Потеря наивной модели классификации Бейеса для пошагового обучения на пакете данных
loss возвращает потерю классификации сконфигурированной наивной модели классификации Бейеса для модели пошагового обучения (incrementalClassificationNaiveBayes объект.
Чтобы измерить производительность модели на потоке данных и сохранить результаты в выходной модели, вызвать updateMetrics или updateMetricsAndFit.
Уровень инкрементной модели при потоковой передаче данных измерен тремя способами:
Совокупные метрики измеряют уровень начиная с запуска пошагового обучения.
Метрики окна измеряют уровень на заданном окне наблюдений. Метрики обновляются каждый раз процессы модели заданное окно.
loss функция измеряет уровень на заданном пакете данных только.
Загрузите набор данных деятельности человека. Случайным образом переставьте данные.
load humanactivity n = numel(actid); rng(1); % For reproducibility idx = randsample(n,n); X = feat(idx,:); Y = actid(idx);
Для получения дополнительной информации на наборе данных, введите Description в командной строке.
Создайте наивную модель классификации Бейеса для пошагового обучения; задайте имена классов и метрический размер окна 1 000 наблюдений. Сконфигурируйте его для loss путем подбора кривой ему к первым 10 наблюдениям.
Mdl = incrementalClassificationNaiveBayes('ClassNames',unique(Y),'MetricsWindowSize',1000); initobs = 10; Mdl = fit(Mdl,X(1:initobs,:),Y(1:initobs)); canComputeLoss = (size(Mdl.DistributionParameters,2) == Mdl.NumPredictors) +... (size(Mdl.DistributionParameters,1) > 1) > 1
canComputeLoss = logical
1
Mdl incrementalClassificationLinear модель. Все его свойства только для чтения.
Симулируйте поток данных и выполните следующие действия с каждым входящим фрагментом 50 наблюдений:
Вызовите updateMetrics измерять совокупный уровень и эффективность в окне наблюдений. Перезапишите предыдущую инкрементную модель с новой, чтобы отследить показатели производительности.
Вызовите loss измерять производительность модели на входящем фрагменте.
Вызовите fit подбирать модель к входящему фрагменту. Перезапишите предыдущую инкрементную модель с новой, адаптированной к входящему наблюдению.
Сохраните все показатели производительности, чтобы видеть, как они развиваются во время пошагового обучения.
% Preallocation numObsPerChunk = 500; nchunk = floor((n - initobs)/numObsPerChunk); mc = array2table(zeros(nchunk,3),'VariableNames',["Cumulative" "Window" "Loss"]); % Incremental learning for j = 1:nchunk ibegin = min(n,numObsPerChunk*(j-1) + 1 + initobs); iend = min(n,numObsPerChunk*j + initobs); idx = ibegin:iend; Mdl = updateMetrics(Mdl,X(idx,:),Y(idx)); mc{j,["Cumulative" "Window"]} = Mdl.Metrics{"MinimalCost",:}; mc{j,"Loss"} = loss(Mdl,X(idx,:),Y(idx)); Mdl = fit(Mdl,X(idx,:),Y(idx)); end
Mdl incrementalClassificationNaiveBayes объект модели, обученный на всех данных в потоке. Во время пошагового обучения и после того, как модель подогревается, updateMetrics проверяет эффективность модели на входящем наблюдении, затем и fit функция подбирает модель к тому наблюдению. loss агностик метрического периода прогрева, таким образом, он измеряет минимальную стоимость для всех итераций.
Чтобы видеть, как показатели производительности, развитые во время обучения, постройте их.
figure; plot(mc.Variables); xlim([0 nchunk]); ylim([0 0.1]) ylabel('Minimal Cost') xline(Mdl.MetricsWarmupPeriod/numObsPerChunk + 1,'r-.'); legend(mc.Properties.VariableNames) xlabel('Iteration')

В метрический период прогрева (область слева от красной линии), желтая линия представляет минимальную стоимость на каждом входящем фрагменте данных. После метрического периода прогрева, Mdl отслеживает совокупные метрики и метрики окна. Совокупные и пакетные потери сходятся как fit функция подбирает инкрементную модель к входящим данным.
