Основанный на плотности алгоритм для кластеризации данных
clusterDBSCAN точки данных кластеров, принадлежащие P - размерное пространство признаков с помощью основанной на плотности пространственной кластеризации приложений с шумом (DBSCAN) алгоритм. Кластеризирующийся алгоритм присваивает точки, которые являются друг близко к другу в пространстве признаков к одному кластеру. Например, радиолокационная система может возвратить несколько обнаружений расширенной цели, которые близко расположены в области значений, углу и Доплере. clusterDBSCAN присвоения эти обнаружения к одному обнаружению.
Алгоритм DBSCAN принимает, что кластеры являются плотными областями в пространстве данных, разделенном областями более низкой плотности и что все плотные области имеют подобную плотность.
Чтобы измерить плотность в точке, алгоритм считает количество точек данных в окружении точки. Окружением является P - размерный эллипс (гиперэллипс) в пространстве признаков. Радиусы эллипса заданы P - вектор ε. ε может быть скаляром, в этом случае, гиперэллипс становится гиперсферой. Расстояния между точками в пространстве признаков вычисляются с помощью Евклидовой метрики расстояния. Окружение называется ε-neighborhood. Значение ε задано Epsilon свойство. Epsilon может или быть скаляр или P - вектор:
Вектор используется, когда различные размерности в пространстве признаков имеют различные модули.
Скаляр применяет то же значение ко всем размерностям.
Кластеризация запускается путем нахождения всех базовых точек. Если точка имеет достаточное число точек в его ε-neighborhood, точка называется базовой точкой. Минимальное число точек, требуемое для точки стать базовой точкой, установлено MinNumPoints свойство.
Остающиеся точки в ε-neighborhood базовой точки могут быть самими базовыми точками. В противном случае они - пограничные точки. Все точки в ε-neighborhood называются непосредственно плотностью, достижимой от базовой точки.
Если ε-neighborhood базовой точки содержит другие базовые точки, точки в ε-neighborhoods всего базового слияния точек вместе, чтобы сформировать объединение ε-neighborhoods. Этот процесс продолжается, пока больше базовых точек не может быть добавлено.
Все точки в объединении ε-neighborhoods являются плотностью, достижимой от первой базовой точки. На самом деле все точки в объединении являются плотностью, достижимой от всех базовых точек в объединении.
Все точки в объединении ε-neighborhoods также называют плотностью, соединенной даже при том, что пограничные точки не обязательно достижимы друг от друга. Кластер является максимальным набором соединенных с плотностью точек и может иметь произвольную форму.
Точки, которые не являются базовыми или пограничные точки, являются шумовыми точками. Они не принадлежат никакому кластеру.
clusterDBSCAN объект может оценить ε с помощью k - самый близкий соседний поиск, или можно задать значения. Чтобы позволить объектной оценке ε, установите EpsilonSource свойство к 'Auto'.
clusterDBSCAN объект может снять неоднозначность данных, содержащих неоднозначности. Область значений и Доплер являются примерами возможно неоднозначных данных. Установите EnableDisambiguation свойство к true снять неоднозначность данных.
К кластерным обнаружениям:
Создайте clusterDBSCAN объект и набор его свойства.
Вызовите объект с аргументами, как будто это была функция.
Чтобы узнать больше, как Системные объекты работают, смотрите то, Что Системные объекты?
clusterer = clusterDBSCANclusterDBSCAN объект, clusterer, объект со значениями свойств по умолчанию.
clusterer = clusterDBSCAN(Name,Value)clusterDBSCAN объект, clusterer, с каждым заданным свойством Name установите на заданный Value. Можно задать дополнительные аргументы пары "имя-значение" в любом порядке как (Name1, Value1..., NameN, ValueN). Любые незаданные свойства берут значения по умолчанию. Например,
clusterer = clusterDBSCAN('MinNumPoints',3,'Epsilon',2, ... 'EnableDisambiguation',true,'AmbiguousDimension',[1 2]);
EnableDisambiguation набор свойств к истине и AmbiguousDimension установите на [1,2].[ также возвращает альтернативный набор кластерных идентификаторов, idx,clusterids] = clusterer(X)clusterids, для использования в phased.RangeEstimator и phased.DopplerEstimator объекты. clusterids присваивает уникальный идентификатор каждой шумовой точке.
