Считайте отформатированные данные из текстового файла или строки
C = textscan(fileID,formatSpec)C. Текстовый файл обозначается идентификатором файла, fileID. Используйте fopen открыть файл и получить fileID значение. Когда вы закончите читать из файла, закройте файл путем вызова fclose(fileID).
textscan попытки совпадать с данными в файле к спецификатору преобразования в formatSpec. textscan функция повторно применяет formatSpec в целом файле и остановках, когда это не может совпадать с formatSpec к данным.
C = textscan(fileID,formatSpec,N)formatSpec N времена, где N положительное целое число. Считывать дополнительные данные из файла после N циклы, вызовите textscan снова с помощью исходного fileID. Если вы возобновляете текстовый скан файла путем вызова textscan с тем же идентификатором файла (fileID), затем textscan автоматически резюме, читающие в точке, где это отключило последнее чтение.
C = textscan(chr,formatSpec)chr в массив ячеек C. При чтении текста из вектора символов, повторенных вызовов textscan перезапустите скан с начала каждый раз. Чтобы перезапустить скан от последней позиции, запросите position вывод .
textscan попытки совпадать с данными в векторе символов chr к формату, заданному в formatSpec.
C = textscan(chr,formatSpec,N)formatSpec N времена, где N положительное целое число.
C = textscan(___,Name,Value)Name,Value парные аргументы, в дополнение к любому из входных параметров в предыдущих синтаксисах.
Считайте вектор символов, содержащий числа с плавающей запятой.
chr = '0.41 8.24 3.57 6.24 9.27'; C = textscan(chr,'%f');
Спецификатор '%f' в formatSpec говорит textscan совпадать с каждым полем в chr к числу с плавающей запятой с двойной точностью.
Отобразите содержимое массива ячеек C.
celldisp(C)
C{1} =
0.4100
8.2400
3.5700
6.2400
9.2700
Считайте тот же вектор символов и обрежьте каждое значение до одной десятичной цифры.
C = textscan(chr,'%3.1f %*1d');Спецификатор %3.1f указывает на ширину поля 3 цифр и точность 1. textscan функционируйте читает в общей сложности 3 цифры, включая десятичную точку и 1 цифру после десятичной точки. Спецификатор, %*1d, говорит textscan пропускать остающуюся цифру.
Отобразите содержимое массива ячеек C.
celldisp(C)
C{1} =
0.4000
8.2000
3.5000
6.2000
9.2000
Считайте вектор символов, который представляет набор шестнадцатеричных чисел. Текст, который представляет шестнадцатеричные числа, включает цифры 0-9, буквы aF или AF, и опционально префиксы 0x или 0X.
Совпадать с полями в hexnums к шестнадцатеричным числам используйте '%x' спецификатор. textscan функция преобразует поля в 64-битные целые числа без знака.
hexnums = '0xFF 0x100 0x3C5E A F 10'; C = textscan(hexnums,'%x')
C = 1x1 cell array
{6x1 uint64}
Отобразите содержимое C как вектор-строка.
transpose(C{:})ans = 1x6 uint64 row vector
255 256 15454 10 15 16
Можно преобразовать поля в целые числа со знаком или беззнаковое целое, имея 8, 16, 32, или 64 бита. Преобразовывать поля в hexnums до 32-битных целых чисел со знаком используйте '%xs32' спецификатор.
C = textscan(hexnums,'%xs32');
transpose(C{:})ans = 1x6 int32 row vector
255 256 15454 10 15 16
Можно также задать ширину поля для интерпретации входа. В этом случае префикс рассчитывает к ширине поля. Например, если вы устанавливаете ширину поля до три, как в %3x, затем textscan разделяет текст '0xAF 100' в три части текста, '0xA'F, и '100'. Это обрабатывает три части текста как различные шестнадцатеричные числа.
C = textscan('0xAF 100','%3x'); transpose(C{:})
ans = 1x3 uint64 row vector
10 15 256
Считайте вектор символов, который представляет набор двоичных чисел. Текст, который представляет двоичные числа, включает цифры 0 и 1, и опционально префиксы 0b или 0B.
