Reinforcement Learning Toolbox™ предоставляет приложение, функции и Simulink® блокируйтесь для тренировки политик с помощью алгоритмов обучения с подкреплением, включая DQN, PPO, SAC и DDPG. Можно использовать эти политики реализовать контроллеры и алгоритмы принятия решений для сложных приложений, таких как распределение ресурсов, робототехника и автономные системы.
Тулбокс позволяет вам представлять политики и функции ценности с помощью глубоких нейронных сетей или интерполяционных таблиц и обучить их через взаимодействия со средами, смоделированными в MATLAB® или Simulink. Можно оценить сингл - или алгоритмы обучения с подкреплением мультиагента, предоставленные в тулбоксе, или разработать собственное. Можно экспериментировать с установками гиперпараметров, процессом обучения монитора, и симулировать обученных агентов или в интерактивном режиме через приложение или программно. Чтобы улучшить производительность обучения, симуляции могут быть запущены параллельно на нескольких центральных процессорах, графических процессорах, компьютерных кластерах и облаке (с Parallel Computing Toolbox™ и MATLAB Parallel Server™).
Через формат модели ONNX™ существующие политики могут быть импортированы из сред глубокого обучения, таких как TensorFlow™ Keras и PyTorch (с Deep Learning Toolbox™). Можно сгенерировать оптимизированный C, C++ и CUDA® код, чтобы развернуть обученные политики на микроконтроллерах и графических процессорах. Тулбокс включает справочные примеры, чтобы помочь вам начать.
Обучите агентов Q-обучения и SARSA решать мир сетки в MATLAB.
Обучите агента обучения с подкреплением в типовой среде марковского процесса принятия решений.
Обучите контроллер, используя обучение с подкреплением для объекта, смоделированного в Simulink как среде обучения.
Спроектируйте и обучите агента DQN системе тележки с шестом с помощью приложения Reinforcement Learning Designer.
Обучение с подкреплением является направленным на достижение цели вычислительным подходом, в котором компьютер учится выполнять задачу путем взаимодействия с неопределенной динамической средой.
Можно обучить агента обучения с подкреплением управлять неизвестным объектом.
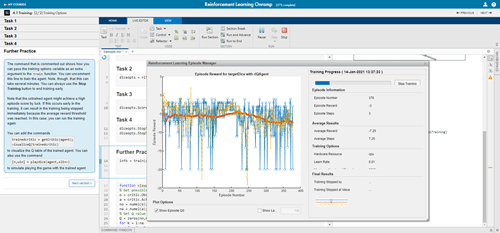
Обучение с подкреплением Onramp
Этот свободный, четырехчасовой пример обеспечивает интерактивное введение в обучение с подкреплением.
