Подобно графикам эффективности памяти, сгенерированным в симуляции, можно собрать соединительную информацию трафика памяти из проекта, работающего на FPGA. Можно затем сгенерировать подобные графики эффективности. Можно также получить информацию о транзакции памяти, чтобы просмотреть в инструменте Logic Analyzer, похожем на пакетные транзакции от контроллера памяти в симуляции. Используйте эти графики контролировать эффективность реальной памяти, отладить и улучшить проект и сравнить их с эффективностью памяти, полученной в симуляции.
Чтобы включать AXI interconnect monitor (AIM) IP в вашем проекте, в параметрах конфигурации модели, выбирают опцию Include AXI interconnect monitor под Hardware Implementation> Target hardware resources> FPGA design (debug). IP AXI interconnect monitor собирает информацию из проекта, в то время как это работает на FPGA. Можно запросить эту информацию из MATLAB® при помощи связи JTAG. Все ведущие устройства памяти в вашем FPGA соединяются с IP AXI interconnect monitor. Эти ведущие устройства могут включать Memory Channel и блоки Memory Traffic Generator что вы сгенерированный HDL-код для или любые другие ведущие устройства в вашем проекте.
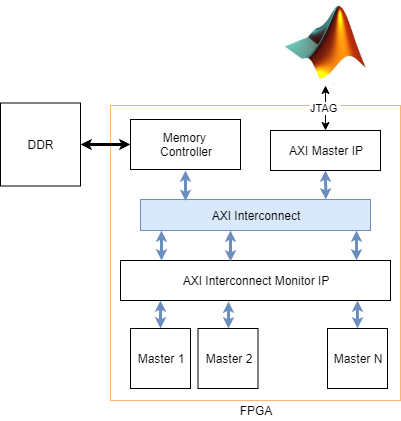
Инструмент SoC Builder генерирует скрипт испытательного стенда JTAG для вашего проекта. Скрипт собирает показатели производительности из AXI interconnect monitor и запускает приложение графика эффективности, которое строит графики эффективности памяти для полосы пропускания, количества пакетов и задержек транзакции. Эти графики похожи на графики эффективности памяти в симуляции. Можно также изменить скрипт, чтобы собрать и отобразить формы волны транзакции памяти, похожие на пакетные формы волны контроллера памяти в симуляции. Для получения информации об эффективности памяти симуляции см. Графики Эффективности Симуляции и Буферный и Пакетные Формы волны.
Для примера смотрите, Анализируют Полосу пропускания Памяти Используя Генераторы Трафика, которая показывает как эффективности памяти монитора и в симуляции и при работе FPGA. Скрипт, сгенерированный инструментом SoC Builder, использует связь JTAG, чтобы включить любые генераторы трафика в вашем проекте, и затем производит информацию об эффективности памяти от IP AXI interconnect monitor с такой скоростью, как это может. Интервал выборки зависит от задержки JTAG, которая обычно является от 10 мс до 20 мс. Скрипт затем отображает графики, похожие на графики эффективности от блока Memory Controller в вашей симуляции. График отображает полосу пропускания, количество пакетов и задержку транзакции для каждого ведущего устройства.
Примечание
Ведущее устройство AXI самостоятельно не соединяется с AXI interconnect monitor. Поэтому аппаратная диагностика не включает графики использования памяти для единственных испытательным стендом ведущих устройств, которые инициализируют память предопределенными данными.
Скрипт собирает показатели производительности из AXI interconnect monitor и запускает приложение графика эффективности.
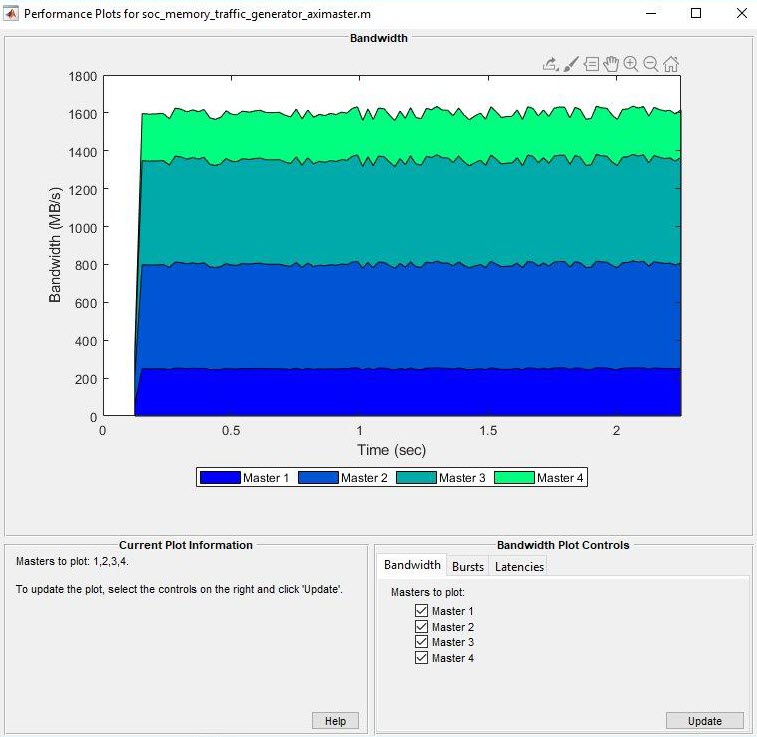
Во вкладке Bandwidth выберите ведущие устройства, для которых вы хотите изобразить полосу пропускания в виде графика. Нажмите Create Plot, чтобы видеть полосу пропускания, в мегабайтах в секунду, для выбранных ведущих устройств по длительности времени выполнения. Этот рисунок показывает полосу пропускания для Анализировать Полосы пропускания Памяти Используя пример Генераторов Трафика.
