В этом примере показано, как создать и сравнить различные наивные классификаторы Байеса с помощью приложения Classification Learner, и экспортировать обученные модели в рабочую область, чтобы делать прогнозы для новых данных.
Наивные классификаторы Байеса используют теорему Бейеса и делают предположение, что предикторы независимы друг от друга в каждом классе. Однако классификаторы работают хорошо, даже когда предположение независимости не верно. Можно использовать наивного Бейеса с двумя или больше классами в Classification Learner. Приложение позволяет вам обучать Гауссову наивную модель Бейеса или ядерную наивная модель Бейеса индивидуально или одновременно.
Эта таблица приводит доступные наивные модели Байеса в Classification Learner и вероятностных распределениях, используемых каждой моделью, чтобы соответствовать предикторам.
| Модель | Числовой предиктор | Категориальный предиктор |
|---|---|---|
| Гауссов наивный классификатор Бейеса | Распределение Гаусса (или нормальное распределение) | многомерное полиномиальное распределение |
| Ядерный наивный Бейес | Ядерное распределение Можно задать тип ядра и поддержку. Classification Learner автоматически определяет ширину ядра с помощью базового fitcnb функция. | многомерное полиномиальное распределение |
Этот пример использует ирисовый набор данных Фишера, который содержит измерения цветов (лепестковая длина, лепестковая ширина, длина чашелистика и ширина чашелистика) для экземпляров от трех разновидностей. Обучите наивные классификаторы Байеса предсказывать разновидности на основе измерений предиктора.
В MATLAB® Командное окно, загрузите Фишера, диафрагмируют набор данных и составляют таблицу предикторов измерения (или функции) использование переменных из набора данных.
fishertable = readtable('fisheriris.csv');Кликните по вкладке Apps, и затем кликните по стреле справа от раздела Apps, чтобы открыть галерею Apps. В группе Machine Learning and Deep Learning нажмите Classification Learner.
На вкладке Classification Learner, в разделе File, выбирают New Session > From Workspace.

В диалоговом окне New Session from Workspace выберите таблицу fishertable из списка Data Set Variable (при необходимости).
Как показано в диалоговом окне, приложение выбирает переменные отклика и переменные предикторы на основе их типа данных. Лепесток и длина чашелистика и ширина являются предикторами, и разновидность является ответом, который вы хотите классифицировать. В данном примере не изменяйте выборы.
Чтобы принять схему валидации по умолчанию и продолжиться, нажмите Start Session. Опция валидации по умолчанию является перекрестной проверкой, чтобы защитить от сверхподбора кривой.
Classification Learner создает график рассеивания данных.
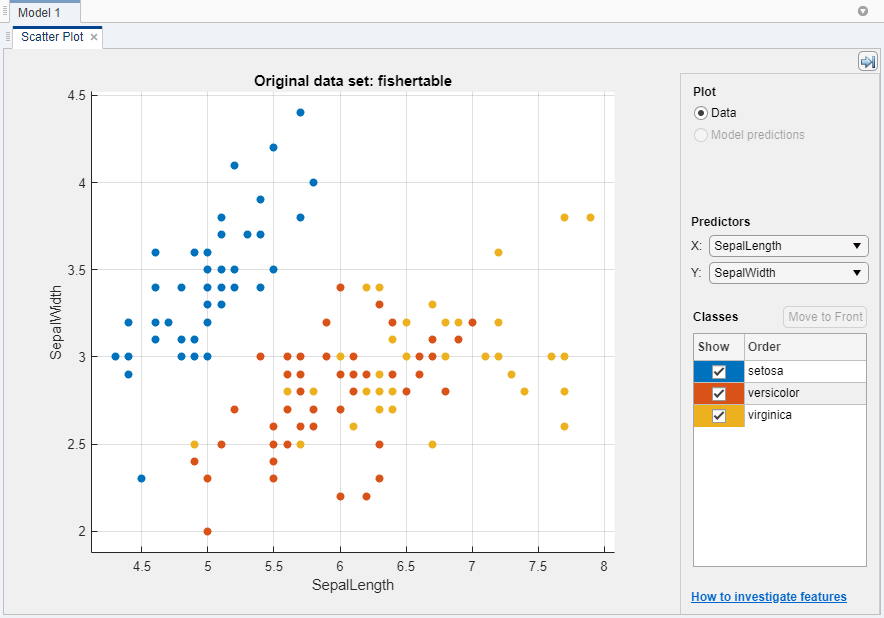
Используйте график рассеивания, чтобы заняться расследованиями, какие переменные полезны для предсказания ответа. Выберите различные варианты на X и списках Y под Predictors, чтобы визуализировать распределение разновидностей и измерения. Наблюдайте, какие переменные разделяют цвета разновидностей наиболее ясно.
setosa разновидность (синие точки) легко разделить от других двух разновидностей со всеми четырьмя предикторами. versicolor и virginica разновидности намного ближе вместе во всех измерениях предиктора и перекрытии, особенно когда вы строите длину чашелистика и ширину. setosa легче предсказать, чем другие две разновидности.