[___] = clusterer( автоматически оценочный эпсилон из матрицы входных данных, X,update)X, когда update установлен в true. Оценка использует поиск-NN k, чтобы создать набор поисковых кривых. Для получения дополнительной информации смотрите Оценочный Эпсилон. Оценкой является в среднем L новые значения Эпсилона, где L задан в EpsilonHistoryLength
Чтобы включить этот синтаксис, установите EpsilonSource свойство к 'Auto', опционально установите MaxNumPoints свойство, и также опционально набор EpsilonHistoryLength свойство.
Чтобы использовать объектную функцию, задайте Систему object™ как первый входной параметр. Например, чтобы выпустить системные ресурсы Системного объекта под названием obj, используйте этот синтаксис:
release(obj)
Создайте обнаружения расширенных объектов с измерениями в области значений и Доплере. Примите, что максимальная однозначная область значений составляет 20 м, и однозначный Доплеровский промежуток расширяет от Гц к Гц. Данные для этого примера содержатся в dataClusterDBSCAN.mat файл. Первый столбец матрицы данных представляет область значений, и второй столбец представляет Доплера.
Входные данные содержат следующие расширенные цели и ложные предупреждения:
однозначная цель, расположенная в
неоднозначная цель в Доплере, расположенном в
неоднозначная цель в области значений, расположенной в
неоднозначная цель в области значений и Доплере, расположенном в
5 ложных предупреждений
Создайте clusterDBSCAN возразите и укажите, что разрешение неоднозначности не выполняется установкой EnableDisambiguation к false. Решите для кластерных индексов.
load('dataClusterDBSCAN.mat'); cluster1 = clusterDBSCAN('MinNumPoints',3,'Epsilon',2, ... 'EnableDisambiguation',false); idx = cluster1(x);
Используйте clusterDBSCAN plot возразите функции, чтобы отобразить кластеры.
plot(cluster1,x,idx)

График показывает, что существует восемь очевидных кластеров и шесть шумовых точек. 'Dimension 1' метка соответствует области значений и 'Dimension 2' метка соответствует Доплеру.
Затем создайте другой clusterDBSCAN объект и набор EnableDisambiguation к true указывать, что кластеризация выполняется через область значений и Доплеровские контуры неоднозначности.
cluster2 = clusterDBSCAN('MinNumPoints',3,'Epsilon',2, ... 'EnableDisambiguation',true,'AmbiguousDimension',[1 2]);
Выполните кластеризацию с помощью пределов неоднозначности и затем постройте кластеризирующиеся результаты. DBSCAN кластеризирующиеся результаты правильно показывают четыре кластера и пять шумовых точек. Например, точки в областях значений близко к нулю кластеризируются с точками около 20 м, потому что максимальная однозначная область значений составляет 20 м.
amblims = [0 maxRange; minDoppler maxDoppler]; idx = cluster2(x,amblims); plot(cluster2,x,idx)

Кластерные двумерные Декартовы данные о положении с помощью clusterDBSCAN. Чтобы проиллюстрировать, как выбор эпсилона влияет на кластеризацию, сравните результаты кластеризации с Epsilon установите на 1 и Epsilon установите на 3.
Создайте случайные целевые данные о положении в xy Декартовых координатах.
x = [rand(20,2)+12; rand(20,2)+10; rand(20,2)+15];
plot(x(:,1),x(:,2),'.')