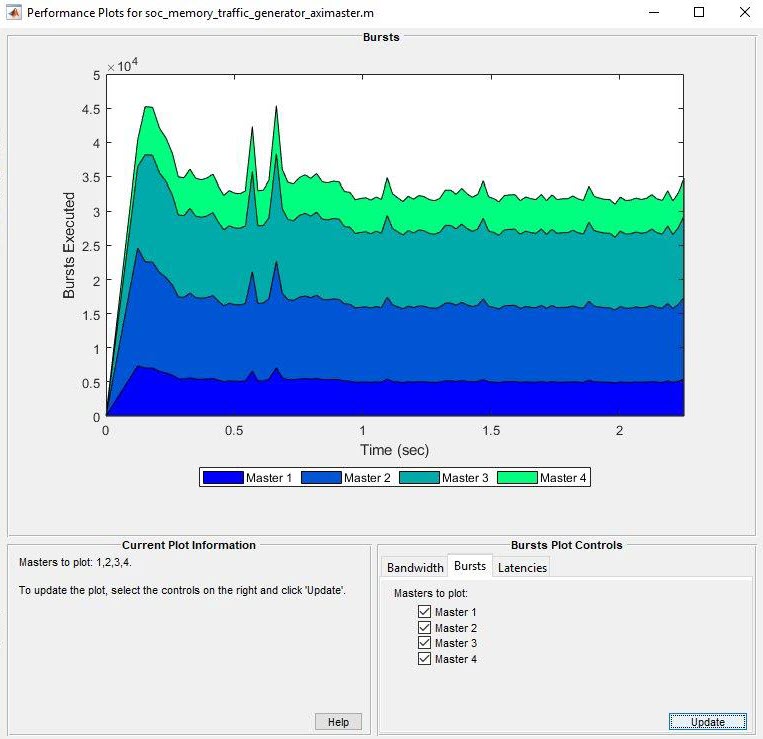
Во вкладке Bursts выберите ведущие устройства, для которых вы хотите изобразить пакеты в виде графика. Нажмите Create Plot, чтобы видеть количество пакетов, выполняемых для выбранного ведущего устройства по длительности времени выполнения. Этот рисунок показывает, что пакет значит Анализировать Полосу пропускания Памяти Используя пример Генераторов Трафика.
Во вкладке Latencies выберите ведущее устройство, для которого вы хотите изобразить задержки в виде графика. Нажмите Create Plot, чтобы видеть задержку для выбранных ведущих устройств по длительности времени выполнения. Это изображение показывает общую задержку для Master 1 в Анализировать Полосе пропускания Памяти Используя пример Генераторов Трафика. Можно затем увеличить масштаб, чтобы анализировать пиковую мгновенную задержку.
