR{4}(2,3)"
"Constant(2)"
"AR{1}(3,1)"
"AR{1}(3,2)"
"AR{1}(3,3)"
"AR{2}(3,1)"
⋮
Рассмотрите 3-D модель VAR (4) Оценочного Апостериорного распределения В этом примере, создайте нормальную сопряженную предшествующую модель с фиксированной матрицей коэффициентов вместо рассеянной модели. Модель содержит 39 коэффициентов. Для содействующей разреженности в следующем примените Миннесотский метод регуляризации во время оценки.
Загрузите США макроэкономический набор данных. Вычислите уровень инфляции, стабилизируйте показатели безработицы и ставки по федеральным фондам, и удалите отсутствующие значения.
load Data_USEconModel seriesnames = ["INFL" "UNRATE" "FEDFUNDS"]; DataTable.INFL = 100*[NaN; price2ret(DataTable.CPIAUCSL)]; DataTable.DUNRATE = [NaN; diff(DataTable.UNRATE)]; DataTable.DFEDFUNDS = [NaN; diff(DataTable.FEDFUNDS)]; seriesnames(2:3) = "D" + seriesnames(2:3); rmDataTable = rmmissing(DataTable);
Создайте нормальный сопряженный Байесов VAR (4) предшествующая модель для трех рядов ответа. Задайте имена переменной отклика и установите инновационную ковариационную матрицу
Согласно Миннесотскому методу регуляризации, задайте следующее:
Каждый ответ является моделью AR (1), в среднем, с задержкой 1 коэффициент 0.75.
Предшествующие коэффициенты самозадержки имеют отклонение 100. Эта большая установка отклонения позволяет данным влиять на следующие больше, чем предшествующее.
Предшествующие коэффициенты перекрестной задержки имеют отклонение 0.01. Эта маленькая установка отклонения сжимает коэффициенты перекрестной задержки, чтобы обнулить во время оценки.
Предшествующее содействующее затухание ковариаций с увеличивающейся задержкой на уровне 10 (то есть, более низкие задержки более важны, чем более высокие задержки).
numseries = numel(seriesnames); numlags = 4; Sigma = [10e-5 0 10e-4; 0 0.1 -0.2; 10e-4 -0.2 1.6]; PriorMdl = bayesvarm(numseries,numlags,'Model','normal','SeriesNames',seriesnames,... 'Center',0.75,'SelfLag',100,'CrossLag',0.01,'Decay',10,... 'Sigma',Sigma);
Оцените апостериорное распределение и отобразите следующие уравнения ответа.
PosteriorMdl = estimate(PriorMdl,rmDataTable{:,seriesnames},'Display','equation');Bayesian VAR under normal priors and fixed Sigma
Effective Sample Size: 197
Number of equations: 3
Number of estimated Parameters: 39
VAR Equations
| INFL(-1) DUNRATE(-1) DFEDFUNDS(-1) INFL(-2) DUNRATE(-2) DFEDFUNDS(-2) INFL(-3) DUNRATE(-3) DFEDFUNDS(-3) INFL(-4) DUNRATE(-4) DFEDFUNDS(-4) Constant
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
INFL | 0.1234 -0.4373 0.1050 0.3343 -0.0342 0.0308 0.4441 0.0031 0.0090 0.0083 -0.0003 0.0003 0.0820
| (0.0014) (0.0027) (0.0007) (0.0015) (0.0021) (0.0006) (0.0015) (0.0004) (0.0003) (0.0015) (0.0001) (0.0001) (0.0014)
DUNRATE | 0.0521 0.3636 0.0125 0.0012 0.1720 0.0009 0.0000 -0.0741 -0.0000 0.0000 0.0007 -0.0000 -0.0413
| (0.0252) (0.0723) (0.0191) (0.0031) (0.0666) (0.0031) (0.0004) (0.0348) (0.0004) (0.0001) (0.0096) (0.0001) (0.0339)
DFEDFUNDS | -0.0105 -0.1394 -0.1368 0.0002 -0.0000 -0.1227 0.0000 -0.0000 0.0085 -0.0000 0.0000 -0.0041 -0.0113
| (0.0749) (0.0948) (0.0713) (0.0031) (0.0031) (0.0633) (0.0004) (0.0004) (0.0344) (0.0001) (0.0001) (0.0097) (0.1176)
Innovations Covariance Matrix
| INFL DUNRATE DFEDFUNDS
----------------------------------------
INFL | 0.0001 0 0.0010
| (0) (0) (0)
DUNRATE | 0 0.1000 -0.2000
| (0) (0) (0)
DFEDFUNDS | 0.0010 -0.2000 1.6000
| (0) (0) (0)
Сравните результаты со следующим, в котором вы не задаете предшествующей регуляризации.
