Разделите данные в группы и примените функцию
Y = splitapply(func,X,G)Y = splitapply(func,X1,...,XN,G)Y = splitapply(func,T,G)[Y1,...,YM] = splitapply(___)Y = splitapply(func,X,G) X в группы, заданные G, и применяет функциональный func к каждой группе. splitapply возвращает Y как массив, который содержит конкатенированные выходные параметры от func для разделения групп из X. G входного параметра является вектором положительных целых чисел, который задает группы, которым принадлежат соответствующие элементы X. Если G содержит значения NaN, splitapply не использует соответствующие значения в X, когда это разделяет X в группы. Чтобы создать G, можно использовать функцию findgroups.
splitapply объединяется, два шага в Рабочем процессе "Разделение Применяют Объединение".
Y = splitapply(func,X1,...,XN,G) X1,...,XN в группы и применяет func. Вызовы функции splitapply func однажды на группу, с соответствующими элементами от X1,...,XN как входные параметры N к func.
Y = splitapply(func,T,G) T в группы и применяет func. Функция splitapply обрабатывает переменные T как векторы, матрицы или массивы ячеек, в зависимости от типов данных табличных переменных. Если T имеет переменные N, то func должен принять входные параметры N.
[Y1,...,YM] = splitapply(___) разделяет переменные в группы и применяет func к каждой группе. func возвращает несколько выходных аргументов. Y1,...,YM содержит конкатенированные выходные параметры от func для разделения групп из переменных входных данных. func может возвратить выходные аргументы, которые принадлежат различным классам, но класс каждого вывода должен быть тем же каждым разом, когда func называется. Можно использовать этот синтаксис с любым из входных параметров предыдущих синтаксисов.
Количество выходных аргументов от func не должно совпадать с количеством входных параметров, заданных X1,...,XN.
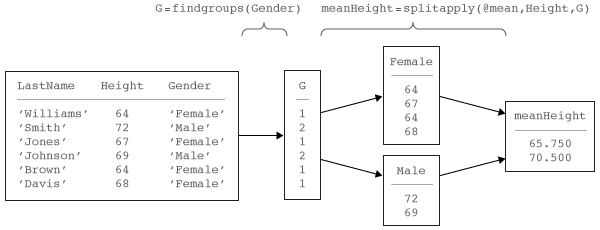
Рабочий процесс "Разделение Применяется, Объединение" распространено в анализе данных. В этом рабочем процессе аналитик разделяет данные в группы, применяет функцию к каждой группе и комбинирует результаты. Схема показывает типичный пример рабочего процесса и части рабочего процесса, реализованного findgroups и splitapply.
accumarray | arrayfun | дискретизация | findgroups | groupsummary | histcounts | rowfun | уникальный | varfun
