В этом примере показано, как создать и сравнить различные деревья классификации с помощью Classification Learner, и экспорт обучил модели к рабочей области делать предсказания для новых данных.
Можно обучить деревья классификации предсказывать ответы на данные. Чтобы предсказать ответ, следуйте за решениями в дереве от корня (начало) узел вниз к вершине. Вершина содержит ответ.
Деревья Statistics and Machine Learning Toolbox™ являются двоичным файлом. Каждый шаг в предсказании включает проверку значения одного предиктора (переменная). Например, вот простое дерево классификации:
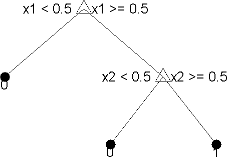
Это дерево предсказывает классификации на основе двух предикторов, x1 и x2. Чтобы предсказать, запустите в главном узле. При каждом решении проверяйте значения предикторов, чтобы решить который ветвь следовать. Когда ветви достигают вершины, данные классифицируются любой как тип 0 или 1.
В MATLAB®, загрузите fisheriris набор данных и составляет таблицу предикторов измерения (или функции) использование переменных из набора данных, чтобы использовать для классификации.
fishertable = readtable('fisheriris.csv');На вкладке Apps, в группе Machine Learning and Deep Learning, нажимают Classification Learner.
На вкладке Classification Learner, в разделе File, нажимают New Session > From Workspace.

В диалоговом окне New Session from Workspace выберите таблицу fishertable из списка Data Set Variable (при необходимости).
Заметьте, что приложение выбрало ответ и переменные предикторы на основе их типа данных. Лепесток и длина чашелистика и ширина являются предикторами, и разновидность является ответом, который вы хотите классифицировать. В данном примере не изменяйте выборы.
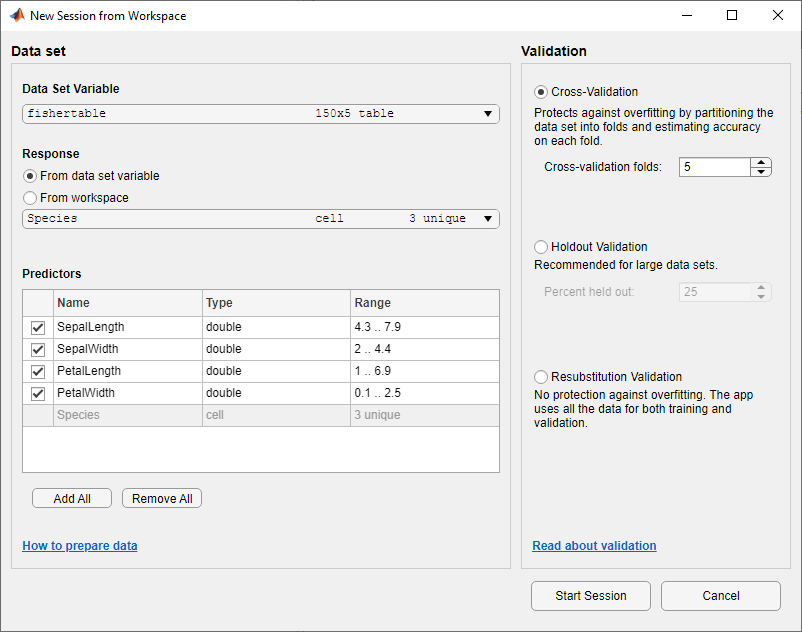
Чтобы принять схему валидации по умолчанию и продолжиться, нажмите Start Session. Опция валидации по умолчанию является перекрестной проверкой, чтобы защитить от сверхподбора кривой.
Classification Learner создает график рассеивания данных.