Создайте clusterDBSCAN объект с Epsilon набор свойств к 1 и MinNumPoints набор свойств к 3.
clusterer = clusterDBSCAN('Epsilon',1,'MinNumPoints',3);
Кластеризируйте данные когда Epsilon равняется 1.
idxEpsilon1 = clusterer(x);
Кластеризируйте данные снова, но с Epsilon установите на 3. Можно изменить значение Epsilon потому что это - настраиваемое свойство.
clusterer.Epsilon = 3; idxEpsilon2 = clusterer(x);
Постройте кластеризирующиеся результаты рядом друг с другом. Сделайте это путем передачи в указателях осей и заголовках в plot метод. График показывает это для Epsilon установите на 1, три кластера появляются. Когда Epsilon 3, два более низких кластера объединены в один.
hAx1 = subplot(1,2,1); plot(clusterer,x,idxEpsilon1, ... 'Parent',hAx1,'Title','Epsilon = 1') hAx2 = subplot(1,2,2); plot(clusterer,x,idxEpsilon2, ... 'Parent',hAx2,'Title','Epsilon = 3')

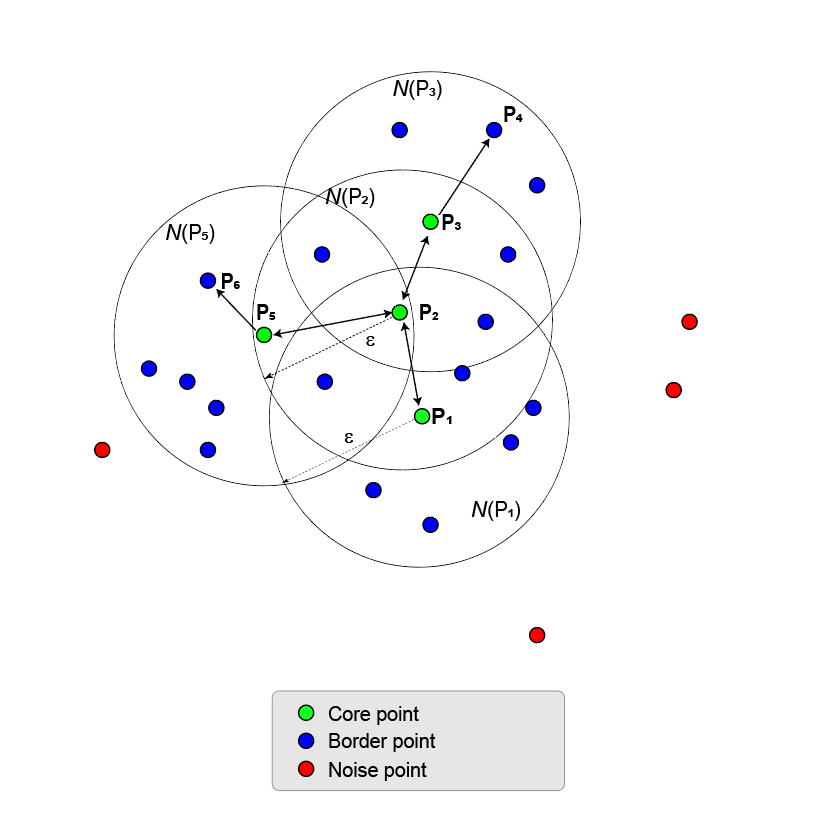
Этот раздел иллюстрирует основные принципы кластерного формирования. Рисунок показывает точки в двумерном пространстве признаков. Кластеры компактны и хорошо разделяются. Появляются несколько шумовых точек.
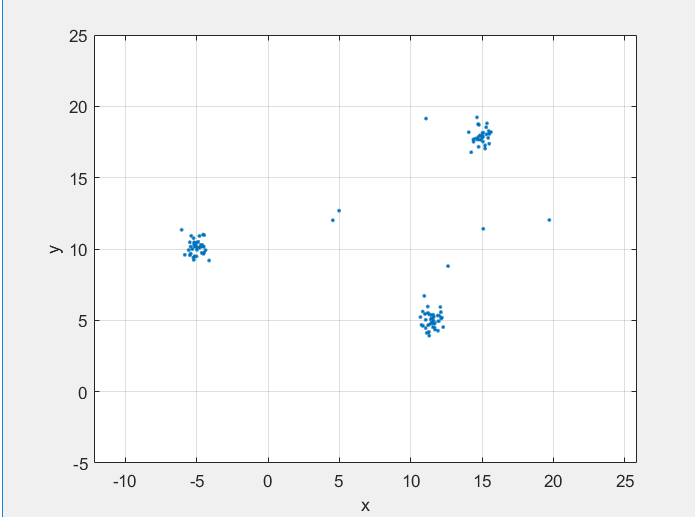
Кластеры начинают с базовых точек. Первый шаг в алгоритме идентифицирует все базовые точки.