Создайте наивную модель Bayes. На вкладке Classification Learner, в разделе Model Type, кликают по стреле, чтобы открыть галерею. В группе Naive Bayes Classifiers нажмите Gaussian Naive Bayes. Обратите внимание на то, что Classification Learner отключает кнопку Advanced в разделе Model Type, потому что этот тип модели не имеет никаких расширенных настроек.

В разделе Training нажмите Train.
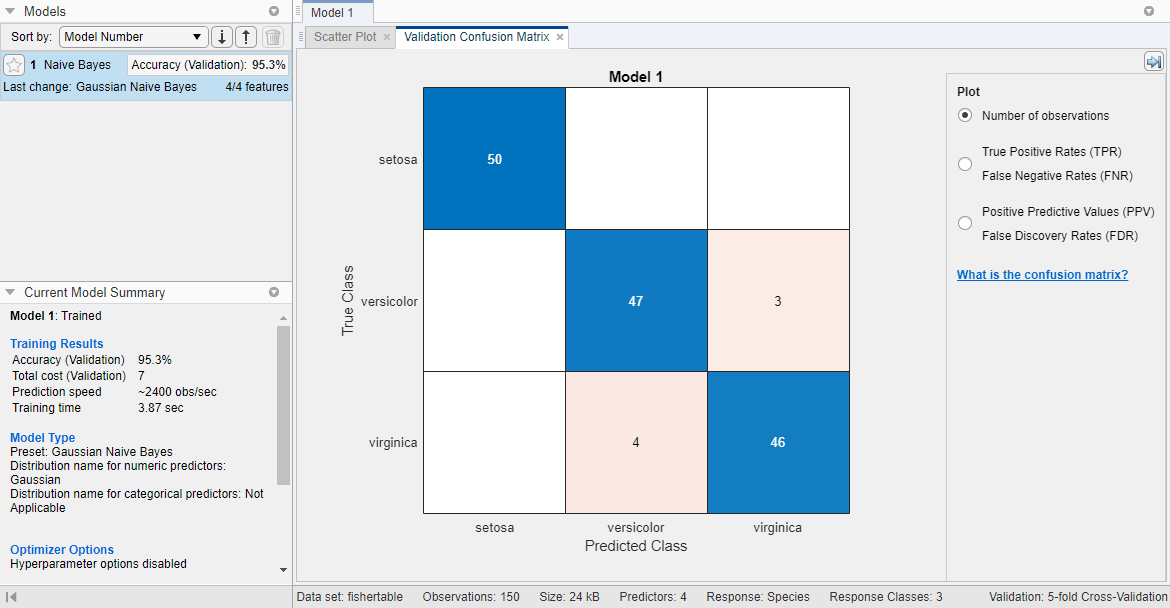
Приложение создает Гауссову наивную модель Bayes и строит матрицу беспорядка валидации.
Отображения приложения модель Gaussian Naive Bayes в панели Models. Проверяйте счет проверки допустимости модели в поле Accuracy (Validation). Счет показывает, что модель выполняет хорошо.
Для модели Gaussian Naive Bayes, по умолчанию, приложение моделирует распределение числовых предикторов с помощью Распределения Гаусса и моделирует распределение категориальных предикторов с помощью многомерного распределения многочлена (MVMN).
Примечание
Валидация вводит некоторую случайность в результаты. Ваши результаты проверки допустимости модели могут варьироваться от результатов, показанных в этом примере.
Исследуйте график рассеивания путем нажатия на вкладку Scatter Plot для Model 1. X указывает на неправильно классифицированные точки. Синие точки (setosa разновидности), все правильно классифицируются, но другие две разновидности неправильно классифицировали точки. Под Plot, переключателем между Data и опциями Model predictions. Наблюдайте цвет неправильного (X) точки. Или, чтобы просмотреть только неправильные точки, снимите флажок Correct.
