Обучение с подкреплением является направленным на достижение цели вычислительным подходом, где компьютер учится выполнять задачу путем взаимодействия с неизвестной динамической средой. Этот подход обучения позволяет компьютеру принимать ряд решений для максимизации совокупного вознаграждения за задачу без человеческого вмешательства и не будучи явным образом запрограммированным для достижения цели. Следующая схема показывает общее представление сценария обучения с подкреплением.
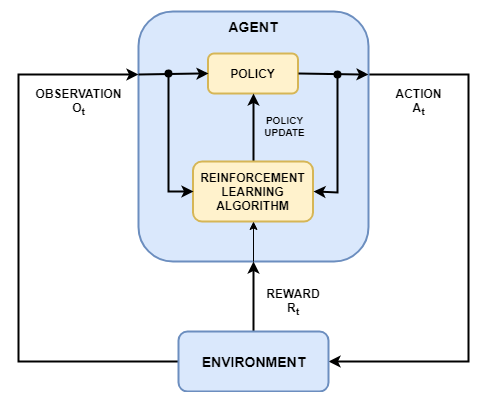
Цель обучения с подкреплением состоит в том, чтобы обучить агента выполнять задачу в неизвестной среде. Агент получает наблюдения и вознаграждение от окружения и посылает туда действия. Вознаграждение является мерой того, насколько успешно действие относительно выполнения цели задачи.
Агент содержит два компонента: политика и алгоритм обучения.
Политика является отображением, которое выбирает действия на основе наблюдений от среды. Как правило, политика представляет собой аппроксимирующую функцию с настраиваемыми параметрами, например, глубокую нейронную сеть.
Алгоритм обучения постоянно обновляет параметры политики на основе действия, наблюдений и вознаграждения. Цель алгоритма обучения состоит в том, чтобы найти оптимальную политику, которая максимизирует совокупное вознаграждение, полученное во время задачи.
Другими словами, обучение с подкреплением включает агента, изучая оптимальное поведение через повторные эмпирические взаимодействия со средой без человеческого участия.
Как пример, рассмотрите задачу парковки транспортного средства с помощью автоматизированной системы вождения. Цель этой задачи для компьютера транспортного средства (агент), чтобы припарковать транспортное средство в правильном положении и ориентации. Для этого диспетчер использует показания от камер, акселерометров, гироскопов, GPS-приемника и лидара (наблюдения), чтобы сгенерировать команды для руля и педалей тормоза и газа (действия). Команды действия отправляются в приводы, которые управляют транспортным средством. Получившиеся наблюдения зависят от приводов, датчиков, динамики аппарата, дорожного покрытия, ветра и многих других менее важных факторов. Все эти факторы, то есть, все, что не является агентом, составляет среду в обучении с подкреплением.
Чтобы изучить, как сгенерировать правильные действия от наблюдений, компьютер неоднократно пытается припарковать транспортное средство с помощью эмпирического процесса. Чтобы вести процесс обучения, вы обеспечиваете сигнал, равный единице, когда автомобиль успешно достигает желаемого положения и ориентации и нуля в противном случае (вознаграждение). Во время каждого испытания компьютер выбирает действия с помощью отображения (политика), инициализированного некоторыми значениями по умолчанию. После каждого испытания компьютер обновляет отображение, чтобы максимизировать вознаграждение (алгоритм обучения). Этот процесс продолжается, пока компьютер не обучается оптимальному отображению, которое успешно паркует автомобиль.
Общий процесс настройки агента, используя обучение с подкреплением, включает следующие шаги.
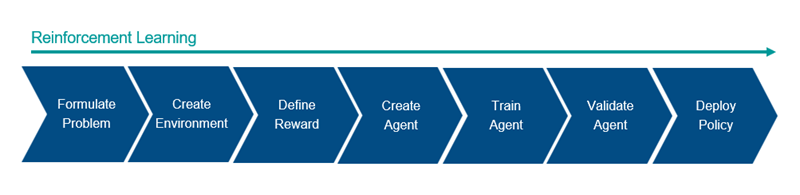
Сформулируйте проблему — Описывают задачу для обучения агента, включая то, как агент взаимодействует со средой и любыми первичными и вторичными целями, которых должен достигнуть агент.
Создайте среду — Задают среду, в которой агент действует, включая интерфейс между агентом и средой и динамической моделью среды. Для получения дополнительной информации смотрите, Создают Среды Обучения с подкреплением MATLAB и Создают Среды Обучения с подкреплением Simulink.
Задайте вознаграждение — Определяют сигнал вознаграждения, который использует для измерения своей успешности выполнения целей задачи агент и как вычислить этот сигнал средой. Для получения дополнительной информации смотрите, Задают Сигналы вознаграждения.
Создайте агента — Создают агента, который включает определение представления политики и конфигурирование алгоритма обучения агента. Для получения дополнительной информации смотрите, Создают политику и Представления Функции ценности и Агентов Обучения с подкреплением.
Обучайтесь агент — Настраивают представление политики агента с помощью заданной среды, вознаграждения и алгоритма обучения агента. Для получения дополнительной информации смотрите, Обучают Агентов Обучения с подкреплением.
Подтвердите агента — Вычисляют производительность обученного агента путем симуляции агента и среды вместе. Для получения дополнительной информации смотрите, Обучают Агентов Обучения с подкреплением.
Развернитесь политика — Развертывают обученное использование представления политики, например, сгенерированный код графического процессора. Для получения дополнительной информации смотрите, Развертывают Обученные политики Обучения с подкреплением.
Настройка агента с помощью обучения с подкреплением является итеративным процессом. Решения и результаты на более поздних этапах могут потребовать, чтобы вы возвратились к более ранней стадии в рабочем процессе обучения. Например, если учебный процесс не сходится к оптимальной политике в разумном количестве времени, вам придется обновить любое из следующих прежде, чем переобучить агента:
Настройки обучения
Конфигурацию алгоритма обучения
Представление политики
Определение сигнала вознаграждения
Сигналы действия и наблюдения
Динамику среды