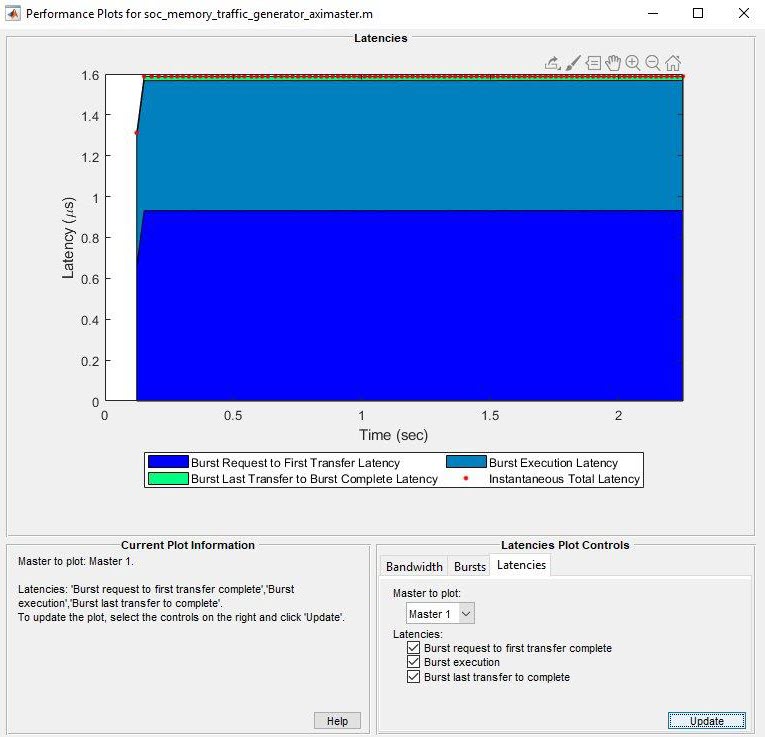
Можно выбрать из любой из этих опций:
Burst request to first transfer complete — Эта опция показывает время, которое требуется с момента, ведущее устройство выпускает запрос транзакции к первой передаче данных. Эта задержка составляет арбитраж или взаимосвязанные задержки.
Burst execution — Эта опция показывает время, это берет из первой передачи данных к пакету последнюю передачу.
Burst last transfer to complete — Эта опция показывает время, которое требуется от последней передачи до завершенной транзакции. В случае транзакции чтения это 0.
Instantaneous Total Latency — Эта опция показывает дискретные общие измерения задержки на пакет.
Каждое построенное значение задержки является в среднем соответствующей задержкой, измеренной от транзакций памяти по интервалу выборки. Следующий рисунок показывает Основную запись протокола AXI4, и считайте транзакцию на оборудовании, показывающем каждую из этих задержек.
Write Transaction
![]()
Read Transaction
![]()
В транзакции чтения Burst last transfer to complete latency является нулем.
В Profile режим, collectMemoryStatistics функциональные демонстрационные метрики памяти: полоса пропускания, пакет и значения задержек от оборудования после каждой выборки. После этого функция сбрасывает метрические счетчики и затем запускает счетчики снова для следующей выборки. Если какой-либо из метрических счетчиков превышает предел 232 — 1 в интервале выборки, счетчик переполнен, и соответствующая выборка обозначается с * в графике.
Можно также изменить сгенерированный скрипт, чтобы сконфигурировать AXI interconnect monitor, чтобы собрать данные о событиях для каждой пакетной транзакции. Можно просмотреть эти события в средстве просмотра формы волны Logic Analyzer, чтобы исследовать арбитражное поведение. Задайте количество транзакций, чтобы получить, Trace capture depth, в параметрах конфигурации модели, под Hardware Implementation> Target hardware resources> FPGA design (debug).
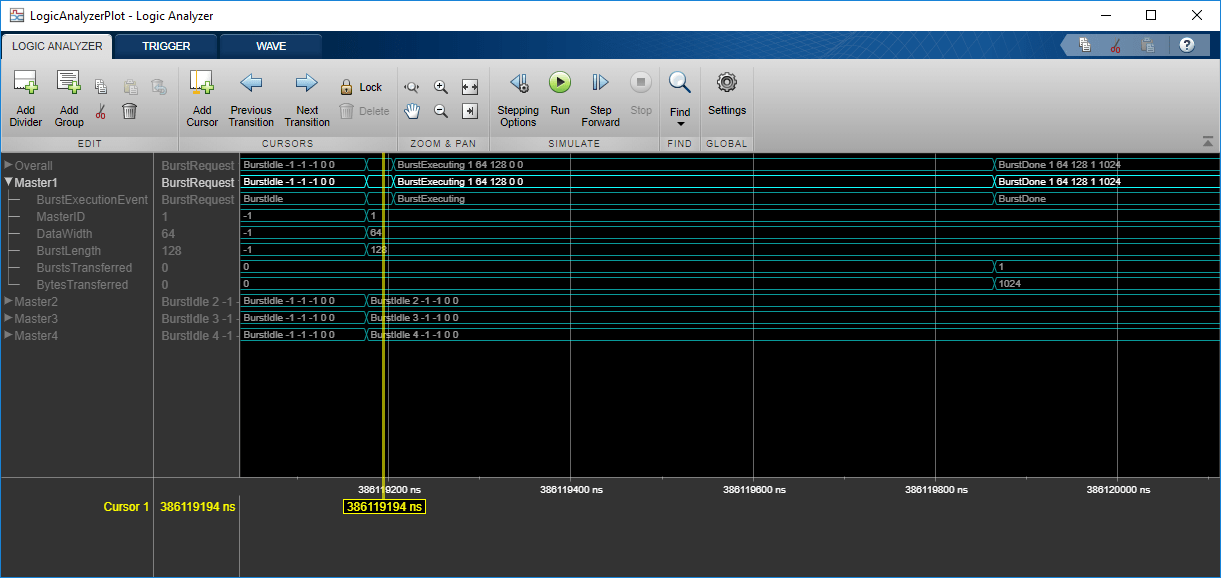
Формы волны показывают тип события (BurstIdle, BurstRequest, BurstExecuting, или BurstDone) и эти параметры пакетной транзакции:
MasterID – Идентификационный номер ведущего устройства памяти, которое выполнило запрос
DataWidth – Ширина данных в битах
BurstLength – Количество слов данных в пакетном запросе
BurstsTransferred – Количество пакетов в этом запросе (допустимый только с BurstDone событие
BytesTransferred – Количество байтов в этом запросе (допустимый только с BurstDone событие
Можно сравнить эти формы волны с формами волны, полученными от блока Memory Controller в симуляции.