Обучите ядро наивная модель Bayes сравнению. На вкладке Classification Learner, в разделе Model Type, нажимают Kernel Naive Bayes. Обратите внимание на то, что Classification Learner включает кнопку Advanced, потому что этот тип модели имеет расширенные настройки.

Отображения приложения черновое ядро наивная модель Bayes в панели Models.
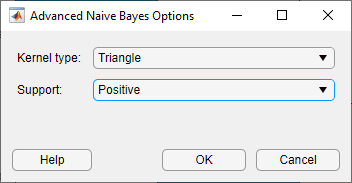
В разделе Model Type нажмите Advanced, чтобы изменить настройки в Усовершенствованном Наивном Байесовом Окне параметров. Выберите Triangle из списка Kernel Type, и выбирают Positive из списка Support. Нажмите OK.
Примечание
Настройки в Усовершенствованном Наивном Байесовом Окне параметров доступны для текущих данных только. Указывание на Kernel Type отображается, подсказка "Указывают, что функция сглаживания Ядра для непрерывных переменных", и указывающий на Support отображает, подсказка "Задают Ядро, сглаживающее поддержку плотности непрерывных переменных".
В разделе Training нажмите Train, чтобы обучить новую модель.
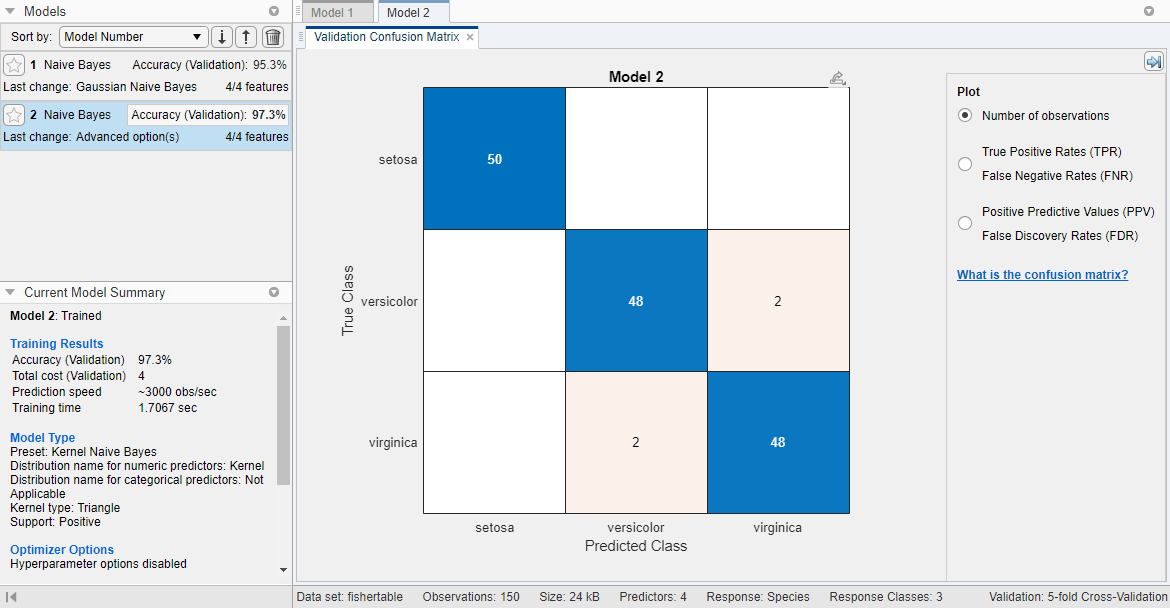
Панель Models теперь включает новое ядро наивная модель Bayes. Его счет проверки допустимости модели лучше, чем счет к Гауссовой наивной модели Bayes. Приложение подсвечивает счет Accuracy (Validation) лучшей модели путем выделения его в поле.
В панели Models кликните по каждой модели, чтобы просмотреть и сравнить результаты. Чтобы просмотреть результаты для модели, смотрите панель Current Model Summary. Панель Current Model Summary отображает метрики Training Results, вычисленные на набор валидации.
Обучите Гауссову наивную модель Bayes и ядро наивная модель Bayes одновременно. На вкладке Classification Learner, в разделе Model Type, нажимают All Naive Bayes. Classification Learner отключает кнопку Advanced. В разделе Training нажмите Train.