Совпадать с полями в binnums к двоичным числам используйте '%b' спецификатор. textscan функция преобразует поля в 64-битные целые числа без знака.
binnums = '0b101010 0b11 0b100 1001 10'; C = textscan(binnums,'%b')
C = 1x1 cell array
{5x1 uint64}
Отобразите содержимое C как вектор-строка.
transpose(C{:})ans = 1x5 uint64 row vector
42 3 4 9 2
Можно преобразовать поля в целые числа со знаком или беззнаковое целое, имея 8, 16, 32, или 64 бита. Преобразовывать поля в binnums до 32-битных целых чисел со знаком используйте '%bs32' спецификатор.
C = textscan(binnums,'%bs32');
transpose(C{:})ans = 1x5 int32 row vector
42 3 4 9 2
Можно также задать ширину поля для интерпретации входа. В этом случае префикс рассчитывает к ширине поля. Например, если вы устанавливаете ширину поля до три, как в %3b, затем textscan разделяет текст '0b1010 100' в три части текста, '0b1', '010', и '100'. Это обрабатывает три части текста как различные двоичные числа.
C = textscan('0b1010 100','%3b'); transpose(C{:})
ans = 1x3 uint64 row vector
1 2 4
Загрузите файл данных и считайте каждый столбец с соответствующим типом.
Файл загрузки scan1.dat и предварительный просмотр его содержимое в текстовом редакторе. Снимок экрана показывают ниже.
filename = 'scan1.dat';
Откройте файл и считайте каждый столбец с соответствующим спецификатором преобразования. textscan возвращает 1-by-9 массив ячеек C.
fileID = fopen(filename); C = textscan(fileID,'%s %s %f32 %d8 %u %f %f %s %f'); fclose(fileID); whos C
Name Size Bytes Class Attributes C 1x9 2105 cell
Просмотрите тип данных MATLAB® каждой из ячеек в C.
C
C=1×9 cell array
Columns 1 through 5
{3x1 cell} {3x1 cell} {3x1 single} {3x1 int8} {3x1 uint32}
Columns 6 through 9
{3x1 double} {3x1 double} {3x1 cell} {3x1 double}
Исследуйте отдельные записи. Заметьте, что C{1} и C{2} массивы ячеек. C{5} имеет тип данных uint32, так первые два элемента C{5} максимальные значения для 32- битное беззнаковое целое или intmax('uint32').
celldisp(C)
C{1}{1} =
09/12/2005
C{1}{2} =
10/12/2005
C{1}{3} =
11/12/2005
C{2}{1} =
Level1
C{2}{2} =
Level2
C{2}{3} =
Level3
C{3} =
12.3400
23.5400
34.9000
C{4} =
45
60
12
C{5} =
4294967295
4294967295
200000
C{6} =
Inf
-Inf
10
C{7} =
NaN
0.0010
100.0000
C{8}{1} =
Yes
C{8}{2} =
No
C{8}{3} =
No
C{9} =
5.1000 + 3.0000i
2.2000 - 0.5000i
3.1000 + 0.1000i
Удалите буквенный текст 'Level' от каждого поля во втором столбце данных из предыдущего примера. Предварительный просмотр файла показывают ниже.

Откройте файл и совпадайте с буквенным текстом во входе formatSpec.
filename = 'scan1.dat'; fileID = fopen(filename); C = textscan(fileID,'%s Level%d %f32 %d8 %u %f %f %s %f'); fclose(fileID); C{2}
ans = 3x1 int32 column vector
1
2
3
Просмотрите тип данных MATLAB® второй ячейки в C. Вторая ячейка 1-by-9 массив ячеек, C, имеет теперь тип данных int32.
disp( class(C{2}) )int32
Считайте первый столбец файла в предыдущем примере в массив ячеек, пропустив остальную часть линии.
filename = 'scan1.dat'; fileID = fopen(filename); dates = textscan(fileID,'%s %*[^\n]'); fclose(fileID); dates{1}
ans = 3x1 cell
{'09/12/2005'}
{'10/12/2005'}
{'11/12/2005'}
textscan возвращает массив ячеек даты.
