Можно использовать приложение Regression Learner, чтобы автоматически обучить выбор различных моделей на данных. Используйте автоматизированное обучение быстро попробовать выбор типов модели, и затем исследовать многообещающие модели в интерактивном режиме. Чтобы начать, попробуйте эти опции сначала:
| Кнопки модели регрессии Запуска | Описание |
|---|---|
| All Quick-To-Train | Попробуйте кнопку All Quick-To-Train сначала. Приложение обучает все типы модели, которые обычно быстры, чтобы обучаться. |
| All | Используйте кнопку All, чтобы обучить все доступные nonoptimizable типы модели. Обучает каждый тип независимо от любых предшествующих обученных моделей. Может быть длительным. |
Чтобы узнать больше об автоматизированном обучении модели, смотрите Автоматизированное Обучение Модели Регрессии.
Если вы хотите исследовать модели по одному, или если вы уже знаете, какой тип модели вы хотите, можно выбрать отдельные модели или обучить группу того же типа. Чтобы видеть все доступные опции модели регрессии, на вкладке Regression Learner, кликают по стрелке в разделе Model Type, чтобы расширить список моделей регрессии. nonoptimizable опции модели в галерее являются предварительно установленными начальными точками с различными настройками, подходящими для области значений различных проблем регрессии. Чтобы использовать optimizable опции модели и гиперпараметры модели мелодии автоматически, смотрите Гипероптимизацию параметров управления в Приложении Regression Learner.
Для справки, выбирая лучший тип модели для вашей проблемы, см., что таблицы показывают типичные характеристики различных типов модели регрессии. Выберите компромисс, который вы хотите в скорости, гибкости и interpretability. Лучший тип модели зависит от ваших данных.
Совет
Чтобы постараться не сверхсоответствовать, ищите менее гибкую модель, которая обеспечивает достаточную точность. Например, ищите простые модели, такие как деревья регрессии, которые быстры и легки интерпретировать. Если модели не являются достаточно точным предсказанием ответа, выбирают другие модели с более высокой гибкостью, такие как ансамбли. Чтобы управлять гибкостью, смотрите детали для каждого типа модели.
Характеристики типов модели регрессии
| Тип модели регрессии | Interpretability |
|---|---|
| Модели линейной регрессии
| Легкий |
| Деревья регрессии
| Легкий |
| Машины опорных векторов
| Легкий для линейного SVMs. Трудный для других ядер. |
| Гауссовы модели регрессии процесса
| Трудно |
| Ансамбли деревьев
| Трудно |
| Нейронные сети
| Трудно |
Чтобы считать описание каждой модели в Regression Learner, переключитесь на представление деталей в списке всех предварительных установок модели.
Совет
nonoptimizable модели в галерее Model Type являются предварительно установленными начальными точками с различными настройками. После того, как вы выбираете тип модели, такой как деревья регрессии, попробуйте обучение все nonoptimizable предварительные установки, чтобы видеть, какой производит лучшую модель с вашими данными.
Для инструкций по рабочему процессу смотрите, Обучают Модели Регрессии в Приложении Regression Learner.
В Regression Learner все типы модели поддерживают категориальные предикторы.
Совет
Если у вас есть категориальные предикторы со многими уникальными значениями, учебные линейные модели со взаимодействием или квадратичными терминами, и пошаговые линейные модели могут использовать большую память. Если модели не удается обучаться, попытайтесь удалить эти категориальные предикторы.
Модели линейной регрессии имеют предикторы, которые линейны в параметрах модели, легки интерпретировать и быстры для того, чтобы сделать предсказания. Эти характеристики делают модели линейной регрессии популярными моделями, чтобы попробовать сначала. Однако очень ограниченная форма этих моделей означает, что у них часто есть низкая прогнозирующая точность. После того, чтобы подбирать модель линейной регрессии попытайтесь создать более гибкие модели, такие как деревья регрессии, и сравните результаты.
Совет
В галерее Model Type нажмите All Linear
![]() , чтобы попробовать каждую из опций линейной регрессии и видеть, какие настройки производят лучшую модель с вашими данными. Выберите лучшую модель в панели Models и попытайтесь улучшить ту модель при помощи выбора признаков и изменяющий некоторые расширенные настройки.
