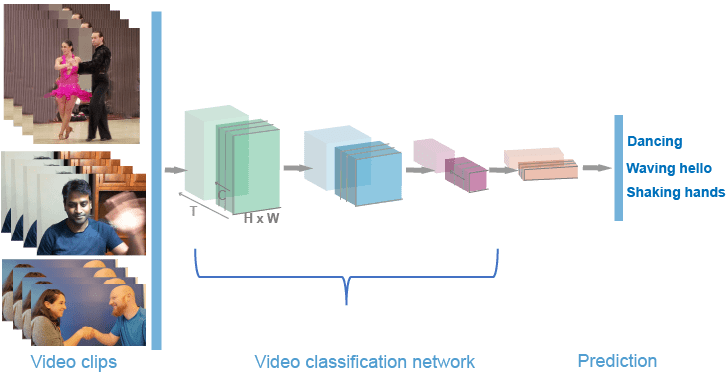
Видео классификация подобна, чтобы отобразить классификацию, на которую алгоритм использует экстракторы функции, такие как сверточные нейронные сети (CNNs), чтобы извлечь дескрипторы функции из последовательности изображений и затем классифицировать их в категории. Видео классификация с помощью глубокого обучения обеспечивает средние значения, чтобы анализировать, классифицировать, и отследить действие, содержавшееся в визуальных источниках данных, таких как видеопоток. Видео классификация имеет много приложений, таких как распознавание деятельности человека, распознавание жеста, обнаружение аномалии и наблюдение.
Видео методология классификации включает эти шаги:
Подготовьте обучающие данные
Выберите видео классификатор
Обучите и оцените классификатор
Используйте классификатор, чтобы обработать видеоданные
Можно обучить классификатор с помощью видео классификатора, предварительно обученного на большом наборе видеоданных распознавания активности, таком как кинетика 400 Наборов данных Человеческой деятельности, которые являются крупномасштабным и высококачественным набором набора данных. Запустите путем предоставления видео классификатору помеченные видеоклипы или видеоклипы. Затем с помощью классификатора видео глубокого обучения, который состоит из нейронных сетей свертки, которые совпадают с природой ввода видео, можно предсказать и классифицировать видео. Идеально, ваш рабочий процесс должен включать оценку вашего классификатора. Наконец, можно использовать классификатор, чтобы классифицировать действие на набор видео или потокового видео от веб-камеры.
Computer Vision Toolbox™ обеспечивает медленную и быструю трассу (SlowFast), ResNet с (2+1) свертки D и 2D поток расширенные 3D методы для обучения классификатор видео классификации.
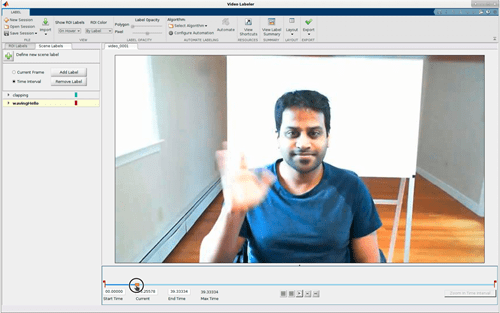
Чтобы обучить сеть классификатора, вам нужны набор видео и его соответствующий набор меток сцены. Метка сцены является меткой, применился к области значений времени в видео. Например, вы могли пометить область значений систем координат "jumping".
Можно использовать Video Labeler или Ground Truth Labeler (Automated Driving Toolbox), чтобы интерактивно помечать достоверные данные в видео, последовательности изображений или пользовательском источнике данных с метками сцены. Для сводных данных все этикетировочные машины смотрите, Выбирают App to Label Ground Truth Data.
Приложения этикетировочной машины экспортируют маркированные данные в файлы MAT, которые содержат groundTruth объекты. Для примера, показывающего, как извлечь обучающие данные из объектов основной истины, смотрите Обучающие данные Извлечения для Видео Классификации.