Загрузите файл data.csv и предварительный просмотр его содержимое в текстовом редакторе. Снимок экрана показывают ниже. Заметьте, что файл содержит данные, разделенные запятыми, и также содержит пустые значения.
![]()
Считайте файл, преобразовав пустые ячейки в -Inf.
filename = 'data.csv'; fileID = fopen(filename); C = textscan(fileID,'%f %f %f %f %u8 %f',... 'Delimiter',',','EmptyValue',-Inf); fclose(fileID); column4 = C{4}, column5 = C{5}
column4 = 2×1
4
-Inf
column5 = 2x1 uint8 column vector
0
11
textscan возвращает 1-by-6 массив ячеек, C. textscan функция преобразует пустое значение в C{4} к -Inf, где C{4} сопоставлен с форматом с плавающей точкой. Поскольку MATLAB® представляет беззнаковое целое -Inf как 0textscan преобразует пустое значение в C{5} к 0, и не -Inf.
Загрузите файл data2.csv и предварительный просмотр его содержимое в текстовом редакторе. Снимок экрана показывают ниже. Заметьте, что файл содержит данные, которые могут быть интерпретированы как комментарии и другие записи, такие как 'NA' или 'na' это может указать на пустые поля.
filename = 'data2.csv';![]()
Определяйте вход что textscan должен обработать как комментарии или пустые значения и отсканировать данные в C.
fileID = fopen(filename); C = textscan(fileID,'%s %n %n %n %n','Delimiter',',',... 'TreatAsEmpty',{'NA','na'},'CommentStyle','//'); fclose(fileID);
Отобразите вывод.
celldisp(C)
C{1}{1} =
abc
C{1}{2} =
def
C{2} =
2
NaN
C{3} =
NaN
5
C{4} =
3
6
C{5} =
4
7
Загрузите файл data3.csv и предварительный просмотр его содержимое в текстовом редакторе. Снимок экрана показывают ниже. Заметьте, что файл содержит повторенные разделители.
filename = 'data3.csv';
Чтобы обработать повторные запятые как один разделитель, используйте MultipleDelimsAsOne параметр, и установленный значение к 1 TRUE).
fileID = fopen(filename); C = textscan(fileID,'%f %f %f %f','Delimiter',',',... 'MultipleDelimsAsOne',1); fclose(fileID); celldisp(C)
C{1} =
1
5
C{2} =
2
6
C{3} =
3
7
C{4} =
4
8
Загрузите файл данных grades.txt для этого примера и предварительного просмотра его содержимое в текстовом редакторе. Снимок экрана показывают ниже. Заметьте, что файл содержит повторенные разделители.
filename = 'grades.txt';
Считайте заголовки столбцов с помощью формата '%s' четыре раза.
fileID = fopen(filename); formatSpec = '%s'; N = 4; C_text = textscan(fileID,formatSpec,N,'Delimiter','|');
Считайте числовые данные в файле.
C_data0 = textscan(fileID,'%d %f %f %f')C_data0=1×4 cell array
{4x1 int32} {4x1 double} {4x1 double} {4x1 double}
Значение по умолчанию для CollectOutput 0 ложь), таким образом, textscan возвращает каждый столбец числовых данных в отдельном массиве.
Установите индикатор позиции в файле на начало файла.
frewind(fileID);
Перечитайте файл и установите CollectOutput на 1 (TRUE) собирать последовательные столбцы того же класса в единый массив. Можно использовать repmat функция, чтобы указать, что %f спецификатор преобразования должен появиться три раза. Этот метод полезен, когда формат много раз повторяется.
C_text = textscan(fileID,'%s',N,'Delimiter','|'); C_data1 = textscan(fileID,['%d',repmat('%f',[1,3])],'CollectOutput',1)
C_data1=1×2 cell array
{4x1 int32} {4x3 double}
Экзаменационные отметки, которые являются все двойными, собраны в сингл 4 3 массив.