, чтобы попробовать каждую из опций линейной регрессии и видеть, какие настройки производят лучшую модель с вашими данными. Выберите лучшую модель в панели Models и попытайтесь улучшить ту модель при помощи выбора признаков и изменяющий некоторые расширенные настройки.
| Тип модели регрессии | Interpretability | Гибкость модели |
|---|---|---|
| Linear | Легкий | Очень низко |
| Interactions Linear | Легкий | Средняя |
| Robust Linear | Легкий | Очень низко. Менее чувствительный к выбросам, но может не спешить обучаться. |
| Stepwise Linear | Легкий | Средняя |
Совет
Для примера рабочего процесса смотрите, Обучают Деревья Регрессии Используя Приложение Regression Learner.
Regression Learner использует fitlm функция, чтобы обучаться Линейный, Линейные Взаимодействия, и модели Robust Linear. Приложение использует stepwiselm функция, чтобы обучить модели Stepwise Linear.
Для Линейного Линейные Взаимодействия, и модели Robust Linear можно установить эти опции:
Terms
Задайте который термины использовать в линейной модели. Можно выбрать из:
Linear. Постоянный термин и линейные члены в предикторах
Interactions. Постоянный термин, линейные члены, и периоды взаимодействия между предикторами
Pure Quadratic. Постоянный термин, линейные члены и термины, которые чисто квадратичны в каждом из предикторов
Quadratic. Постоянный термин, линейные члены и квадратичные термины (включая взаимодействия)
Robust option
Задайте, использовать ли устойчивую целевую функцию и сделать вашу модель менее чувствительной к выбросам. При использовании этой опции подходящий метод автоматически присваивает более низкие веса точкам данных, которые, более вероятно, будут выбросами.
Пошаговая линейная регрессия запускается с первоначальной модели и систематически добавляет и удаляет термины к основанному на модели на объяснительной силе этих инкрементно больших и меньших моделей. Для моделей Stepwise Linear можно установить эти опции:
Initial terms
Задайте термины, которые включены в первоначальную модель пошаговой процедуры. Можно выбрать из Constant, Linear, Interactions, Pure Quadratic, и Quadratic.
Upper bound on terms
Задайте самый высокий порядок терминов, которые пошаговая процедура может добавить в модель. Можно выбрать из Linear, Interactions, Pure Quadratic, и Quadratic.
Maximum number of steps
Задайте максимальное количество различных линейных моделей, которые можно попробовать в пошаговой процедуре. Чтобы ускорить обучение, попытайтесь сократить максимальное количество шагов. Выбор маленького максимального количества шагов уменьшает ваши возможности нахождения хорошей модели.
Совет
Если у вас есть категориальные предикторы со многими уникальными значениями, учебные линейные модели со взаимодействием или квадратичными терминами, и пошаговые линейные модели могут использовать большую память. Если модели не удается обучаться, попытайтесь удалить эти категориальные предикторы.
Деревья регрессии легко интерпретировать, быстро для подбора кривой и предсказания, и низко на использовании памяти. Попытайтесь вырастить меньшие деревья с меньшим количеством больших листов, чтобы предотвратить сверхподбор кривой. Управляйте листовым размером с установкой Minimum leaf size.
Совет
В галерее Model Type нажмите All Trees
![]() , чтобы попробовать каждую из nonoptimizable опций дерева регрессии и видеть, какие настройки производят лучшую модель с вашими данными. Выберите лучшую модель в панели Models и попытайтесь улучшить ту модель при помощи выбора признаков и изменяющий некоторые расширенные настройки.
, чтобы попробовать каждую из nonoptimizable опций дерева регрессии и видеть, какие настройки производят лучшую модель с вашими данными. Выберите лучшую модель в панели Models и попытайтесь улучшить ту модель при помощи выбора признаков и изменяющий некоторые расширенные настройки.
| Тип модели регрессии | Interpretability | Гибкость модели |
|---|---|---|
| Fine Tree | Легкий | Высоко Много маленьких листов для очень гибкой функции отклика (Минимальный листовой размер равняется 4.) |
| Medium Tree | Легкий | Средняя Листы среднего размера для менее гибкой функции отклика (Минимальный листовой размер равняется 12.) |
| Coarse Tree | Легкий | Низко Немного больших листов для крупной функции отклика (Минимальный листовой размер равняется 36.) |
Чтобы предсказать ответ дерева регрессии, следуйте за деревом от корня (начало) узел вниз к вершине. Вершина содержит значение ответа.