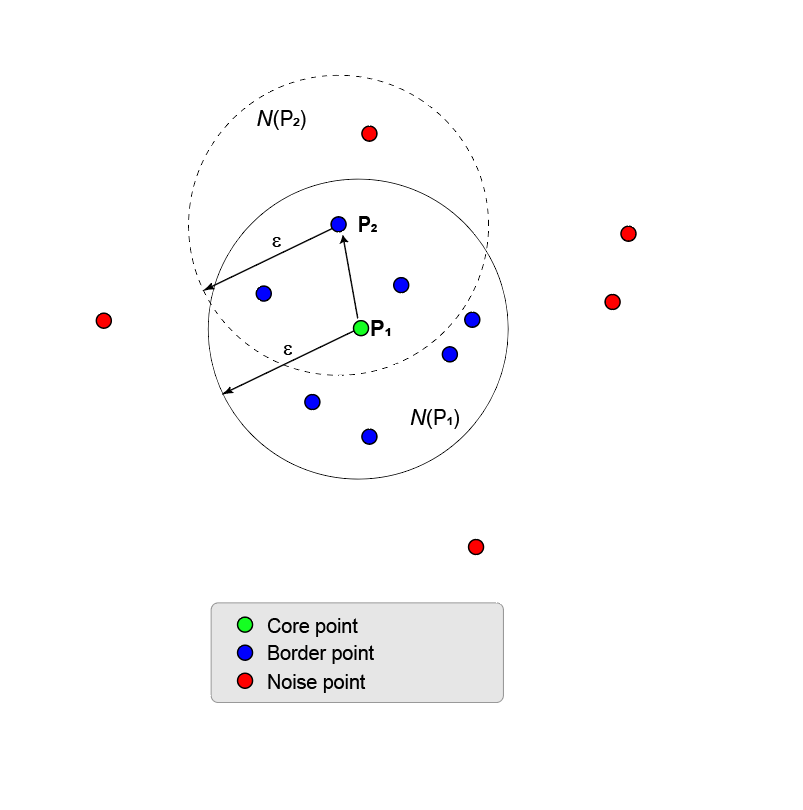
Рисунок здесь показывает точку P 1 и его ε-neighborhood N ε (P 1). ε-neighborhood имеет восемь точек (включая себя) в радиусе ε. Используя MinNumPoints свойство установить порог к 8 средним значениям, что P 1 является базовой точкой. Синие точки, которые лежат в N ε, называются пограничными точками. Эти пограничные точки являются непосредственно плотностью, достижимой от базовой точки P 1.
Никакие другие точки на рисунке не имеют достаточно соседних точек в своем ε-neighborhood, чтобы стать базовой точкой. P 2 не является базовой точкой, потому что он имеет только пять точек в своем окружении. P 2 является непосредственно плотностью, достижимой от P 1. Реверс не верен, потому что P 2 не является базовой точкой. Односторонняя стрелка, соединяющая две точки, показывает эту асимметрию.
Точки, которые выходят за пределы N ε (P 1) являются шумовыми (красными) точками и не принадлежат кластеру.
Поскольку никакие другие точки не являются базовыми точками, базовая точка и пограничные точки являются максимальным набором соединенных с плотностью точек и поэтому формируют кластер.
