Подбирать многомерную модель линейной регрессии использование mvregress, необходимо настроить матрицу ответа и матрицы проекта конкретным способом. Учитывая правильно отформатированные входные параметры, mvregress может решить множество многомерных проблем регрессии.
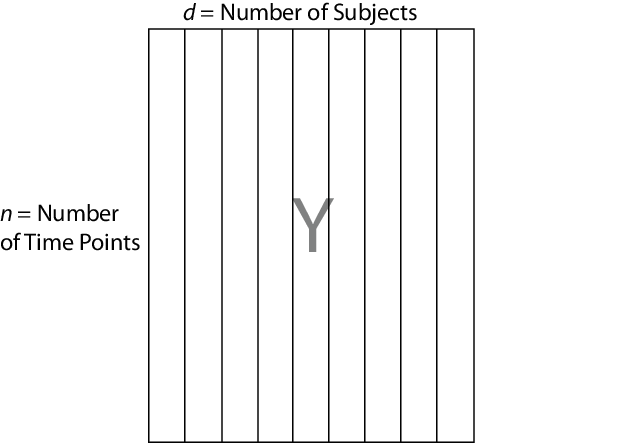
mvregress ожидает, что наблюдения n за потенциально коррелированым d - размерные ответы будут в n-by-d матрица, названная Y, например. Таким образом, настройте свои ответы так, чтобы структура зависимости была между наблюдениями в той же строке. Если вы задаете Y как вектор из длины n (или строка или вектор-столбец), затем mvregress принимает, что d = 1, и обрабатывает элементы как n независимые наблюдения. Это не моделирует вектор как одну реализацию коррелированого ряда (такого как временные ряды).
Чтобы проиллюстрировать, как настроить матрицу ответа, предположите, что ваши многомерные ответы являются повторенными измерениями, сделанными на предметах в нескольких моментах времени, как в следующем рисунке.
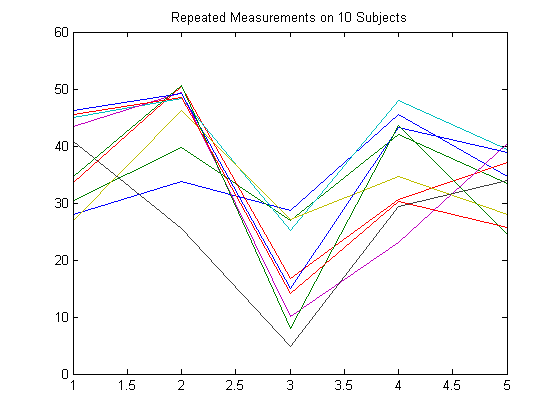
Предположим, что наблюдения в предмете коррелируются.
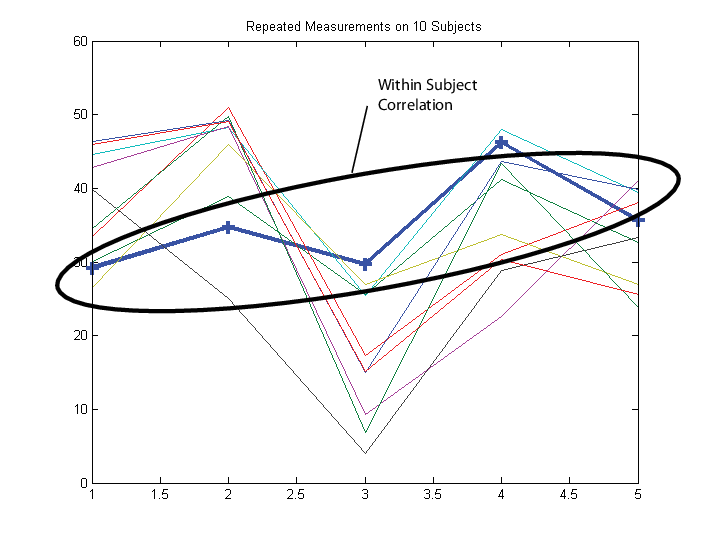
В этом случае настройте матрицу ответа Y таким образом, что каждая строка соответствует предмету, и каждый столбец соответствует моменту времени.

С другой стороны предположите, что наблюдения, сделанные на предметах одновременно, коррелируются (параллельная корреляция).
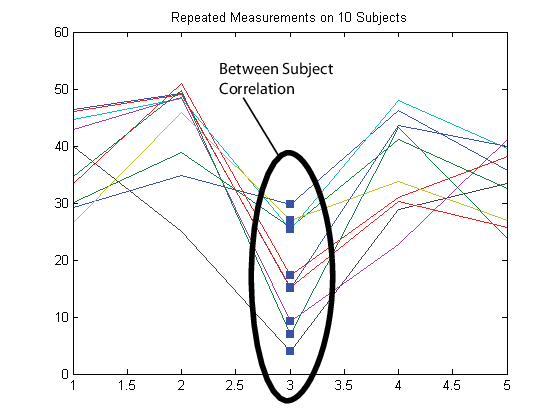
В этом случае настройте матрицу ответа Y таким образом, что каждая строка соответствует моменту времени, и каждый столбец соответствует предмету.