Деревья Statistics and Machine Learning Toolbox™ являются двоичным файлом. Каждый шаг в предсказании включает проверку значения одного переменного предиктора. Например, вот простое дерево регрессии
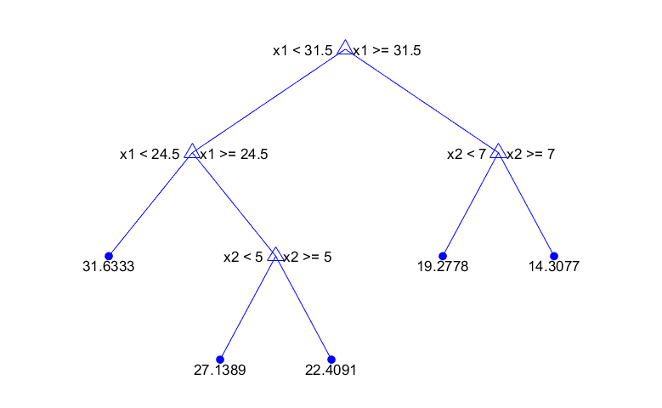
Это дерево предсказывает ответ на основе двух предикторов, x1 и x2. Чтобы сделать предсказание, запустите в главном узле. В каждом узле проверяйте значения предикторов, чтобы решить который ветвь следовать. Когда ветви достигают вершины, ответ установлен в значение, соответствующее тому узлу.
Можно визуализировать модель дерева регрессии путем экспорта модели из приложения и затем ввода:
view(trainedModel.RegressionTree,'Mode','graph')
Совет
Для примера рабочего процесса смотрите, Обучают Деревья Регрессии Используя Приложение Regression Learner.
Приложение Regression Learner использует fitrtree функция, чтобы обучить деревья регрессии. Можно установить эти опции:
Minimum leaf size
Укажите, что минимальное количество обучающих выборок раньше вычисляло ответ каждой вершины. Когда вы выращиваете дерево регрессии, рассматриваете его простоту и предсказательную силу. Чтобы изменить минимальный листовой размер, нажмите кнопки или введите положительное целочисленное значение в поле Minimum leaf size.
Прекрасное дерево со многими маленькими листами обычно очень точно на обучающих данных. Однако древовидная сила не показывает сопоставимую точность на независимом наборе тестов. Очень покрытое листвой дерево имеет тенденцию сверхсоответствовать, и его точность валидации часто намного ниже, чем его обучение (или перезамена) точность.
В отличие от этого крупное дерево с меньшим количеством больших листов не достигает высокой учебной точности. Но крупное дерево может быть более устойчивым в той своей учебной точности, может быть около того из представительного набора тестов.
Совет
Уменьшите Minimum leaf size, чтобы создать более гибкую модель.
Surrogate decision splits — Для недостающих данных только.
Задайте суррогатное использование для разделений решения. Если у вас есть данные с отсутствующими значениями, используйте суррогатные разделения, чтобы улучшить точность предсказаний.
Когда вы устанавливаете Surrogate decision splits на On, дерево регрессии находит самое большее 10 суррогатных разделений в каждом узле ветви. Чтобы изменить количество суррогатных разделений, нажмите кнопки или введите положительное целочисленное значение в поле Maximum surrogates per node.
Когда вы устанавливаете Surrogate decision splits на Find All, дерево регрессии находит все суррогатные разделения в каждом узле ветви. Find All установка может использовать продолжительное время и память.
В качестве альтернативы можно позволить приложению выбрать некоторые из этих опций модели автоматически при помощи гипероптимизации параметров управления. Смотрите Гипероптимизацию параметров управления в Приложении Regression Learner.
Можно обучить машины опорных векторов регрессии (SVMs) в Regression Learner. Линейные SVMs легко интерпретировать, но могут иметь низкую прогнозирующую точность. Нелинейные SVMs больше затрудняют, чтобы интерпретировать, но могут быть более точными.