Приложение обучает один из каждого наивного типа модели Бейеса и подсвечивает счет Accuracy (Validation) лучшей модели или моделей. Classification Learner отображает матрицу беспорядка валидации для первой модели (модель 3.1).
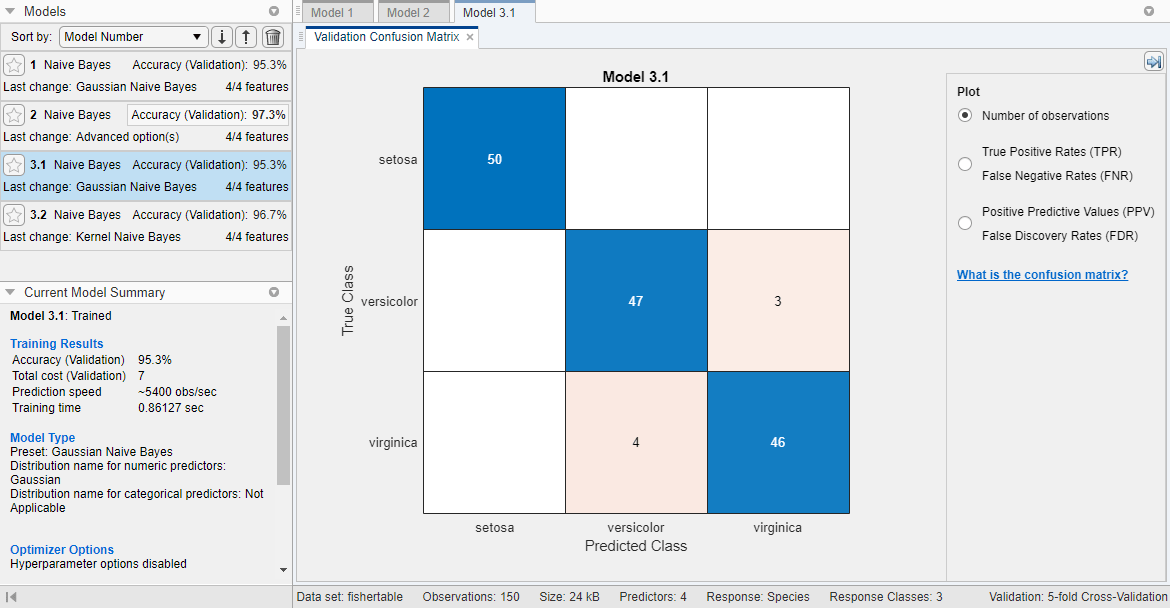
В панели Models кликните по модели, чтобы просмотреть результаты. Например, выберите модель 2. Исследуйте график рассеивания на обученную модель. На вкладке Classification Learner, в разделе Plots, кликают по стреле, чтобы открыть галерею, и затем нажать Scatter в группе Validation Results. Попытайтесь строить различные предикторы. Неправильно классифицированные точки появляются как X.
Чтобы смотреть точность предсказаний в каждом классе, на вкладке Classification Learner, в разделе Plots, кликают по стреле, чтобы открыть галерею, и затем нажать Confusion Matrix (Validation) в группе Validation Results. Отображения приложения матрица истинного класса и предсказанных результатов класса.
В панели Models кликните по другим моделям и сравните их результаты.
В панели Models кликните по модели с самым высоким счетом Accuracy (Validation). Чтобы улучшить модель, попытайтесь изменить ее функции. Например, смотрите, можно ли улучшить модель путем удаления функций с низкой предсказательной силой.
На вкладке Classification Learner, в разделе Features, нажимают Feature Selection.
В диалоговом окне Feature Selection снимите флажки для PetalLength и PetalWidth, чтобы исключить их из предикторов и нажать OK. Новая черновая модель (модель 4) появляется в панели Models с новыми настройками (2/4 функции), на основе модели, которую вы выбрали.
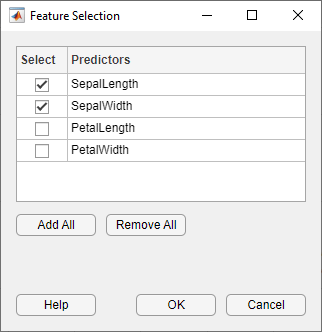
В разделе Training нажмите Train, чтобы обучить новую наивную модель Bayes, которая использует новые опции предиктора.