AXI interconnect monitor (AIM) является ядром IP, которое собирает показатели производительности для основанного на AXI проекта FPGA. Создайте socIPCore возразите, чтобы настроить и сконфигурировать IP AIM и использовать socMemoryProfiler объект получить и отобразить данные.
Для примера того, как сконфигурировать и запросить IP AIM в вашем проекте с помощью MATLAB в качестве Ведущего устройства AXI, смотрите, Анализируют Полосу пропускания Памяти Используя Генераторы Трафика. А именно, рассмотрите soc_memory_traffic_generator_axi_master.m скрипт, который конфигурирует и контролирует проект на устройстве.
AXI interconnect monitor может собрать два типа данных. Выберите Profile режим, чтобы собрать среднюю задержку транзакции и количества байтов и пакетов. В этом режиме можно открыть графический инструмент эффективности, и затем сконфигурировать инструмент, чтобы построить полосу пропускания, разорвать количество и задержку транзакции. Выберите Trace режим, чтобы собрать подробные данные о событиях транзакции памяти и просмотреть данные как формы волны.
perfMonMode = 'Profile'; % or 'Trace'
Чтобы получить диагностические показатели производительности из вашего сгенерированного проекта FPGA, необходимо настроить связь JTAG с устройством из MATLAB. Загрузите .mat файл, который содержит структуры, выведенные из параметров конфигурации платы. Этот файл был сгенерирован инструментом SoC Builder. Эти структуры описывают межсоединение памяти и ведущую настройку, такую как буферные размеры и адреса. Используйте socHardwareBoard возразите, чтобы настроить связь JTAG.
load('soc_memory_traffic_generator_zc706_aximaster.mat'); hwObj = socHardwareBoard('Xilinx Zynq ZC706 evaluation kit','Connect',false); AXIMasterObj = socAXIMaster(hwObj);
socIPCore объект обеспечивает функцию, которая выполняет эту инициализацию. Затем настройте socMemoryProfiler объект собрать метрики.apmCoreObj = socIPCore(AXIMasterObj,perf_mon,'PerformanceMonitor','Mode',perfMonMode); initialize(apmCoreObj); profilerObj = socMemoryProfiler(hwObj,apmCoreObj);
Чтобы получить показатели производительности или данные сигнала из проекта, работающего на FPGA, используйте socMemoryProfiler функции объекта.
Для Profile режим, вызовите collectMemoryStatistics функция в цикле.
NumRuns = 100; for n = 1:NumRuns collectMemoryStatistics(profilerObj); end
Для Trace режим, вызовите collectMemoryStatistics функция однажды. Эта функция мешает IP писать транзакции в FIFO в IP AXI interconnect monitor, несмотря на то, что транзакции продвигаются межсоединение. Установите размер транзакции FIFO, Trace capture depth, в параметрах конфигурации модели, под Hardware Implementation> Target hardware resources> FPGA design (debug).
collectMemoryStatistics(profilerObj);
Визуализируйте данные о производительности с помощью plotMemoryStatistics функция. В Profile режим, эта функция открывает графический инструмент эффективности, и можно сконфигурировать инструмент, чтобы построить полосу пропускания, разорвать количество и среднюю задержку транзакции. В Trace режим, эта функция открывает инструмент Logic Analyzer, чтобы просмотреть пакетные данные о событиях транзакции.
plotMemoryStatistics(profilerObj);
Memory Controller | socMemoryProfiler | collectMemoryStatistics | plotMemoryStatistics