Совет
В галерее Model Type нажмите All SVMs
![]() , чтобы попробовать каждую из nonoptimizable опций SVM и видеть, какие настройки производят лучшую модель с вашими данными. Выберите лучшую модель в панели Models и попытайтесь улучшить ту модель при помощи выбора признаков и изменяющий некоторые расширенные настройки.
, чтобы попробовать каждую из nonoptimizable опций SVM и видеть, какие настройки производят лучшую модель с вашими данными. Выберите лучшую модель в панели Models и попытайтесь улучшить ту модель при помощи выбора признаков и изменяющий некоторые расширенные настройки.
| Тип модели регрессии | Interpretability | Гибкость модели |
|---|---|---|
| Linear SVM | Легкий | Низко |
| Quadratic SVM | Трудно | Средняя |
| Cubic SVM | Трудно | Средняя |
| Fine Gaussian SVM | Трудно | Высоко Позволяет быстрые изменения функции отклика. Шкала ядра установлена в sqrt(P)/4, где P количество предикторов. |
| Medium Gaussian SVM | Трудно | Средняя Дает менее гибкую функцию отклика. Шкала ядра установлена в sqrt(P). |
| Coarse Gaussian SVM | Трудно | Низко Дает твердую функцию отклика. Шкала ядра установлена в sqrt(P)*4. |
Statistics and Machine Learning Toolbox реализует линейную нечувствительную к эпсилону регрессию SVM. Этот SVM игнорирует ошибки предсказания, которые меньше некоторого постоянного числа ε. support vectors является точками данных, которые имеют ошибки, больше, чем ε. Функция использование SVM, чтобы предсказать новые значения зависит только от векторов поддержки. Чтобы узнать больше о регрессии SVM, смотрите Регрессию Машины опорных векторов Понимания.
Совет
Для примера рабочего процесса смотрите, Обучают Деревья Регрессии Используя Приложение Regression Learner.
Regression Learner использует fitrsvm функция, чтобы обучить модели регрессии SVM.
Можно установить эти опции в приложении:
Kernel function
Функция ядра решает, что нелинейное преобразование применилось к данным, прежде чем SVM будет обучен. Можно выбрать из:
Gaussian или ядро Радиальной основной функции (RBF)
Linear ядро, самое легкое интерпретировать
Quadratic ядро
Cubic ядро
Box constraint mode
Ограничение поля управляет штрафом, наложенным на наблюдения с большими остаточными значениями. Большее ограничение поля дает более гибкую модель. Меньшее значение дает более твердую модель, менее чувствительную к сверхподбору кривой.
Когда Box constraint mode установлен в Auto, приложение использует эвристическую процедуру, чтобы выбрать ограничение поля.
Попытайтесь подстроить свою модель путем определения ограничения поля вручную. Установите Box constraint mode на Manual и задайте значение. Измените значение путем нажатия кнопок или ввода значения положительной скалярной величины в поле Manual box constraint. Приложение автоматически предварительно выбирает рыночную стоимость для вас. Попытайтесь увеличить или уменьшить это значение немного и видеть, улучшает ли это вашу модель.
Совет
Увеличьте ограничительное значение поля, чтобы создать более гибкую модель.
Epsilon mode
Ошибки предсказания, которые меньше, чем эпсилон (ε) значение, проигнорированы и обработаны как равные нулю. Меньшее значение эпсилона дает более гибкую модель.
Когда Epsilon mode установлен в Auto, приложение использует эвристическую процедуру, чтобы выбрать шкалу ядра.
Попытайтесь подстроить свою модель путем определения значения эпсилона вручную. Установите Epsilon mode на Manual и задайте значение. Измените значение путем нажатия кнопок или ввода значения положительной скалярной величины в поле Manual epsilon. Приложение автоматически предварительно выбирает рыночную стоимость для вас. Попытайтесь увеличить или уменьшить это значение немного и видеть, улучшает ли это вашу модель.
Совет
Уменьшите значение эпсилона, чтобы создать более гибкую модель.