В многомерной модели линейной регрессии каждом d - размерный ответ имеет соответствующую матрицу проекта. В зависимости от модели проекта матричная сила состоять из внешних переменных предикторов, фиктивных переменных, изолировала ответы или комбинацию этих и других ковариационных терминов.
Если d> 1 и все размерности d имеет ту же матрицу проекта, то задает один n-by-p матрица проекта, где p является количеством переменных предикторов. Чтобы определить точку пересечения для каждой размерности, добавьте столбец из единиц к матрице проекта. В этом случае, mvregress применяет матрицу проекта ко всем размерностям d.
Если d> 1 и все размерности d не имеет той же матрицы проекта, то задайте матрицы проекта с помощью массива ячеек длины-n d-by-K массивы, названные X, например. K является общим количеством коэффициентов регрессии в модели. Обратите внимание на то, что строки массивов в X соответствуйте столбцам матрицы ответа, Y.
Если все наблюдения n имеют ту же матрицу проекта, можно задать массив ячеек, содержащий один d-by-K матрица проекта. В этом случае, mvregress применяет матрицу проекта ко всем наблюдениям n. Например, эта ситуация может возникнуть, если предикторы являются функциями времени, и все наблюдения были измерены одновременно точки.
В особом случае, что d = 1, можно задать один n-by-K матрица проекта (не в массиве ячеек). Однако необходимо рассмотреть использование fitlm подбирать модели регрессии к одномерным, непрерывным ответам.
Следующие разделы иллюстрируют, как настроить некоторые общие многомерные проблемы регрессии для оценки с помощью mvregress.
Многомерная общая линейная модель имеет форму
В расширенной форме,
Таким образом, каждый d - размерный ответ имеет точку пересечения и переменные предикторы p, и каждая размерность имеет свой собственный набор коэффициентов регрессии. В этой форме решением методом наименьших квадратов является B = X\Y. Оценить эту модель с помощью mvregress, используйте n-by-d матрица ответов, как выше.
Если все размерности d имеют ту же матрицу проекта, используйте n (p +1) матрица проекта, как выше. Добавление столбца из единиц к переменным предикторам p вычисляет точку пересечения для каждой размерности.
Если все размерности d не имеют той же матрицы проекта, переформатируйте n (p + 1) матрица проекта в массив ячеек длины-n d-by-K матрицы. Здесь, K = (p + 1) d для точки пересечения и наклоны для каждой размерности.
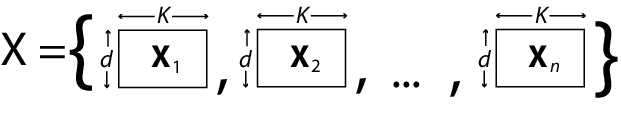
Например, предположите n = 4, d = 3, и p = 2 (два термина предиктора в дополнение к точке пересечения). Этот рисунок показывает, как отформатировать i th элемент в массиве ячеек.
Если вы предпочитаете, можно изменить K-by-1 вектор из коэффициентов назад в (p + 1)-by-d матрица после оценки.
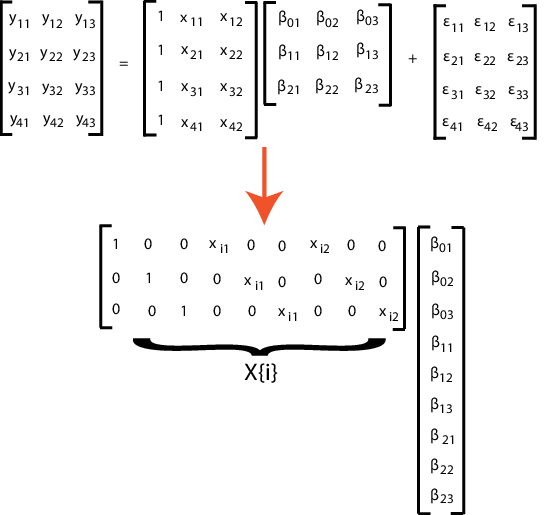
Чтобы поместить ограничения на параметры модели, настройте матрицу проекта соответственно. Например, предположите, что три измерения в предыдущем примере имеют общий наклон. Таким образом, и В этом случае каждая матрица проекта 3 на 5 как показано в следующем рисунке.
