Найдите группы и возвратите числа группы
G = findgroups(A)G = findgroups(A1,...,AN)[G,ID] = findgroups(A)[G,ID1,...,IDN] = findgroups(A1,...,AN)G = findgroups(T)[G,TID] = findgroups(T)G = findgroups(A) G, вектор чисел группы, созданных из группирующегося переменного A. Выходной аргумент G содержит целочисленные значения от 1 до N, указывая на N отличные группы для N уникальные значения в A. Например, если A является {'b','a','a','b'}, то findgroups возвращает G как [2 1 1 2]. Можно использовать G, чтобы разделить группы данных из других переменных. Использование G как входной параметр к splitapply в Рабочем процессе "Разделение Применяет Объединение".
findgroups обрабатывает пустые символьные вектора и NaN, NaT и неопределенные категориальные значения в A как отсутствующие значения и возвращает NaN как соответствующие элементы G.
G = findgroups(A1,...,AN)A1,...,AN. Функция findgroups задает группы как уникальные комбинации значений через A1,...,AN. Например, если A1 является {'a','a','b','b'}, и A2 является [0 1 0 0], то findgroups(A1,A2) возвращает G как [1 2 3 3], потому что комбинация 'b' 0 происходит дважды.
[G,ID] = findgroups(A) ID. Например, если A является {'b','a','a','b'}, то findgroups возвращает G как [2 1 1 2] и ID как {'a','b'}. Аргументы A и ID являются совпадающим типом данных, но не должны быть одного размера.
[G,ID1,...,IDN] = findgroups(A1,...,AN)ID1,...,IDN. Значения через ID1,...,IDN задают группы. Например, если A1 является {'a','a','b','b'}, и A2 является [0 1 0 0], то findgroups(A1,A2) возвращает G как [1 2 3 3], и ID1 и ID2 как {'a','a','b'} и [0 1 0].
G = findgroups(T) G, вектор чисел группы, созданных из переменных в таблице T. Функция findgroups обрабатывает все переменные в T как группирующиеся переменные.
[G,TID] = findgroups(T) TID, таблица, которая содержит уникальные значения для каждой группы. TID содержит уникальные комбинации значений через переменные T. Переменные в T и TID имеют те же имена, но таблицы не должны иметь того же количества строк.
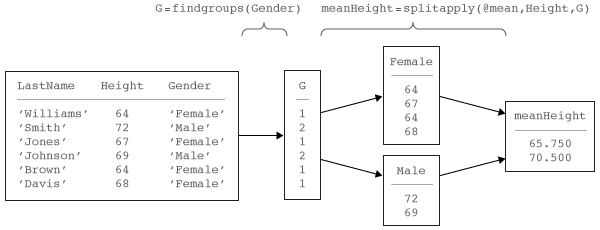
Рабочий процесс "Разделение Применяется, Объединение" распространено в анализе данных. В этом рабочем процессе аналитик разделяет данные в группы, применяет функцию к каждой группе и комбинирует результаты. Схема показывает типичный пример рабочего процесса и части рабочего процесса, реализованного findgroups и splitapply.
accumarray | arrayfun | дискретизация | groupsummary | histcounts | ismember | rowfun | splitapply | уникальный | varfun