Закройте файл.
fclose(fileID);
Считайте первые и последние столбцы данных из текстового файла. Пропустите столбец текста и столбец целочисленных данных.
Загрузите файл names.txt и предварительный просмотр его содержимое в текстовом редакторе. Снимок экрана показывают ниже. Заметьте, что файл содержит два столбца заключенного в кавычки текста, сопровождаемого столбцом целых чисел, и наконец столбцом чисел с плавающей точкой.
filename = 'names.txt';
Считайте первые и последние столбцы данных в файле. Используйте спецификатор преобразования, %q считать текст, заключенный двойными кавычками ("Q пропускает заключенный в кавычки текст, %*d пропускает целочисленное поле и %f читает число с плавающей запятой. Задайте разделитель запятой с помощью 'Delimiter' аргумент пары "имя-значение".
fileID = fopen(filename,'r'); C = textscan(fileID,'%q %*q %*d %f','Delimiter',','); fclose(fileID);
Отобразите вывод. textscan возвращает массив ячеек C куда двойные кавычки, заключающие текст, удалены.
celldisp(C)
C{1}{1} =
Smith, J.
C{1}{2} =
Bates, G.
C{1}{3} =
Curie, M.
C{1}{4} =
Murray, G.
C{1}{5} =
Brown, K.
C{2} =
71.1000
69.3000
64.1000
133.0000
64.9000
Загрузите файл german_dates.txt и предварительный просмотр его содержимое в текстовом редакторе. Снимок экрана показывают ниже. Заметьте, что первый столбец значений содержит даты на немецком языке, и вторые и третьи столбцы являются числовыми значениями.
filename = 'german_dates.txt';
Откройте файл. Задайте схему кодировки символов, сопоставленную с файлом как последний вход к fopen.
fileID = fopen(filename,'r','n','ISO-8859-15');
Считайте файл. Задайте формат дат в файле с помощью %{dd % MMMM yyyy}D спецификатор. Задайте локаль дат с помощью DateLocale аргумент пары "имя-значение".
C = textscan(fileID,'%{dd MMMM yyyy}D %f %f',... 'DateLocale','de_DE','Delimiter',','); fclose(fileID);
Просмотрите содержимое первой ячейки в C. Даты отображают на языке использование MATLAB в зависимости от вашей системной локали.
C{1}ans = 3x1 datetime
01 January 2014
01 February 2014
01 March 2014
Используйте sprintf преобразовывать escape-последовательности не по умолчанию в ваших данных.
Создайте текст, который включает символ перевода страницы, \f. Затем чтобы считать текст с помощью textscan, вызовите sprintf явным образом преобразовывать перевод формата.
lyric = sprintf('Blackbird\fsinging\fin\fthe\fdead\fof\fnight'); C = textscan(lyric,'%s','delimiter',sprintf('\f')); C{1}
ans = 7x1 cell
{'Blackbird'}
{'singing' }
{'in' }
{'the' }
{'dead' }
{'of' }
{'night' }
textscan возвращает массив ячеек, C.
Продолжите сканировать от положения кроме начала.
Если вы возобновляете скан текста, textscan чтения с начала каждый раз. Чтобы возобновить скан от любого другого положения, используйте синтаксис 2D выходного аргумента в своем начальном вызове textscan.
Например, создайте вектор символов под названием lyric. Считайте первое слово вектора символов, и затем возобновите скан.
lyric = 'Blackbird singing in the dead of night'; [firstword,pos] = textscan(lyric,'%9c',1); lastpart = textscan(lyric(pos+1:end),'%s');
fileID — Идентификатор файлаИдентификатор файла открытого текстового файла в виде номера. Прежде, чем считать файл с textscan, необходимо использовать fopen открыть файл и получить fileID.