PriorMdlNoReg = bayesvarm(numseries,numlags,'Model','normal','SeriesNames',seriesnames,... 'Sigma',Sigma); PosteriorMdlNoReg = estimate(PriorMdlNoReg,rmDataTable{:,seriesnames},'Display','equation');
Bayesian VAR under normal priors and fixed Sigma
Effective Sample Size: 197
Number of equations: 3
Number of estimated Parameters: 39
VAR Equations
| INFL(-1) DUNRATE(-1) DFEDFUNDS(-1) INFL(-2) DUNRATE(-2) DFEDFUNDS(-2) INFL(-3) DUNRATE(-3) DFEDFUNDS(-3) INFL(-4) DUNRATE(-4) DFEDFUNDS(-4) Constant
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
INFL | 0.1242 -0.4794 0.1007 0.3233 -0.0502 0.0450 0.4270 0.2734 0.0523 0.0168 -0.1823 0.0068 0.1010
| (0.0014) (0.0028) (0.0007) (0.0016) (0.0030) (0.0007) (0.0016) (0.0029) (0.0008) (0.0016) (0.0027) (0.0007) (0.0015)
DUNRATE | -0.0264 0.3428 0.0089 0.0969 0.1578 0.0292 0.0042 -0.0309 -0.0114 0.0221 -0.1071 0.0072 -0.0873
| (0.0347) (0.0714) (0.0203) (0.0356) (0.0714) (0.0203) (0.0337) (0.0670) (0.0200) (0.0326) (0.0615) (0.0186) (0.0422)
DFEDFUNDS | -0.0351 -0.1248 -0.0411 0.0416 -0.0224 -0.1358 0.0014 -0.0302 0.1557 -0.0074 -0.0010 -0.0785 -0.0205
| (0.0787) (0.0949) (0.0696) (0.0631) (0.0689) (0.0663) (0.0533) (0.0567) (0.0630) (0.0470) (0.0493) (0.0608) (0.1347)
Innovations Covariance Matrix
| INFL DUNRATE DFEDFUNDS
----------------------------------------
INFL | 0.0001 0 0.0010
| (0) (0) (0)
DUNRATE | 0 0.1000 -0.2000
| (0) (0) (0)
DFEDFUNDS | 0.0010 -0.2000 1.6000
| (0) (0) (0)
Следующие оценки предшествующей Миннесоты имеют более низкую величину, в целом, по сравнению с оценками нормальной сопряженной предшествующей модели по умолчанию.
Рассмотрите 3-D модель VAR (4) Оценочного Апостериорного распределения В этом случае, примите, что содействующая и инновационная ковариационная матрица независима (полусопряженная предшествующая модель).
Загрузите США макроэкономический набор данных. Вычислите уровень инфляции, стабилизируйте показатели безработицы и ставки по федеральным фондам, и удалите отсутствующие значения.
load Data_USEconModel seriesnames = ["INFL" "UNRATE" "FEDFUNDS"]; DataTable.INFL = 100*[NaN; price2ret(DataTable.CPIAUCSL)]; DataTable.DUNRATE = [NaN; diff(DataTable.UNRATE)]; DataTable.DFEDFUNDS = [NaN; diff(DataTable.FEDFUNDS)]; seriesnames(2:3) = "D" + seriesnames(2:3); rmDataTable = rmmissing(DataTable);
Создайте полусопряженный Байесов VAR (4) предшествующая модель для трех рядов ответа. Задайте имена переменной отклика.
numseries = numel(seriesnames); numlags = 4; PriorMdl = bayesvarm(numseries,numlags,'Model','semiconjugate',... 'SeriesNames',seriesnames);
Поскольку соединение, следующее из полусопряженной предшествующей модели, аналитически тяжело, estimate использует сэмплер Гиббса, чтобы сформировать соединение, следующее путем выборки от послушных полных условных выражений.
Оцените апостериорное распределение. Для сэмплера Гиббса задайте эффективное количество ничьих 20 000, электротермотренировки 5 000 и утончающегося фактора 10.