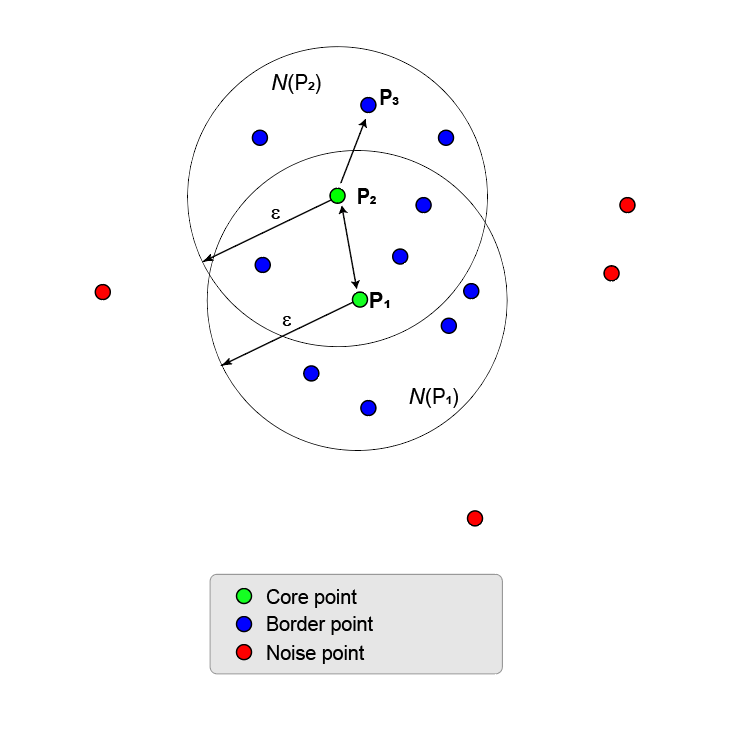
Следующий рисунок показывает больший набор точек, содержащий две базовых точки, P 1 и P 2. P 2 является пограничной точкой P 1, но P 2 также имеет достаточно точек в своем собственном окружении, чтобы стать базовой точкой. Поскольку они - и базовые точки, P 1 является непосредственно плотностью, достижимой от P 2, и P 1 является непосредственно плотностью, достижимой от P 2. Двухсторонняя стрелка, соединяющая их, показывает эту симметрию.
P 3 является непосредственно плотностью, достижимой от P 2, но не от P 1 (как обозначено односторонней стрелой). Однако P 3 называется просто плотностью, достижимой от P 1.
Поскольку никакие другие точки не являются базовыми точками, две базовых точки и их пограничные точки формируют максимальный набор соединенных с плотностью точек и формируют один кластер.
Этот процесс роста кластера может быть расширен от базовой точки до базовой точки, пока больше нет базовых точек, чтобы добавить. Базовые точки и пограничные точки принадлежат тому же кластеру. В общем случае точка, Pn является плотностью, достижимой от точки P 1, когда существует цепь базовых точек, P 1, P 2, P 3, …, Pn-1, таким образом, что каждая базовая точка Pi +1 является непосредственно плотностью, достижимой от Pi и Pn, является непосредственно плотностью, достижимой от Pn-1.