Типы данных: double
formatSpec — Формат полей данныхФормат полей данных в виде вектора символов или строки одного или нескольких спецификаторов преобразования. Когда textscan читает вход, он пытается совпадать с данными к формату, заданному в formatSpec. Если textscan сбои, чтобы совпадать с полем данных, это прекращает читать и возвращает все полевое чтение перед отказом.
Количество спецификаторов преобразования определяет количество ячеек в выходном массиве, C.
Numeric Fields
Эта таблица приводит доступные спецификаторы преобразования для числовых входных параметров.
| Числовой входной тип | Спецификатор преобразования | Выходной класс |
|---|---|---|
| Целое число, со знаком | %d | int32 |
%d8 | int8 | |
%d16 | int16 | |
%d32 | int32 | |
%d64 | int64 | |
| Целое число, без знака | %u | uint32 |
%u8 | uint8 | |
%u16 | uint16 | |
%u32 | uint32 | |
%u64 | uint64 | |
| Число с плавающей запятой | %f | double |
%f32 | single | |
%f64 | double | |
%n | double | |
| Шестнадцатеричный номер, беззнаковое целое | %x | uint64 |
%xu8 | uint8 | |
%xu16 | uint16 | |
%xu32 | uint32 | |
%xu64 | uint64 | |
| Шестнадцатеричный номер, целое число со знаком | %xs8 | int8 |
%xs16 | int16 | |
%xs32 | int32 | |
%xs64 | int64 | |
| Двоичное число, беззнаковое целое | %b | uint64 |
%bu8 | uint8 | |
%bu16 | uint16 | |
%bu32 | uint32 | |
%bu64 | uint64 | |
| Двоичное число, целое число со знаком | %bs8 | int8 |
%bs16 | int16 | |
%bs32 | int32 | |
%bs64 | int64 |
Nonnumeric Fields
Эта таблица приводит доступные спецификаторы преобразования для входных параметров, которые включают нечисловые символы.
| Нечисловой входной тип | Спецификатор преобразования | Детали |
|---|---|---|
| Символ | %c | Считайте любой отдельный символ, включая разделитель. |
| Текстовый массив | %s | Читайте как массив ячеек из символьных векторов. |
%q | Читайте как массив ячеек из символьных векторов. Если текст начинается с двойной кавычки ( Пример: | |
| Даты и время | %D | Считайте тот же путь как |
| Считайте тот же путь как Для получения дополнительной информации о форматах отображения datetime, смотрите Пример: | |
| Длительность | %T |
Считайте тот же путь как |
| Считайте тот же путь как Для получения дополнительной информации о форматах отображения длительности, смотрите Пример: | |
| Категория | %C | Считайте тот же путь как |
| Сопоставление с образцом | %[...] | Читайте как массив ячеек из символьных векторов, символы в скобках до первого символа несоответствия. Включать Пример: |
%[^...] | Исключите символы в скобках, читая до первого символа соответствия. Исключить Пример: |
Optional Operators
Спецификаторы преобразования в formatSpec может включать дополнительные операторы, которые появляются в следующем порядке (включает пробелы для ясности):
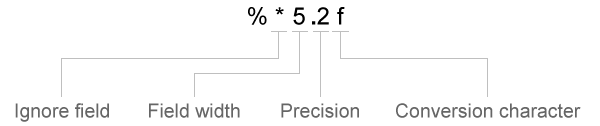
Дополнительные операторы включают:
Поля и символы, чтобы проигнорировать
textscan чтения все символы в вашем файле в последовательности, если вы не говорите ему игнорировать конкретное поле или фрагмент поля.
Вставьте символ звездочки (*) после символа процента (%), чтобы пропустить поле или фрагмент символьного поля.
Оператор | Меры приняты |
|---|---|
| Пропустите поле. Пример: |
| Пропустите до Пример: |
| Пропустите |
Ширина поля
textscan читает количество символов или цифр, заданных шириной поля или точностью, или до первого разделителя, какой бы ни на первом месте. Десятичная точка, знак (+ или -), символ экспоненты и цифры в числовой экспоненте считаются как символы и цифры в ширине поля. Для комплексных чисел ширина поля относится к отдельным ширинам действительной части и мнимой части. Для мнимой части ширина поля включает + или −, но не i или j. Задайте ширину поля путем вставки номера после символа процента (%) в спецификаторе преобразования.