Подбирайте наивную модель классификации Бейеса для пошагового обучения к потоковой передаче данных и вычислите потерю перекрестной энтропии мультикласса на входящих фрагментах данных.
Загрузите набор данных деятельности человека. Случайным образом переставьте данные.
load humanactivity n = numel(actid); rng(1); % For reproducibility idx = randsample(n,n); X = feat(idx,:); Y = actid(idx);
Для получения дополнительной информации на наборе данных, введите Description в командной строке.
Создайте наивную модель классификации Бейеса для пошагового обучения. Сконфигурируйте модель можно следующим образом:
Задайте имена классов
Задайте метрический период прогрева 1 000 наблюдений.
Задайте метрический размер окна 2 000 наблюдений.
Отследите потерю перекрестной энтропии мультикласса, чтобы измерить уровень модели. Создайте анонимную функцию, которая измеряет потерю перекрестной энтропии мультикласса каждого нового наблюдения, включайте допуск к числовой устойчивости. Создайте массив структур, содержащий имя CrossEntropy и его соответствующая функция.
Сконфигурируйте модель, чтобы вычислить потерю классификации, подбирая модель к первым 10 наблюдениям.
tolerance = 1e-10; crossentropy = @(z,zfit,w,cost)-log(max(zfit(z),tolerance)); ce = struct("CrossEntropy",crossentropy); Mdl = incrementalClassificationNaiveBayes('ClassNames',unique(Y),'MetricsWarmupPeriod',1000,... 'MetricsWindowSize',2000,'Metrics',ce); initobs = 10; Mdl = fit(Mdl,X(1:initobs,:),Y(1:initobs));
Mdl incrementalClassificationNaiveBayes объект модели сконфигурирован для пошагового обучения.
Выполните пошаговое обучение. В каждой итерации:
Симулируйте поток данных путем обработки фрагмента 100 наблюдений.
Вызовите updateMetrics вычислить совокупный и метрики окна на входящем фрагменте данных. Перезапишите предыдущую инкрементную модель с новой, адаптированной, чтобы перезаписать предыдущие метрики.
Вызовите loss вычислить перекрестную энтропию на входящем фрагменте данных. Принимая во внимание, что совокупные метрики и метрики окна требуют, чтобы пользовательские потери возвратили потерю для каждого наблюдения, loss требует потери на целом фрагменте. Вычислите среднее значение потерь во фрагменте.
Вызовите fit подбирать инкрементную модель к входящему фрагменту данных.
Сохраните совокупное, окно, и разделите метрики на блоки, чтобы видеть, как они развиваются во время пошагового обучения.
% Preallocation numObsPerChunk = 100; nchunk = floor((n - initobs)/numObsPerChunk); tanloss = array2table(zeros(nchunk,3),'VariableNames',["Cumulative" "Window" "Chunk"]); % Incremental fitting for j = 1:nchunk ibegin = min(n,numObsPerChunk*(j-1) + 1 + initobs); iend = min(n,numObsPerChunk*j + initobs); idx = ibegin:iend; Mdl = updateMetrics(Mdl,X(idx,:),Y(idx)); tanloss{j,1:2} = Mdl.Metrics{"CrossEntropy",:}; tanloss{j,3} = loss(Mdl,X(idx,:),Y(idx),'LossFun',@(z,zfit,w,cost)mean(crossentropy(z,zfit,w,cost))); Mdl = fit(Mdl,X(idx,:),Y(idx)); end
IncrementalMdl incrementalClassificationNaiveBayes объект модели, обученный на всех данных в потоке. Во время пошагового обучения и после того, как модель подогревается, updateMetrics проверяет эффективность модели на входящем наблюдении и fit функция подбирает модель к тому наблюдению.
Постройте показатели производительности, чтобы видеть, как они развились во время пошагового обучения.
figure; h = plot(tanloss.Variables); ylabel('Cross Entropy') xline(Mdl.MetricsWarmupPeriod/numObsPerChunk,'r-.'); xlabel('Iteration') legend(h,tanloss.Properties.VariableNames)

График предлагает следующее:
updateMetrics вычисляет показатели производительности после метрического периода прогрева только.
updateMetrics вычисляет совокупные метрики во время каждой итерации.
updateMetrics вычисляет метрики окна после обработки 100 наблюдений
Поскольку Mdl был сконфигурирован, чтобы предсказать наблюдения с начала пошагового обучения, loss может вычислить перекрестную энтропию на каждом входящем фрагменте данных.