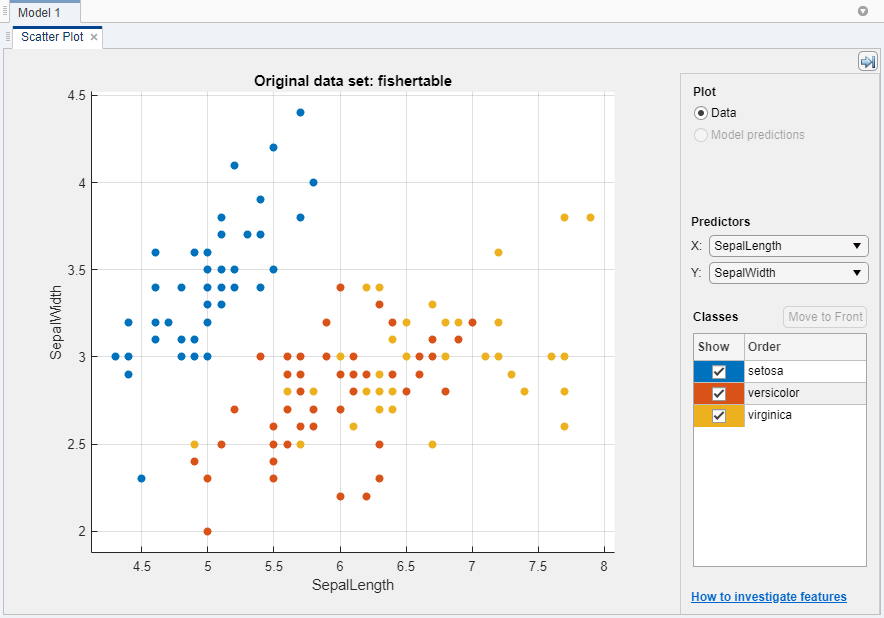
Используйте график рассеивания, чтобы заняться расследованиями, какие переменные полезны для предсказания ответа. Выберите различные варианты на X и списках Y под Predictors, чтобы визуализировать распределение разновидностей и измерения. Наблюдайте, какие переменные разделяют цвета разновидностей наиболее ясно.
Заметьте что setosa разновидность (синие точки) легко разделить от других двух разновидностей со всеми четырьмя предикторами. versicolor и virginica разновидности намного ближе вместе во всех измерениях предиктора и перекрываются особенно, когда вы строите длину чашелистика и ширину. setosa легче предсказать, чем другие две разновидности.
Чтобы создать модель дерева классификации, на вкладке Classification Learner, в разделе Model Type, кликают по стрелке вниз, чтобы расширить галерею и нажать Coarse Tree. Затем нажмите Train.
Приложение создает простое дерево классификации и строит результаты.
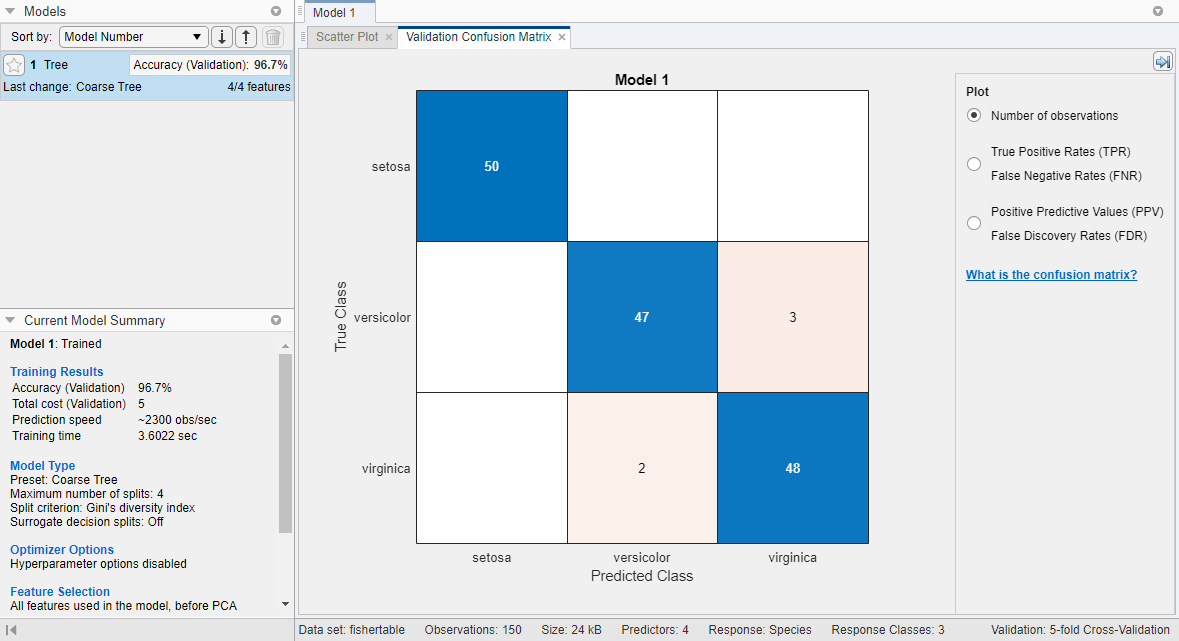
Наблюдайте модель Coarse Tree в панели Models. Проверяйте счет проверки допустимости модели в поле Accuracy (Validation). Модель выполнила хорошо.
