Можно использовать группирующиеся переменные, чтобы разделить переменные данных в группы. Как правило, выбор группирующихся переменных является первым шагом в рабочем процессе "Разделение, Применяют Объединение". Можно разделить данные в группы, применить функцию к каждой группе и объединить результаты. Также можно обозначить отсутствующие значения в группирующихся переменных, так, чтобы были проигнорированы соответствующие значения в переменных данных.
Группирующиеся переменные являются переменными, используемыми, чтобы сгруппировать, или категоризировать, наблюдения — то есть, значения данных в других переменных. Группирующаяся переменная может быть любым из этих типов данных:
Числовой, логический, категориальный, datetime или вектор duration
Массив ячеек из символьных векторов
Таблица, с табличными переменными любого типа данных в этом списке
Переменные данных являются переменными, которые содержат наблюдения. Группирующаяся переменная должна иметь значение, соответствующее каждому значению в переменных данных. Значения данных принадлежат той же группе, когда соответствующие значения в группирующейся переменной являются тем же самым.
Эта таблица показывает примеры переменных данных, группируя переменные и группы, что можно создать, когда вы разделяете переменные данных с помощью группирующихся переменных.
Переменная данных | Группировка переменной | Группы данных |
|---|---|---|
|
|
|
|
|
|
|
|
|
Можно дать группы понятных имен данных, когда вы используете массивы ячеек из символьных векторов или категориальные массивы как группирующиеся переменные. Категориальный массив является эффективным и гибким выбором группировки переменной.
Как правило, существует столько же групп, сколько существуют уникальные значения в группирующейся переменной. (Категориальный массив также может включать категории, которые не представлены в данных.) Группы и порядок групп зависят от типа данных группирующейся переменной.
Для числового, логического, datetime, или векторов duration или массивов ячеек из символьных векторов, группы соответствуют уникальным значениям, отсортированным в порядке возрастания.
Для категориальных массивов группы соответствуют уникальным значениям, наблюдаемым в массиве, отсортированном в порядке, возвращенном функцией categories.
Функция findgroups может принять несколько группирующихся переменных, например G = findgroups(A1,A2). Также можно включать несколько группирующихся переменных в таблицу, например T = table(A1,A2); G = findgroups(T). Функция findgroups задает группы уникальными комбинациями значений через соответствующие элементы группирующихся переменных. findgroups решает порядок по приказу первой переменной группировки, и затем по приказу второй переменной группировки, и так далее. Например, если A1 = {'a','a','b','b'} и A2 = [0 1 0 0], то уникальными значениями через группирующиеся переменные является 'a' 0, 'a' 1 и 'b' 0, задавая три группы.
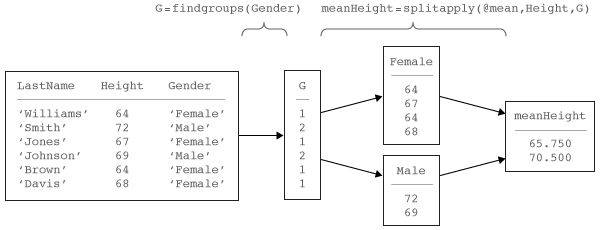
После того, как вы выберете группирующиеся переменные и разделите переменные данных в группы, можно применить функции к группам и объединить результаты. Этот рабочий процесс называется, рабочий процесс "Разделение Применяет Объединение". Можно использовать findgroups, и splitapply функционирует вместе, чтобы анализировать группы данных в этом рабочем процессе. Эта схема показывает простой пример с помощью группирующегося переменного Gender и переменной данных Height, чтобы вычислить среднюю высоту полом.
Функция findgroups возвращает вектор чисел группы, которые задают группы на основе уникальных значений в группирующихся переменных. splitapply использует числа группы, чтобы разделить данные в группы эффективно прежде, чем применить функцию.
Группировка переменных может иметь отсутствующие значения. Эта таблица показывает индикатор отсутствующего значения для каждого типа данных. Если группирующаяся переменная имеет отсутствующие значения, то findgroups присваивает NaN как номер группы, и splitapply игнорирует соответствующие значения в переменных данных.
Группировка переменного типа данных | Индикатор отсутствующего значения |
|---|---|
Числовой |
|
Логический | (Не может отсутствовать), |
Категориальный |
|
|
|
|
|
Массив ячеек из символьных векторов |
|
|
Строка |
|
findgroups | rowfun | splitapply | varfun