Пример: %5f чтения '123.456' как 123.4.
Пример: %5c чтения 'abcdefg' как 'abcde'.
Когда оператор ширины поля используется с отдельными символами (%ctextscan также разделитель чтений, пробел и символы конца линии.
Пример: %7c чтения 7 символов, включая пробел, so'Day and night' чтения как 'Day and'.
Точность
Для чисел с плавающей запятой (%nF, %f32, %f64), можно задать количество десятичных цифр, чтобы читать.
Пример: %7.2f чтения '123.456' как 123.45.
Буквенный текст, чтобы проигнорировать
textscan игнорирует текст, добавленный к formatSpec спецификатор преобразования.
Пример: Level%u8 чтения 'Level1' как 1.
Пример: %u8Step чтения '2Step' как 2.
Типы данных: char | string
N — Число раз, чтобы применить formatSpecInf (значение по умолчанию) | положительное целое числоЧисло раз, чтобы применить formatSpecВ виде положительного целого числа.
Типы данных: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
chr — Введите текстВведите текст, чтобы читать.
Типы данных: char | string
Задайте дополнительные разделенные запятой пары Name,Value аргументы. Name имя аргумента и Value соответствующее значение. Name должен появиться в кавычках. Вы можете задать несколько аргументов в виде пар имен и значений в любом порядке, например: Name1, Value1, ..., NameN, ValueN.
C = textscan(fileID,formatSpec,'HeaderLines',3,'Delimiter',',') пропускает первые три линии данных, и затем считывает остающиеся данные, обрабатывая запятые как разделитель.Имена не являются чувствительными к регистру.
textscan преобразует числовые поля в заданный выходной тип согласно правилам MATLAB относительно переполнения, усечения и использования NaNInf, и -Inf. Например, MATLAB представляет целочисленный NaN как нуль. Если textscan находит пустое поле сопоставленным со спецификатором целочисленного формата (таким как %d или %u), это возвращает пустое значение как нуль и не NaN.
При соответствии с данными к текстовому спецификатору преобразования, textscan чтения, пока это не находит разделитель или символ конца линии. При соответствии с данными к числовому спецификатору преобразования, textscan чтения, пока это не находит нечисловой символ. Когда textscan больше не может совпадать с данными к конкретному спецификатору преобразования, они пытаются совпадать с данными к следующему спецификатору преобразования в formatSpec. Знак (+ или -), символы экспоненты и десятичные точки рассматриваются цифровыми символами.
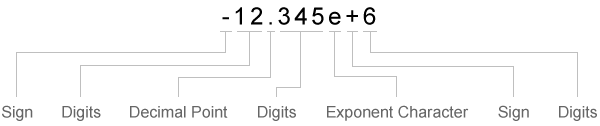
| Знак | Цифры | Десятичная точка | Цифры | 'ExponentCharacter' | Знак | Цифры |
|---|---|---|---|---|---|---|
| Считайте один символ знака, если он существует. | Считайте одну или несколько цифр. | Считайте одну десятичную точку, если она существует. | Если существует десятичная точка, считайте одну или несколько цифр, которые сразу следуют за нею. | Считайте один символ экспоненты, если он существует. | Если существует символ экспоненты, считайте один символ знака. | Если существует символ экспоненты, считайте одну или несколько цифр, которые следуют за ним. |
textscan импорт любое комплексное число в целом в комплексное числовое поле, преобразовывая действительные и мнимые части в заданный числовой тип (такие как %d или %f). Допустимые формы для комплексного числа:
±<real>±<imag>i|j | Пример: |
±<imag>i|j | Пример: |
Не включайте встроенный пробел в комплексное число. textscan интерпретирует встроенный пробел как разделитель полей.
readmatrix | readcell | readvars | fread | fscanf | load | uiimport | fopen | readtable