Примечание
С валидацией в результатах существует некоторая случайность, таким образом, ваши результаты счета проверки допустимости модели могут варьироваться от показанных.
Щелкните график Scatter Plot переходят, чтобы исследовать график рассеивания. X указывает на неправильно классифицированные точки. Синие точки (setosa разновидности), все правильно классифицируются, но некоторые из других двух разновидностей неправильно классифицируются. Под Plot, переключателем между Data и опциями Model Predictions. Наблюдайте цвет неправильного (X) точки. В качестве альтернативы, в то время как графический вывод предсказаний модели, чтобы просмотреть только неправильные точки, снимает флажок Correct.
Обучите различную модель выдерживать сравнение. Нажмите Medium Tree, и затем нажмите Train.
Когда вы нажимаете Train, отображения приложения новая модель в панели Models.
Наблюдайте модель Medium Tree в панели Models. Счет проверки допустимости модели не лучше, чем крупный древовидный счет. Приложение обрисовывает в общих чертах в поле счет Accuracy (Validation) лучшей модели. Кликните по каждой модели в панели Models, чтобы просмотреть и сравнить результаты.
Исследуйте график рассеивания на модель Medium Tree. На вкладке Classification Learner, в разделе Plots, кликают по стреле, чтобы открыть галерею, и затем нажать Scatter в группе Validation Results. Среднее дерево классифицирует столько же точек правильно сколько предыдущее крупное дерево. Вы не хотите сверхсоответствовать, и крупное дерево выполняет хорошо, так основывайте все дальнейшие модели на крупном дереве.
Выберите Coarse Tree в панели Models. Чтобы попытаться улучшить модель, попробуйте включая различные функции в модели. Смотрите, можно ли улучшить модель путем удаления функций с низкой предсказательной силой.
На вкладке Classification Learner, в разделе Features, нажимают Feature Selection.
В диалоговом окне Feature Selection снимите флажки для PetalLength и PetalWidth, чтобы исключить их из предикторов. Нажмите OK. Новая черновая модель появляется в панели Models с вашими новыми настройками 2/4 функции, на основе крупного дерева.
Нажмите Train, чтобы обучить новую древовидную модель с помощью новых опций предиктора.
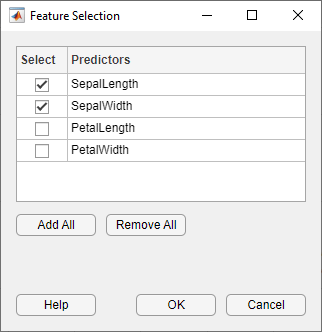
Наблюдайте третью модель в панели Models. Это - также модель Coarse Tree, обученное использование только 2 из 4 предикторов. Отображения приложения, сколько предикторов исключено. Чтобы проверять, какие предикторы включены, щелкните, модель в Models разделяют на области и наблюдают флажки в диалоговом окне Feature Selection. Модель только с измерениями чашелистика имеет намного более низкий счет точности, чем модель только для лепестков.
Обучите другую модель только включая лепестковые измерения. Измените выборы в диалоговом окне Feature Selection и нажмите OK. Затем нажмите Train.
Модель, обученная с помощью только лепестковые измерения, выполняет сравнительно к моделям, содержащим все предикторы. Модели не предсказывают лучшего использования всех измерений только по сравнению с лепестковыми измерениями. Если сбор данных является дорогим или трудным, вы можете предпочесть модель, которая выполняет удовлетворительно без некоторых предикторов.
Повторитесь, чтобы обучить еще две модели только включая измерения ширины и затем измерения длины. Нет большого различия в счете между несколькими из моделей.
