Обнаружение объектов с помощью глубокого обучения обеспечивает быстрое, и точное означает предсказывать местоположение объекта в изображении. Глубокое обучение является мощным методом машинного обучения, в котором детектор объектов автоматически изучает функции изображений, требуемые для задач обнаружения. Несколько методов для обнаружения объектов с помощью глубокого обучения доступны, такие как Faster R-CNN, вы только смотрите однажды (YOLO) v2, YOLO v3 и одно обнаружение выстрела (SSD).
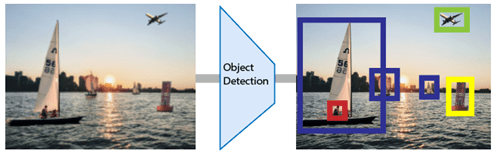
Приложения для обнаружения объектов включают:
Отобразите классификацию
Понимание сцены
Самоходные транспортные средства
Наблюдение
Используйте приложение для маркировки, чтобы интерактивно помечать достоверные данные в видео, последовательности изображений, коллекции изображений или пользовательском источнике данных. Можно пометить основную истину обнаружения объектов с помощью прямоугольных меток, которые задают положение и размер объекта в изображении.
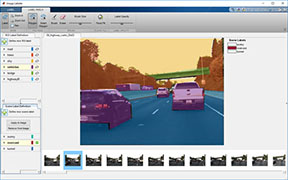
Используя данные увеличение обеспечивает способ использовать наборы ограниченных данных для обучения. Незначительные изменения, такие как перевод, обрезка, или преобразование изображения, обеспечивают, новые, отличные, и уникальные изображения, которые можно использовать, чтобы обучить устойчивый детектор. Хранилища данных являются удобным способом считать и увеличить наборы данных. Используйте imageDatastore и boxLabelDatastore создать хранилища данных для изображений и помеченных данных об ограничительной рамке.
Увеличьте ограничительные рамки для обнаружения объектов (Deep Learning Toolbox)
Предварительно обработайте изображения для глубокого обучения (Deep Learning Toolbox)
Предварительно обработайте данные для проблемно-ориентированного применения глубокого обучения (Deep Learning Toolbox)
Для получения дополнительной информации об увеличении обучающих данных с помощью хранилищ данных, смотрите Хранилища данных для Глубокого обучения (Deep Learning Toolbox) и Выполните Дополнительные Операции Обработки изображений Используя Встроенные хранилища данных (Deep Learning Toolbox).
Каждый детектор объектов содержит уникальную сетевую архитектуру. Например, детектор Faster R-CNN использует сеть 2D этапа для обнаружения, тогда как детектор YOLO v2 использует одноступенчатое. Используйте функции как fasterRCNNLayers или yolov2Layers создать сеть. Можно также спроектировать слой сети слоем с помощью Deep Network Designer (Deep Learning Toolbox).
Используйте trainFasterRCNNObjectDetector, trainYOLOv2ObjectDetector, trainSSDObjectDetector функции, чтобы обучить детектор объектов. Используйте evaluateDetectionMissRate и evaluateDetectionPrecision функции, чтобы оценить учебные результаты.
Обнаружьте объекты в изображении с помощью обученного детектора. Например, частичный код, показанный ниже использования обученный detector на изображении I. Используйте detect возразите функции на fasterRCNNObjectDetector, yolov2ObjectDetector, yolov3ObjectDetector, или ssdObjectDetector объекты возвратить ограничительные рамки, баллы обнаружения и категориальные метки, присвоенные ограничительным рамкам.
I = imread(input_image) [bboxes,scores,labels] = detect(detector,I)
MathWorks® Репозиторий GitHub обеспечивает реализации последних предварительно обученных нейронных сетей для глубокого обучения обнаружения объектов, чтобы загрузить и использовать для выполнения вывода поля. Предварительно обученные сети обнаружения объектов уже обучены на стандартных наборах данных, таких как COCO и Паскаль наборы данных VOC. Можно использовать эти предварительно обученные модели непосредственно, чтобы обнаружить различные объекты в тестовом изображении.
Например:
Чтобы выполнить обнаружение объектов при помощи предварительно обученного вы только смотрите однажды (YOLO) v2 и v4 нейронные сети для глубокого обучения, смотрите, что Обнаружение объектов Использует Предварительно обученную нейронную сеть для глубокого обучения YOLO v2 и Обнаружение объектов Используя Предварительно обученную нейронную сеть для глубокого обучения YOLO v4, соответственно.
Чтобы выполнить текстовое обнаружение скана при помощи предварительно обученной нейронной сети для глубокого обучения, смотрите Предварительно обученную Символьную Осведомленность области Для текстовой Модели Обнаружения. Можно использовать предварительно обученная модель, чтобы обнаружить тексты в изображениях. Модель может обнаружить текст на этих семи языках: английский, корейский, итальянский, французский, арабский, немецкий и Bangla.
Поскольку список всего последнего MathWorks предварительно обучил модели и примеры, смотрите Глубокое обучение MATLAB (GitHub).