rng(1) % For reproducibility PosteriorMdl = estimate(PriorMdl,rmDataTable{:,seriesnames},... 'Display','equation','NumDraws',20000,'Burnin',5000,'Thin',10);
Bayesian VAR under semiconjugate priors
Effective Sample Size: 197
Number of equations: 3
Number of estimated Parameters: 39
VAR Equations
| INFL(-1) DUNRATE(-1) DFEDFUNDS(-1) INFL(-2) DUNRATE(-2) DFEDFUNDS(-2) INFL(-3) DUNRATE(-3) DFEDFUNDS(-3) INFL(-4) DUNRATE(-4) DFEDFUNDS(-4) Constant
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
INFL | 0.2243 -0.0824 0.1365 0.2515 -0.0098 0.0329 0.2888 0.0311 0.0368 0.0458 -0.0206 0.0176 0.1836
| (0.0662) (0.0821) (0.0319) (0.0701) (0.0636) (0.0309) (0.0662) (0.0534) (0.0297) (0.0649) (0.0470) (0.0274) (0.0720)
DUNRATE | -0.0262 0.3666 0.0148 0.0929 0.1637 0.0336 0.0016 -0.0147 -0.0089 0.0222 -0.1133 0.0082 -0.0808
| (0.0342) (0.0728) (0.0197) (0.0354) (0.0713) (0.0198) (0.0334) (0.0671) (0.0194) (0.0320) (0.0606) (0.0179) (0.0407)
DFEDFUNDS | -0.0251 -0.1285 -0.0527 0.0379 -0.0256 -0.1452 -0.0040 -0.0360 0.1516 -0.0090 0.0008 -0.0823 -0.0193
| (0.0785) (0.0962) (0.0673) (0.0630) (0.0688) (0.0643) (0.0531) (0.0567) (0.0610) (0.0467) (0.0492) (0.0586) (0.1302)
Innovations Covariance Matrix
| INFL DUNRATE DFEDFUNDS
-------------------------------------------
INFL | 0.2984 -0.0219 0.1754
| (0.0305) (0.0121) (0.0499)
DUNRATE | -0.0219 0.0890 -0.1496
| (0.0121) (0.0092) (0.0292)
DFEDFUNDS | 0.1754 -0.1496 1.4754
| (0.0499) (0.0292) (0.1506)
PosteriorMdl empiricalbvarm модель, представленная ничьими от полных условных выражений. После удаления первой электротермотренировки чертит и утончение остающихся ничьих путем хранения каждой 10-й ничьей, estimate хранит ничьи в CoeffDraws и SigmaDraws свойства.
Считайте 2D модель VARX(1) для США действительным GDP (RGDP) и инвестиции (GCE) уровни, который обрабатывает персональное потребление (PCEC) уровень как внешний:
\forall , серия независимых 2D нормальных инноваций со средним значением 0 и ковариация . Примите следующие предшествующие распределения:
, где M 4 2 матрица средних значений и матрица шкалы среди коэффициента 4 на 4. Эквивалентно, .
, где Ω является матрицей шкалы 2 на 2 и степени свободы.
Загрузите США макроэкономический набор данных. Вычислите действительный GDP, инвестиции и персональный ряд нормы потребления. Удалите все отсутствующие значения из получившегося ряда.
load Data_USEconModel DataTable.RGDP = DataTable.GDP./DataTable.GDPDEF; seriesnames = ["PCEC"; "RGDP"; "GCE"]; rates = varfun(@price2ret,DataTable,'InputVariables',seriesnames); rates = rmmissing(rates); rates.Properties.VariableNames = seriesnames;
Создайте сопряженную предшествующую модель для 2D VARX (1) параметры модели.
numseries = 2; numlags = 1; numpredictors = 1; PriorMdl = conjugatebvarm(numseries,numlags,'NumPredictors',numpredictors,... 'SeriesNames',seriesnames(2:end));
Оцените апостериорное распределение. Задайте внешние данные о предикторе.
PosteriorMdl = estimate(PriorMdl,rates{:,2:end},...
'X',rates{:,1},'Display','equation');Bayesian VAR under conjugate priors
Effective Sample Size: 247
Number of equations: 2
Number of estimated Parameters: 8
VAR Equations
| RGDP(-1) GCE(-1) Constant X1
-----------------------------------------------
RGDP | 0.0083 -0.0027 0.0078 0.0105
| (0.0625) (0.0606) (0.0043) (0.0625)
GCE | 0.0059 0.0477 0.0166 0.0058
| (0.0644) (0.0624) (0.0044) (0.0645)
Innovations Covariance Matrix
| RGDP GCE
---------------------------
RGDP | 0.0040 0.0000
| (0.0004) (0.0003)
GCE | 0.0000 0.0043
| (0.0003) (0.0004)
По умолчанию, estimate использует первый p = 1 наблюдение в заданных данных об ответе как предварительная выборка, и это удаляет соответствующие наблюдения в данных о предикторе из выборки.
Следующие средние значения (и стандартные отклонения) коэффициентов регрессии появляются ниже X1 столбец сводной таблицы оценки.
Симуляция Монте-Карло подвергается изменению. Если estimate симуляция Монте-Карло использования, затем оценивает, и выводы могут варьироваться, когда вы вызываете estimate многократно при на вид эквивалентных условиях. Чтобы воспроизвести результаты оценки, установите seed случайных чисел при помощи rng перед вызовом estimate.
Каждый раз, когда предшествующее распределение PriorMdl и вероятность данных дает к аналитически послушному апостериорному распределению, estimate оценивает решения закрытой формы средств оценки Бейеса. В противном случае, estimate использует сэмплер Гиббса, чтобы оценить следующее.
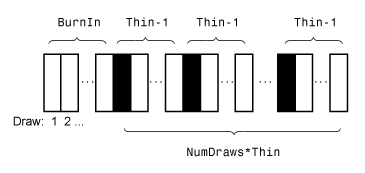
Этот рисунок иллюстрирует как estimate уменьшает выборку Монте-Карло использование значений NumDraws, Thin, и BurnIn. Прямоугольники представляют последовательные ничьи от распределения. estimate удаляет белые прямоугольники из выборки Монте-Карло. Остающийся NumDraws черные прямоугольники составляют выборку Монте-Карло.