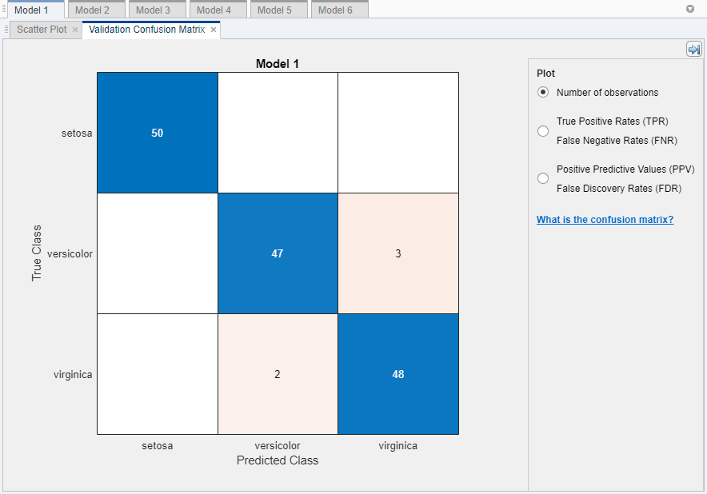
Выберите лучшую модель среди тех из подобных баллов путем исследования эффективности в каждом классе. Выберите крупное дерево, которое включает все предикторы. Чтобы смотреть точность предсказаний в каждом классе, на вкладке Classification Learner, в разделе Plots, кликают по стреле, чтобы открыть галерею, и затем нажать Confusion Matrix (Validation) в группе Validation Results. Используйте этот график изучить, как в настоящее время выбранный классификатор выполнил в каждом классе. Просмотрите матрицу истинного класса и предсказанных результатов класса.
Ищите области, где классификатор выполнил плохо путем исследования ячеек от диагонали, которые отображают высокие числа и являются красными. В этих эритроцитах не соответствуют истинный класс и предсказанный класс. Точки данных неправильно классифицируются.
Примечание
С валидацией в результатах существует некоторая случайность, таким образом, ваши матричные результаты беспорядка могут варьироваться от показанных.
В этом рисунке исследуйте третью ячейку в средней строке. В этой ячейке истинным классом является versicolor, но модель неправильно классифицировала точки как virginica. Для этой модели ячейка показывает 3 неправильно классифицированных (ваши результаты могут варьироваться). Чтобы просмотреть проценты вместо количеств наблюдений, выберите опцию True Positive Rates под средствами управления Plot.
Можно использовать эту информацию, чтобы помочь вам выбрать лучшую модель для своей цели. Если ложные положительные стороны в этом классе очень важны для вашей проблемы классификации, то выбирают лучшую модель при предсказании этого класса. Если ложные положительные стороны в этом классе не очень важны, и модели с меньшим количеством предикторов добиваются большего успеха в других классах, то выбирают модель к компромиссу некоторая общая точность, чтобы исключить некоторые предикторы и сделать будущий сбор данных легче.
Сравните матрицу беспорядка для каждой модели в панели Models. Установите диалоговый флажок Feature Selection, чтобы видеть, какие предикторы включены в каждую модель.
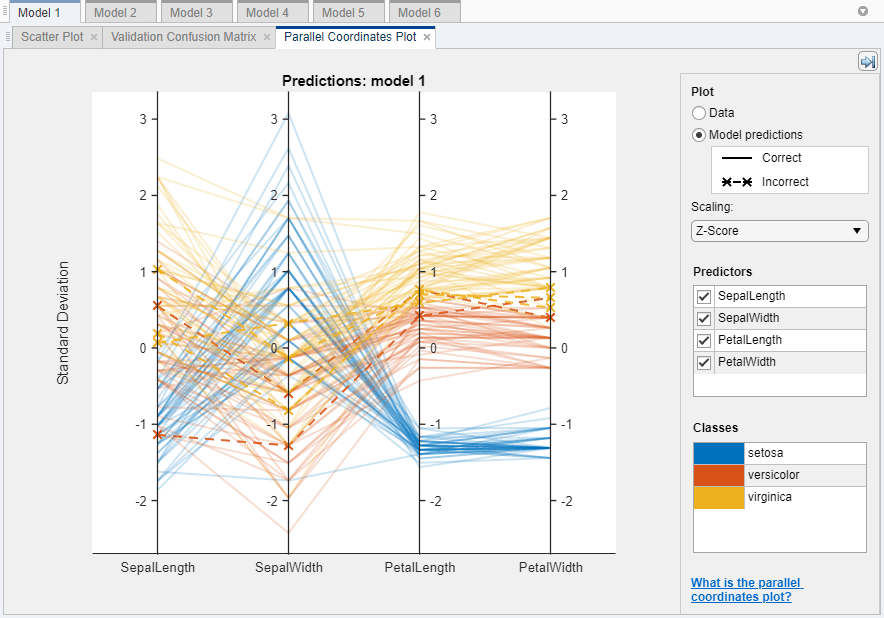
Чтобы исследовать функции, чтобы включать или исключить, используйте график рассеивания и параллельный график координат. На вкладке Classification Learner, в разделе Plots, кликают по стреле, чтобы открыть галерею, и затем нажать Parallel Coordinates в группе Validation Results. Вы видите, что лепестковая длина и лепестковая ширина являются функциями, которые разделяют классы лучше всего.