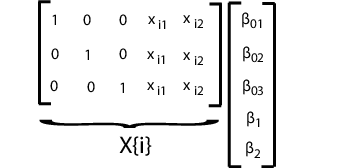
В продольном анализе вы можете измерить ответы на предметах n в моментах времени d с корреляцией между наблюдениями, сделанными на том же предмете. Например, предположите, что вы измеряете ответы yij во времена tij, i = 1..., n и j = 1..., d. Кроме того, предположите, что каждый предмет находится в одной из двух групп (таких как штекер или розетка), задан переменной Gi индикатора. Вы могли смоделировать yij в зависимости от Gi и tij, со специфичными для группы точками пересечения и наклонами, можно следующим образом:
где
Большинство продольных моделей включает время как явный предиктор.
Подбирать эту модель с помощью mvregress, расположите ответы в n-by-d матрица, где n является количеством предметов, и d является количеством моментов времени. Задайте матрицы проекта в n - массив ячеек длины d-by-K матрицы, где здесь K = 4 для этих четырех коэффициентов регрессии.
Например, предположите d = 5 (пять наблюдений на предмет). i th проект матричный и соответствующий вектор параметра для заданной модели показывают в следующем рисунке.
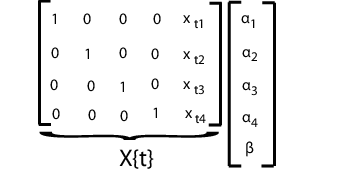
В анализе панели вы можете измерить ответы и коварианты на предметах d (таких как индивидуумы или страны) в моментах времени n. Например, предположите, что вы измеряете ответы ytj и коварианты xtj на предметах j = 1..., d во времена t = 1..., n. Фиксированная модель панели эффектов, с подчинено-специфичными фиксированными эффектами и параллельной корреляцией может быть похожей:
где
В отличие от продольных моделей, аналитическая модель панели обычно включает коварианты, измеренные в каждый момент времени, вместо того, чтобы использовать время в качестве явного предиктора.
Подбирать эту модель с помощью mvregress, расположите ответы в n-by-d матрица, такая, что каждый столбец соответствует предмету. Задайте матрицы проекта в n - массив ячеек длины d-by-K матрицы, где здесь K = d + 1 для точек пересечения d и наклонного термина.
Например, предположите d = 4 (четыре предмета). t th проект матричный и соответствующий вектор параметра показывают в следующем рисунке.
В на вид несвязанной регрессии (SUR), вы модель d разделяют регрессии, каждого с ее собственной точкой пересечения и наклоном, но ковариационной матрицей отклонения распространенной ошибки. Например, предположите, что вы измеряете ответы yij и коварианты xij для моделей j регрессии = 1..., d, с i = 1..., наблюдения n, чтобы соответствовать каждой регрессии. Модель SUR может быть похожей:
где
Эта модель очень похожа на многомерную общую линейную модель, за исключением того, что это имеет различные коварианты для каждой размерности.
Подбирать эту модель с помощью mvregress, расположите ответы в n-by-d матрица, такая, что каждый столбец имеет данные для j th модель регрессии. Задайте матрицы проекта в n - массив ячеек длины d-by-K матрицы, где здесь K = 2d для точек пересечения d и d клонится.
Например, предположите d = 3 (три регрессии). i th проект матричный и соответствующий вектор параметра показывают в следующем рисунке.
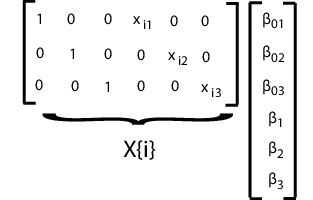
VAR (p), векторная авторегрессивная модель описывает d - размерные ответы временных рядов как линейная функция p, изолировал d - размерные ответы с предыдущих раз. Например, предположите, что вы измеряете ответы ytj для временных рядов j = 1..., d во времена t = 1..., n. Модель VAR (p) может быть похожей:
где
При оценке векторных авторегрессивных моделей обычно необходимо использовать первые наблюдения p, чтобы инициировать модель или обеспечить некоторые другие преддемонстрационные значения отклика.
Подбирать эту модель с помощью mvregress, расположите ответы в n-by-d матрица, такая, что каждый столбец соответствует временным рядам. Задайте матрицы проекта в n - массив ячеек длины d-by-K матрицы, где здесь K = d + фунт2.
Например, предположите d = 2 (два временных рядов) и p = 1 (одна задержка). t th проект матричный и соответствующий вектор параметра показывают в следующем рисунке.

В качестве альтернативы Econometrics Toolbox™ имеет функции для подбора кривой и прогнозирования моделей VAR (p), включая опцию, чтобы задать внешние переменные предикторы.