Функции Classification loss измеряют прогнозирующую погрешность моделей классификации. Когда вы сравниваете тот же тип потери среди многих моделей, более низкая потеря указывает на лучшую прогнозную модель.
Рассмотрите следующий сценарий.
L является средневзвешенной потерей классификации.
n является объемом выборки.
Для бинарной классификации:
yj является наблюдаемой меткой класса. Программные коды это как –1 или 1, указывая на отрицательный или положительный класс (или первый или второй класс в ClassNames свойство), соответственно.
f (Xj) является классификационной оценкой положительного класса для наблюдения (строка) j данных о предикторе X.
mj = yj f (Xj) является классификационной оценкой для классификации наблюдения j в класс, соответствующий yj. Положительные значения mj указывают на правильную классификацию и не способствуют очень средней потере. Отрицательные величины mj указывают на неправильную классификацию и значительно способствуют средней потере.
Для алгоритмов, которые поддерживают классификацию мультиклассов (то есть, K ≥ 3):
yj* вектор из K – 1 нуль, с 1 в положении, соответствующем истинному, наблюдаемому классу yj. Например, если истинный класс второго наблюдения является третьим классом и K = 4, то y 2* = [0 0 1 0] ′. Порядок классов соответствует порядку в ClassNames свойство входной модели.
f (Xj) является длиной вектор K из музыки класса к наблюдению j данных о предикторе X. Порядок баллов соответствует порядку классов в ClassNames свойство входной модели.
mj = yj*′f (Xj). Поэтому mj является скалярной классификационной оценкой, которую модель предсказывает для истинного, наблюдаемого класса.
Весом для наблюдения j является wj. Программное обеспечение нормирует веса наблюдения так, чтобы они суммировали к соответствующей предшествующей вероятности класса. Программное обеспечение также нормирует априорные вероятности, таким образом, они суммируют к 1. Поэтому
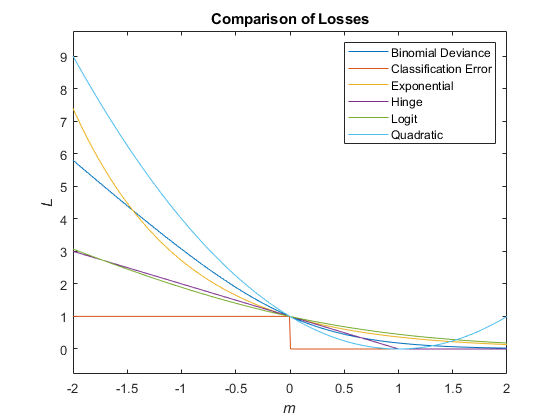
Учитывая этот сценарий, следующая таблица описывает поддерживаемые функции потерь, которые можно задать при помощи 'LossFun' аргумент пары "имя-значение".
| Функция потерь | Значение LossFun | Уравнение |
|---|---|---|
| Биномиальное отклонение | 'binodeviance' | |
| Неправильно классифицированный уровень в десятичном числе | 'classiferror' | метка класса, соответствующая классу с максимальным счетом. I {·} является функцией индикатора. |
| Потеря перекрестной энтропии | 'crossentropy' |
Взвешенная потеря перекрестной энтропии где веса нормированы, чтобы суммировать к n вместо 1. |
| Экспоненциальная потеря | 'exponential' | |
| Потеря стержня | 'hinge' | |
| Потеря логита | 'logit' | |
| Минимальный ожидал стоимость misclassification | 'mincost' |
Программное обеспечение вычисляет взвешенную минимальную ожидаемую стоимость классификации с помощью этой процедуры для наблюдений j = 1..., n.
Взвешенное среднее минимального ожидало, что потеря стоимости misclassification Если вы используете матрицу стоимости по умолчанию (чье значение элемента 0 для правильной классификации и 1 для неправильной классификации), то |
| Квадратичная потеря | 'quadratic' |
Этот рисунок сравнивает функции потерь (кроме 'crossentropy' и 'mincost') по счету m для одного наблюдения. Некоторые функции нормированы, чтобы пройти через точку (0,1).