Kernel scale mode
Шкала ядра управляет шкалой предикторов, на которых ядро значительно варьируется. Меньшая шкала ядра дает более гибкую модель.
Когда Kernel scale mode установлен в Auto, приложение использует эвристическую процедуру, чтобы выбрать шкалу ядра.
Попытайтесь подстроить свою модель путем определения шкалы ядра вручную. Установите Kernel scale mode на Manual и задайте значение. Измените значение путем нажатия кнопок или ввода значения положительной скалярной величины в поле Manual kernel scale. Приложение автоматически предварительно выбирает рыночную стоимость для вас. Попытайтесь увеличить или уменьшить это значение немного и видеть, улучшает ли это вашу модель.
Совет
Уменьшите значение шкалы ядра, чтобы создать более гибкую модель.
Standardize
Стандартизация предикторов преобразовывает их так, чтобы у них были среднее значение 0 и стандартное отклонение 1. Стандартизация удаляет зависимость от произвольных шкал в предикторах и обычно улучшает производительность.
В качестве альтернативы можно позволить приложению выбрать некоторые из этих опций модели автоматически при помощи гипероптимизации параметров управления. Смотрите Гипероптимизацию параметров управления в Приложении Regression Learner.
Можно обучить модели Gaussian process regression (GPR) в Regression Learner. Модели GPR часто очень точны, но могут затруднить, чтобы интерпретировать.
Совет
В галерее Model Type нажмите All GPR Models
![]() , чтобы попробовать каждую из nonoptimizable опций модели GPR и видеть, какие настройки производят лучшую модель с вашими данными. Выберите лучшую модель в панели Models и попытайтесь улучшить ту модель при помощи выбора признаков и изменяющий некоторые расширенные настройки.
, чтобы попробовать каждую из nonoptimizable опций модели GPR и видеть, какие настройки производят лучшую модель с вашими данными. Выберите лучшую модель в панели Models и попытайтесь улучшить ту модель при помощи выбора признаков и изменяющий некоторые расширенные настройки.
| Тип модели регрессии | Interpretability | Гибкость модели |
|---|---|---|
| Rational Quadratic | Трудно | Автоматический |
| Squared Exponential | Трудно | Автоматический |
| Matern 5/2 | Трудно | Автоматический |
| Exponential | Трудно | Автоматический |
В Гауссовой регрессии процесса ответ моделируется с помощью вероятностного распределения по пробелу функций. Гибкость предварительных установок в галерее Model Type автоматически выбрана, чтобы дать небольшую учебную ошибку и, одновременно, защита от сверхподбора кривой. Чтобы узнать больше о Гауссовой регрессии процесса, см. Гауссовы Модели Регрессии Процесса.
Совет
Для примера рабочего процесса смотрите, Обучают Деревья Регрессии Используя Приложение Regression Learner.
Regression Learner использует fitrgp функция, чтобы обучить модели GPR.
Можно установить эти опции в приложении:
Basis function
Основная функция задает форму предшествующей средней функции Гауссовой модели регрессии процесса. Можно выбрать из Zero, Constant, и Linear. Попытайтесь выбрать различную основную функцию и видеть, улучшает ли это вашу модель.
Kernel function
Функция ядра определяет корреляцию в ответе в зависимости от расстояния между значениями предиктора. Можно выбрать из Rational Quadratic, Squared Exponential, Matern 5/2, Matern 3/2, и Exponential.
Чтобы узнать больше о функциях ядра, смотрите Ядро (Ковариация) Опции Функции.
Use isotropic kernel
Если вы используете изотропное ядро, шкалы расстояний корреляции являются тем же самым для всех предикторов. С неизотропным ядром каждый переменный предиктор имеет свою собственную отдельную шкалу расстояний корреляции.
Используя неизотропное ядро может улучшить точность вашей модели, но может сделать модель медленной, чтобы соответствовать.
Чтобы узнать больше о неизотропных ядрах, смотрите Ядро (Ковариация) Опции Функции.
Kernel mode
Можно вручную задать начальные значения параметров ядра Kernel scale и Signal standard deviation. Стандартное отклонение сигнала является предшествующим стандартным отклонением значений отклика. По умолчанию приложение локально оптимизирует параметры ядра, начинающие с начальных значений. Чтобы использовать зафиксированные параметры ядра, снимите the Optimize numeric parameters флажок в расширенных настройках.
Когда Kernel scale mode установлен в Auto, приложение использует эвристическую процедуру, чтобы выбрать начальные параметры ядра.
Если вы устанавливаете Kernel scale mode на Manual, можно задать начальные значения. Нажмите кнопки или введите значение положительной скалярной величины в поле Kernel scale и поле Signal standard deviation.
Если вы снимаете флажок Use isotropic kernel, вы не можете установить начальные параметры ядра вручную.
Sigma mode
Можно задать вручную начальное значение стандартного отклонения шума наблюдения Sigma. По умолчанию приложение оптимизирует стандартное отклонение шума наблюдения, начинающее с начального значения. Чтобы использовать зафиксированные параметры ядра, снимите the Optimize numeric parameters флажок в расширенных настройках.
Когда Sigma mode установлен в Auto, приложение использует эвристическую процедуру, чтобы выбрать начальное стандартное отклонение шума наблюдения.
Если вы устанавливаете Sigma mode на Manual, можно задать начальные значения. Нажмите кнопки или введите значение положительной скалярной величины в поле Sigma.
Standardize
Стандартизация предикторов преобразовывает их так, чтобы у них были среднее значение 0 и стандартное отклонение 1. Стандартизация удаляет зависимость от произвольных шкал в предикторах и обычно улучшает производительность.
Optimize numeric parameters
При использовании этой опции приложение автоматически оптимизирует числовые параметры модели GPR. Оптимизированные параметры являются коэффициентами Basis function, параметры ядра Kernel scale и Signal standard deviation и стандартное отклонение шума наблюдения Sigma.
В качестве альтернативы можно позволить приложению выбрать некоторые из этих опций модели автоматически при помощи гипероптимизации параметров управления. Смотрите Гипероптимизацию параметров управления в Приложении Regression Learner.
Можно обучить ансамбли деревьев регрессии в Regression Learner. Объединение моделей ансамбля следует из многих слабых учеников в одну высококачественную модель ансамбля.
Совет
В галерее Model Type нажмите All Ensembles
![]() , чтобы попробовать каждую из nonoptimizable опций ансамбля и видеть, какие настройки производят лучшую модель с вашими данными. Выберите лучшую модель в панели Models и попытайтесь улучшить ту модель при помощи выбора признаков и изменяющий некоторые расширенные настройки.
, чтобы попробовать каждую из nonoptimizable опций ансамбля и видеть, какие настройки производят лучшую модель с вашими данными. Выберите лучшую модель в панели Models и попытайтесь улучшить ту модель при помощи выбора признаков и изменяющий некоторые расширенные настройки.
| Тип модели регрессии | Interpretability | Метод ансамбля | Гибкость модели |
|---|---|---|---|
| Boosted Trees | Трудно | Повышение наименьших квадратов ( | Носитель к высоко |
| Bagged Trees | Трудно | Загрузите агрегацию или укладывание в мешки с учениками дерева регрессии. | Высоко |
Совет
Для примера рабочего процесса смотрите, Обучают Деревья Регрессии Используя Приложение Regression Learner.
Regression Learner использует fitrensemble функция, чтобы обучить модели ансамбля. Можно установить эти опции:
Minimum leaf size
Укажите, что минимальное количество обучающих выборок раньше вычисляло ответ каждой вершины. Когда вы выращиваете дерево регрессии, рассматриваете его простоту и предсказательную силу. Чтобы изменить минимальный листовой размер, нажмите кнопки или введите положительное целочисленное значение в поле Minimum leaf size.
Прекрасное дерево со многими маленькими листами обычно очень точно на обучающих данных. Однако древовидная сила не показывает сопоставимую точность на независимом наборе тестов. Очень покрытое листвой дерево имеет тенденцию сверхсоответствовать, и его точность валидации часто намного ниже, чем его обучение (или перезамена) точность.
В отличие от этого крупное дерево с меньшим количеством больших листов не достигает высокой учебной точности. Но крупное дерево может быть более устойчивым в той своей учебной точности, может быть около того из представительного набора тестов.
Совет
Уменьшите Minimum leaf size, чтобы создать более гибкую модель.
Number of learners
Попытайтесь изменить количество учеников, чтобы видеть, можно ли улучшить модель. Многие ученики могут произвести высокую точность, но могут быть трудоемкими, чтобы соответствовать.
Совет
Увеличьте Number of learners, чтобы создать более гибкую модель.
Learning rate
Для повышенных деревьев задайте скорость обучения для уменьшения. Если вы устанавливаете скорость обучения на меньше чем 1, ансамбль требует большего количества итераций изучения, но часто достигает лучшей точности. 0.1 популярный начальный выбор.
В качестве альтернативы можно позволить приложению выбрать некоторые из этих опций модели автоматически при помощи гипероптимизации параметров управления. Смотрите Гипероптимизацию параметров управления в Приложении Regression Learner.
Модели нейронной сети обычно имеют хорошую прогнозирующую точность; однако, их не легко интерпретировать.
Гибкость модели увеличивается с размером и количеством полносвязных слоев в нейронной сети.
Совет
В галерее Model Type нажмите All Neural Networks
![]() , чтобы попробовать каждую из предварительно установленных опций нейронной сети и видеть, какие настройки производят лучшую модель с вашими данными. Выберите лучшую модель в панели Models и попытайтесь улучшить ту модель при помощи выбора признаков и изменяющий некоторые расширенные настройки.
, чтобы попробовать каждую из предварительно установленных опций нейронной сети и видеть, какие настройки производят лучшую модель с вашими данными. Выберите лучшую модель в панели Models и попытайтесь улучшить ту модель при помощи выбора признаков и изменяющий некоторые расширенные настройки.
| Тип модели регрессии | Interpretability | Гибкость модели |
|---|---|---|
| Narrow Neural Network | Трудно | Носитель — увеличивается с установкой First layer size |
| Medium Neural Network | Трудно | Носитель — увеличивается с установкой First layer size |
| Wide Neural Network | Трудно | Носитель — увеличивается с установкой First layer size |
| Bilayered Neural Network | Трудно | Высоко — увеличивается с настройками First layer size и Second layer size |
| Trilayered Neural Network | Трудно | Высоко — увеличивается с First layer size, Second layer size и настройками Third layer size |
Каждой моделью является feedforward, полностью соединенная нейронная сеть для регрессии. Первый полносвязный слой нейронной сети имеет связь от сетевого входа (данные о предикторе), и каждый последующий слой имеет связь от предыдущего слоя. Каждый полносвязный слой умножает вход на матрицу веса и затем добавляет вектор смещения. Функция активации следует за каждым полносвязным слоем, исключая последнее. Итоговый полносвязный слой производит выход сети, а именно, предсказанные значения отклика. Для получения дополнительной информации смотрите Структуру Нейронной сети.
Для примера смотрите Обучают Нейронные сети Регрессии Используя Приложение Regression Learner.
Regression Learner использует fitrnet функция, чтобы обучить модели нейронной сети. Можно установить эти опции:
Number of fully connected layers — Задайте количество полносвязных слоев в нейронной сети, исключая итоговый полносвязный слой для регрессии. Можно выбрать максимум трех полносвязных слоев.
First layer size, Second layer size и Third layer size — Задайте размер каждого полносвязного слоя, исключая итоговый полносвязный слой. Если вы принимаете решение создать нейронную сеть с несколькими полносвязными слоями, рассмотрите слои определения с уменьшающимися размерами.
Activation — Задайте функцию активации для всех полносвязных слоев, исключая итоговый полносвязный слой. Выберите из следующих функций активации: ReLUtanh'none', и Sigmoid.
Iteration limit — Задайте максимальное количество учебных итераций.
Regularization strength (Lambda) — Задайте гребень (L2) термин штрафа регуляризации.
Standardize data — Задайте, стандартизировать ли числовые предикторы. Если предикторы имеют широко различные шкалы, стандартизация может улучшить подгонку. Стандартизация данных настоятельно рекомендована.
В качестве альтернативы можно позволить приложению выбрать некоторые из этих опций модели автоматически при помощи гипероптимизации параметров управления. Смотрите Гипероптимизацию параметров управления в Приложении Regression Learner.