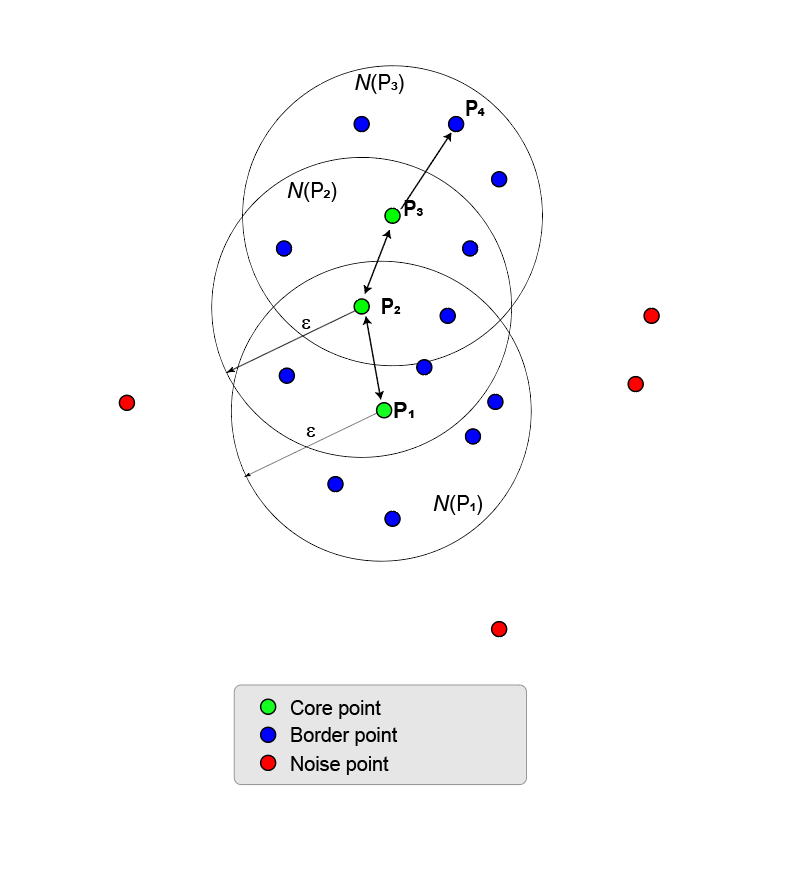
Следующая фигура иллюстрирует некоторые свойства возможности соединения плотности.
Кластер может иметь несколько переходящих цепей, например (P 1, P 2, P 3, P 4) и (P 1, P 2, P 5, P 6).
Две точки, P 6 и P 4, являются плотностью, соединенной, когда существует третья точка P 2 таким образом, что P 6 и P 4 является плотностью, достижимой от P 2.
Две плотности соединилась, точки являются не обязательно плотностью, достижимой друг от друга.
Максимальный набор плотности соединился, точки задают кластер. Это не имеет значения, какая базовая точка является стартовой базовой точкой.
Все точки в кластере являются плотностью, достижимой от всех базовых точек.
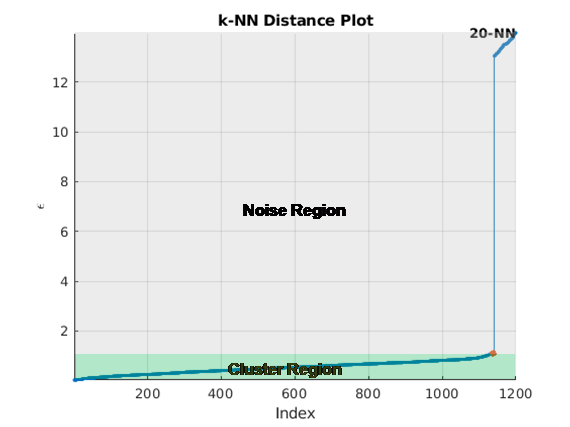
Кластеризация DBSCAN требует значения для параметра размера окружения ε. clusterDBSCAN возразите и clusterDBSCAN.estimateEpsilon функционируйте используют k - само-соседний поиск, чтобы оценить скалярный эпсилон. Позвольте D быть расстоянием любой точки P к ее kth nearestNeighbor. Задайте Dk (P) - окружение как окружение, окружающее P, который содержит его k - ближайших соседей. Существует k + 1 точка в Dk (P) - окружение включая саму точку P. Схема алгоритма оценки:
Для каждой точки найдите все точки в ее Dk (P) - окружение
Накопите расстояния во всем Dk (P) - окружения для всех точек в один вектор.
Сортировка вектора путем увеличения расстояния.
Постройте отсортированный k-dist график, который является отсортированным расстоянием против номера точки.
Найдите колено кривой. Значение расстояния в той точке является оценкой эпсилона.
Рисунок здесь показывает расстояние, построенное против индекса точки для k = 20. Колено происходит приблизительно в 1,5. Любые точки ниже этого порога принадлежат кластеру. Любые точки выше этого значения являются шумом.