Чтобы узнать о настройках модели, выберите, модель в Models разделяют на области и просматривают расширенные настройки. nonoptimizable опции модели в галерее Model Type являются предварительно установленными начальными точками, и можно изменить дальнейшие настройки. На вкладке Classification Learner, в разделе Model Type, нажимают Advanced. Сравните простые и средние древовидные модели в панели Models и наблюдайте различия в Усовершенствованном Древовидном Окне параметров. Установка Maximum Number of Splits управляет древовидной глубиной.
Чтобы попытаться улучшить крупную древовидную модель далее, измените настройки Maximum Number of Splits и нажмите OK. Затем обучите новую модель путем нажатия на Train.
Просмотрите настройки для выбранной обученной модели в панели Current Model Summary, или в Усовершенствованном Древовидном Окне параметров.
Чтобы экспортировать лучшую обученную модель в рабочую область, на вкладке Classification Learner, в разделе Export, нажимают Export Model и выбирают Export Model. В диалоговом окне Export Model нажмите OK, чтобы принять имя переменной по умолчанию trainedModel.
Посмотрите в командном окне, чтобы видеть информацию о результатах.
Визуализировать вашу модель дерева принятия решения, введите:
view(trainedModel.ClassificationTree,'Mode','graph')
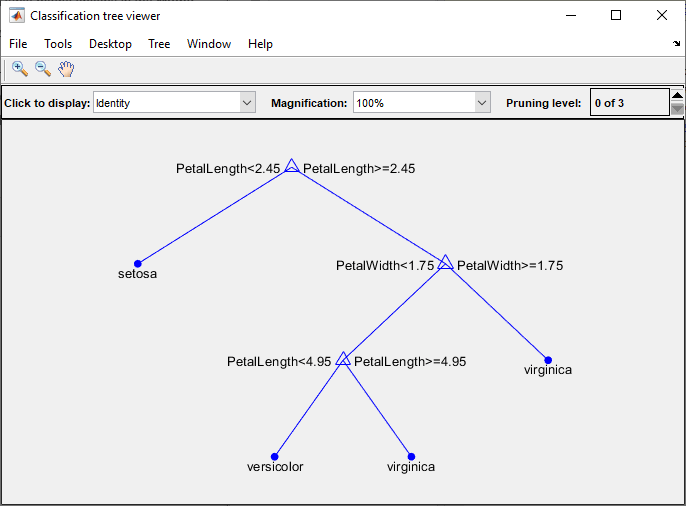
Можно использовать экспортируемый классификатор, чтобы сделать предсказания на новых данных. Например, чтобы сделать предсказания для fishertable данные в вашей рабочей области, введите:
yfit = trainedModel.predictFcn(fishertable)
yfit содержит предсказание класса для каждой точки данных.Если вы хотите автоматизировать обучение тот же классификатор с новыми данными или изучить, как программно обучить классификаторы, можно сгенерировать код из приложения. Чтобы сгенерировать код для лучшей обученной модели, на вкладке Classification Learner, в разделе Export, нажимают Generate Function.
Приложение генерирует код из вашей модели и отображает файл в редакторе MATLAB. Чтобы узнать больше, смотрите, Генерируют код MATLAB, чтобы Обучить Модель с Новыми Данными.
Этот пример использует 1 936 ирисовых данных Фишера. Ирисовые данные содержат измерения цветов: лепестковая длина, лепестковая ширина, длина чашелистика и ширина чашелистика для экземпляров от трех разновидностей. Обучите классификатор предсказывать разновидности на основе измерений предиктора.
Используйте тот же рабочий процесс, чтобы оценить и сравнить другие типы классификатора, которые можно обучить в Classification Learner.
Попробовать все nonoptimizable предварительные установки модели классификатора, доступные для вашего набора данных:
Кликните по стреле на ультраправом из раздела Model Type, чтобы расширить список классификаторов.
Нажмите All, затем нажмите Train.
Чтобы узнать о других типах классификатора, смотрите, Обучают Модели Классификации в Приложении Classification Learner.