Чтобы определить, какие предикторы включены, кликните по модели в панели Models, затем нажмите Feature Selection в разделе Features и примечании, какие флажки устанавливаются. Модель только с измерениями чашелистика (модель 4) имеет намного более низкий счет Accuracy (Validation), чем модели, содержащие все предикторы.
Обучите другую наивную модель Bayes только включая лепестковые измерения. Измените выборы в диалоговом окне Feature Selection и нажмите OK. Затем нажмите Train.
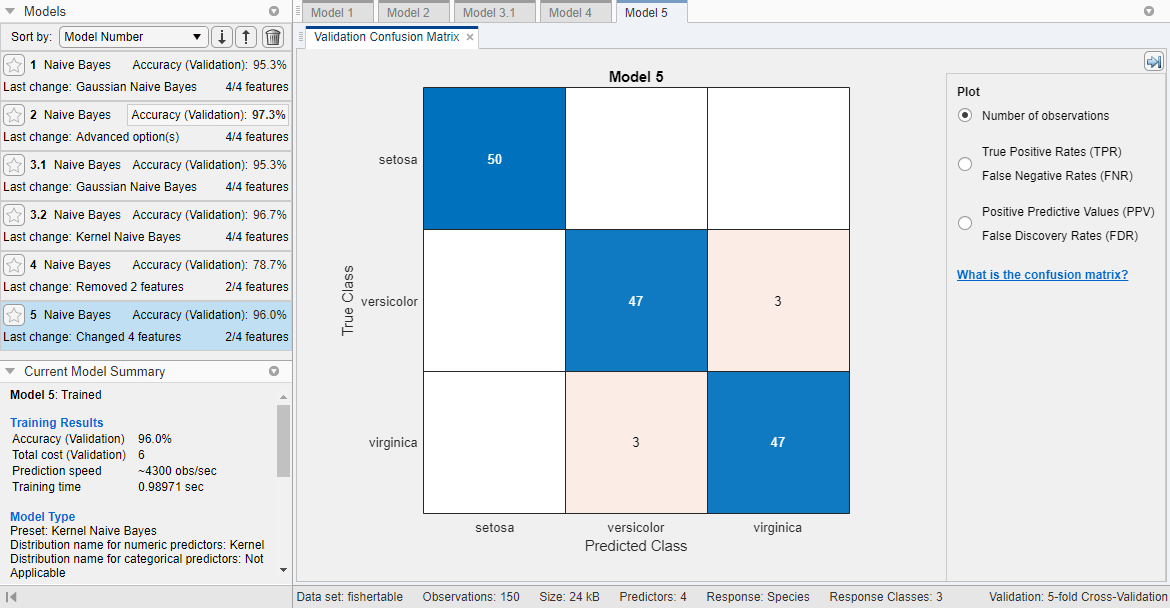
Модель, обученная с помощью только лепестковые измерения (модель 5), выполняет сравнительно к модели, содержащей все предикторы. Если сбор данных является дорогим или трудным, вы можете предпочесть модель, которая выполняет удовлетворительно без некоторых предикторов.
Чтобы исследовать функции, чтобы включать или исключить, используйте параллельный график координат. На вкладке Classification Learner, в разделе Plots, кликают по стреле, чтобы открыть галерею и нажать Parallel Coordinates в группе Validation Results.
В панели Models кликните по модели с самым высоким счетом Accuracy (Validation). Чтобы улучшить модель далее, попытайтесь изменить наивные настройки Bayes (при наличии). На вкладке Classification Learner, в разделе Model Type, нажимают Advanced. Вспомните, что кнопка Advanced включена только для некоторых моделей. В диалоговом окне измените настройки и нажмите OK. Затем обучите новую модель путем нажатия на Train в разделе Training.
Экспортируйте обученную модель в рабочую область. На вкладке Classification Learner, в разделе Export, выбирают Export Model > Export Model. См. Модель Классификации Экспорта, чтобы Предсказать Новые Данные.
Исследуйте код на обучение этот классификатор. В разделе Export нажмите Generate Function.
Используйте тот же рабочий процесс, чтобы оценить и сравнить другие типы классификатора, которые можно обучить в Classification Learner.
Попробовать все nonoptimizable предварительные установки модели классификатора, доступные для вашего набора данных:
Кликните по стреле на разделе Model Type, чтобы открыть галерею классификаторов.
В группе Get Started нажмите All, затем нажмите Train в разделе Training.
Для получения информации о других типах классификатора смотрите, Обучают Модели Классификации в Приложении Classification Learner.