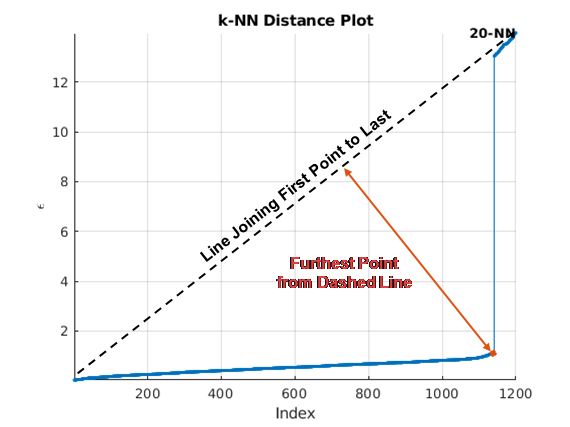
Существует несколько методов, чтобы найти колено кривой. clusterDBSCAN и clusterDBSCAN.estimateEpsilon сначала задайте линию, соединяющую первые и последние точки кривой. Ордината точки на отсортированном k-dist график дальше всего от линии и перпендикуляра к линии задает эпсилон.
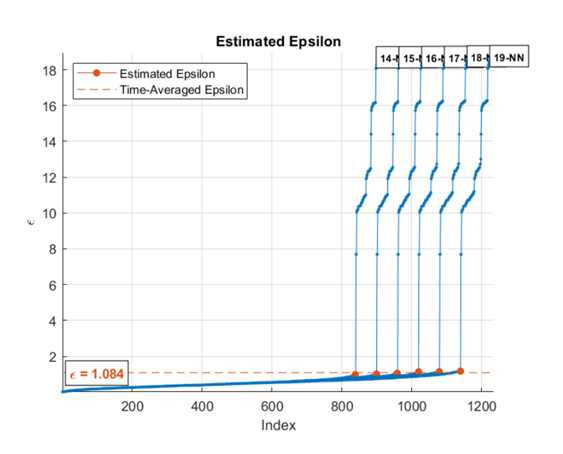
Когда вы указываете диапазон значений k, алгоритм составляет в среднем оценочные значения эпсилона для всех кривых. Этот рисунок показывает, что эпсилон довольно нечувствителен к k для k в пределах от 14 - 19.
Чтобы создать один k график расстояния-NN, установите MinNumPoints свойство, равное MaxNumPoints свойство.
[1] Эстер М., Kriegel H.-P., Сандер Дж. и Сюй X "Основанный на плотности Алгоритм для Обнаружения Кластеров в Больших Пространственных Базах данных с Шумом". Proc. 2-я Международная Конференция по Открытию Знаний и Анализу данных, Портленду, OR, Нажатию AAAI, 1996, стр 226-231.
[2] Эрих Шуберт, Йорг Сандер, Мартин Эстер, Ханс-Питер Кригель и Сяовэй Сюй. 2017. "DBSCAN, Пересмотренный, Пересмотренный: Почему и Как Необходимо (Все еще) Использовать DBSCAN". Система Базы данных Сделки ACM 42, 3, Статья 19 (июль 2017), 21 страница.
[3] Доминик Келлнер, Йенс Клаппштайн и Клаус Дитмейер, "Основанный на сетке DBSCAN для кластеризации расширенных объектов в радарных данных", 2 012 IEEE интеллектуальный симпозиум транспортных средств.
[4] Томас Вагнер, Райнхард Фегер и Андреас Штелцер, "Быстрый Основанный на сетке Алгоритм Кластеризации для Измерений Области значений/Доплера/DOA", Продолжения 13-й европейской Радарной Конференции.
[5] Mihael Ankerst, Маркус М. Бреуниг, Ханс-Питер Кригель, Йорг Сандер, "OPTICS: то, чтобы приказывать, чтобы точки идентифицировали кластеризирующуюся структуру", Proc. ACM SIGMOD ’99 международных конференций по управлению данными, Филадельфийским усилителем мощности (УМ), 1999.
clusterDBSCAN.discoverClusters | clusterDBSCAN.estimateEpsilon | clusterDBSCAN.plot