Увеличение данных обеспечивает способ использовать наборы ограниченных данных для обучения. Незначительные изменения, такие как перевод, обрезка, или преобразование изображения, обеспечивают новые, отличные, и уникальные изображения, которые можно использовать, чтобы обучить устойчивый видео классификатор. Хранилища данных являются удобным способом считать и увеличить наборы данных. Используйте fileDatastore функция с read функция, которая использует VideoReader чтобы считать видеофайлы, создать хранилища данных для видео и помеченной сцены помечают данные. Для примера, который увеличивает и предварительно обрабатывает данные, смотрите, что Распознавание Жеста Использует Изучение Классификатора DeepVideo.
Чтобы изучить, как увеличить и предварительно обработать данные, смотрите, Выполняют Дополнительные Операции Обработки изображений Используя Встроенные хранилища данных (Deep Learning Toolbox) и Хранилища данных для Глубокого обучения (Deep Learning Toolbox).
Выберите один из перечисленного видео классификатора возражает, чтобы создать предварительно обученные модели моделей использования сетей классификации глубокого обучения с помощью кинетики 400 наборов данных (который содержит 400 меток класса):
slowFastVideoClassifier модель предварительно обучена на кинетике 400 наборов данных, которые содержат остаточную модель сети ResNet-50 как магистральную архитектуру с медленными и быстрыми трассами. Эта функциональность требует Модели Computer Vision Toolbox для Классификации Видео SlowFast.
r2plus1dVideoClassifier модель предварительно обучена на кинетике 400 наборов данных, которые содержат 18 пространственно-временных (ST) остаточных слоев. Эта функциональность требует Модели Computer Vision Toolbox для R (2+1) Видео Классификация D.
inflated3dVideoClassifier модель содержит две подсети: видео сеть и сеть оптического потока. Эти сети обучены на кинетике 400 наборов данных с потоком данных RGB и данными об оптическом потоке, соответственно. Эта функциональность требует Модели Computer Vision Toolbox для расширенной 3D Видео Классификации.
Таблица обеспечивает сравнение их, глубокое обучение поддержало классификаторы:
Модель | Источники данных | Размер модели классификатора (Pretained на кинетике 400 наборов данных) | Поддержка графического процессора | Несколько классифицируют поддержку | Описание |
|---|---|---|---|---|---|
SlowFast | Видеоданные | 124 Мбайта | Да | Да |
|
R (2+1) D | Видеоданные | 112 Мбайт | Да | Да |
|
Расширенный 3D |
| 91 Мбайт | Да | Да |
|
Эта таблица показывает пример кода, который можно использовать, чтобы создать видео классификатор с помощью каждого из перечисленных видео классификаторов:
| Видео классификатор | Демонстрационный код создания |
|---|---|
SlowFast |
inputSize = [112 112 64 3]; classes = ["wavingHello","clapping"]; sf = slowFastVideoClassifier("resnet50-3d",classes,InputSize=inputSize) |
R (2+1) D |
inputSize = [112 112 64 3]; classes = ["wavingHello","clapping"]; rd = r2plus1dVideoClassifier("resnet-3d-18",classes,InputSize=inputSize) |
Расширенный 3-D |
inputSize = [112 112 64 3]; classes = ["wavingHello","clapping"]; i3d = inflated3dVideoClassifier("googlenet-video-flow",classes,InputSize=inputSize) |
Чтобы изучить, как обучить и оценить результаты для перечисленных видео классификаторов, смотрите эти примеры:
Распознавание жеста Используя Классификатор DeepVideo, Учащийся — Обучает и оценивает классификатор видео SlowFast
Распознавание активности Используя R (2+1) Видео Классификация D — Обучает и оценивает R (2+1) видео классификатор D
Распознавание активности из Данных о Видео и Оптическом потоке Используя Глубокое обучение — Обучает и оценивает 2D поток расширенный 3D видео классификатор
Чтобы изучить, как классифицировать видео с помощью видео классификатора, смотрите эти примеры:
