Выровняйте два набора данных, содержащие последовательные наблюдения путем представления разрывов
[I, J]
= samplealign(X, Y)
[I, J]
= samplealign(X, Y,
...'Band', BandValue, ...)
[I, J]
= samplealign(X, Y,
...'Width', WidthValue, ...)
[I, J]
= samplealign(X, Y,
...'Gap', GapValue, ...)
[I, J]
= samplealign(X, Y,
...'Quantile', QuantileValue, ...)
[I, J]
= samplealign(X, Y,
...'Distance', DistanceValue, ...)
[I, J]
= samplealign(X, Y,
...'Weights', WeightsValue, ...)
[I, J]
= samplealign(X, Y,
...'ShowConstraints', ShowConstraintsValue,
...)
[I, J]
= samplealign(X, Y,
...'ShowNetwork', ShowNetworkValue, ...)
[I, J]
= samplealign(X, Y,
...'ShowAlignment', ShowAlignmentValue,
...)
X, y | Матрицы данных, где строки соответствуют наблюдениям или выборкам и столбцам, соответствуют функциям или размерностям. X и Y могут иметь различное количество строк, но у них должно быть одинаковое число столбцов. Первый столбец является ссылочной размерностью и должен содержать уникальные значения в порядке возрастания. Ссылочная размерность могла содержать демонстрационные индексы наблюдений или измеримого значения, таких как время. |
BandValue | Любое из следующего:
|
WidthValue | Любое из следующего:
|
GapValue | Любое следующее:
|
QuantileValue | Скаляр между 0 и 1, который задает значение квантиля, используемое, чтобы вычислить термин QMS, который используется свойством 'Gap' вычислить штрафы разрыва. Значением по умолчанию является 0.75. |
DistanceValue | Указатель на функцию, заданный с помощью
Значением по умолчанию является Евклидово расстояние между парами. ВниманиеВсе столбцы в |
WeightsValue | Любое из следующего:
Это свойство управляет включением/исключением столбцов (функции) или акцент столбцов (функции) при вычислении счета расстояния между наблюдениями, которые являются потенциальными соответствиями, то есть, при использовании свойства СоветИспользуя числовой вектор - строку для ПримечаниеЗначения веса не рассматриваются при использовании |
ShowConstraintsValue | Управляет отображением пространства поиска, ограниченного заданными параметрами входа 'Band' и 'Width', таким образом, давая индикацию относительно памяти, требуемой запускать алгоритм с определенным 'Band' и параметрами 'Width' на ваших наборах данных. Выбором является true или false (значение по умолчанию). |
ShowNetworkValue | Управляет отображением динамической сети программирования, очков соответствия, штрафов разрыва и пути к победе. Выбором является true или false (значение по умолчанию). |
ShowAlignmentValue | Управляет отображением первых и вторых столбцов X и наборов данных Y в абсциссе и ординате соответственно, двумерного графика. Выбором является true, false (значение по умолчанию) или целое число, задающее столбец X и наборов данных Y, чтобы построить как ордината. |
I | Вектор-столбец, содержащий индексы строк (наблюдения) в X, которые соответствуют к строке (наблюдение) в Y. Недостающие индексы указывают, что строка (наблюдение) является соответствующей к разрыву. |
J | Вектор-столбец, содержащий индексы строк (наблюдения) в Y, которые соответствуют к строке (наблюдение) в X. Недостающие индексы указывают, что строка (наблюдение) является соответствующей к разрыву. |
[ выравнивает наблюдения в двух матрицах данных, I, J]
= samplealign(X, Y)X и Y, путем представления разрывов. X и Y являются матрицами данных, где строки соответствуют наблюдениям или выборкам, и столбцы соответствуют функциям или размерностям. X и Y могут иметь различное количество строк, но должны иметь одинаковое число столбцов. Первый столбец является ссылочной размерностью и должен содержать уникальные значения в порядке возрастания. Ссылочная размерность могла содержать демонстрационные индексы наблюдений или измеримого значения, таких как время. Функция samplealign использует динамический алгоритм программирования, чтобы минимизировать сумму положительных очков, следующих из пар наблюдений, которые являются потенциальными соответствиями и штрафами, следующими из вставки разрывов. I возвращаемых значений и J являются вектор-столбцами, содержащими индексы, которые указывают на соответствия для каждой строки (наблюдение) в X и Y соответственно.
Если вы не задаете возвращаемые значения, samplealign не запускает динамический алгоритм программирования. Запуская samplealign без возвращаемых значений, но устанавливая 'ShowConstraints', 'ShowNetwork' или свойство 'ShowAlignment' к true, позволяет вам исследовать ограниченное пространство поиска, динамическую сеть программирования или выровненные наблюдения, не сталкиваясь с потенциальными проблемами памяти.
[I, J] = samplealign(X, Y, ...'PropertyName', PropertyValue, ...) samplealign с дополнительными свойствами, которые используют имя свойства / пары значения свойства. Можно задать одно или несколько свойств в любом порядке. Каждый PropertyName должен быть заключен в одинарные кавычки и нечувствительный к регистру. Это имя свойства / пары значения свойства следующие:
[ задает максимальное допустимое расстояние между наблюдениями (только по ссылочному измерению) в этих двух наборах данных, таким образом ограничивая количество потенциальных соответствий между наблюдениями в этих двух наборах данных. Если I, J]
= samplealign(X, Y,
...'Band', BandValue, ...)S является значением в ссылочной размерности для данного наблюдения (строка) в одном наборе данных, то то наблюдение является соответствующим только с наблюдениями в другом наборе данных, значения которого в ссылочной размерности находятся в пределах S ± BandValue. Затем только эти потенциальные соответствия передаются алгоритму для дальнейшего выигрыша. BandValue может быть скаляром или функцией, заданной с помощью @(z)z является средней точкой между данным наблюдением в одном наборе данных и данным наблюдением в другом наборе данных. BandValue по умолчанию является Inf.
Это ограничение уменьшает время и сложность памяти алгоритма от O (MN) к O (sqrt (MN) *K), где M и N являются количеством наблюдений в X и Y соответственно, и K является маленькой константой, таким образом что K <<M и K <<N. Настройте BandValue к максимальному ожидаемому сдвигу между ссылочными размерностями в этих двух наборах данных, то есть, между X (: 1) и Y (: 1).
[ ограничивает количество потенциальных соответствий между наблюдениями в двух наборах данных; то есть, каждое наблюдение в I, J]
= samplealign(X, Y,
...'Width', WidthValue, ...)X выиграно к самым близким наблюдениям U в Y, и каждое наблюдение в Y выиграно к самым близким наблюдениям V в X. Затем только эти потенциальные соответствия передаются алгоритму для дальнейшего выигрыша. WidthValue является любой двухэлементным вектором, [U, V] или скаляр, который используется и для U и для V. Близость измеряется с помощью только первый столбец (ссылочная размерность) в каждом наборе данных. Значением по умолчанию является Inf, если 'Band' задан; в противном случае значением по умолчанию является 10.
Это ограничение уменьшает время и сложность памяти алгоритма от O (MN) к O (sqrt (MN) *sqrt (UV)), где M и N являются количеством наблюдений в X и Y соответственно, и U и V маленькие таким образом что U <<M и V <<N.
Если вы задаете и 'Band' и 'Width', только пары наблюдений, которые соответствуют обоим ограничениям, рассматриваются потенциальными соответствиями и передаются алгоритму для выигрыша.
Задайте 'Width', когда у вас не будет хорошей оценки для свойства 'Band'. Чтобы получить индикацию относительно памяти, требуемой запускать алгоритм с определенным 'Band' и параметрами 'Width' на ваших наборах данных, запустите samplealign, но не задавайте возвращаемые значения и устанавливайте 'ShowConstraints' на true.
[ задает позиционно-зависимые условия для присвоения штрафов разрыва. I, J]
= samplealign(X, Y,
...'Gap', GapValue, ...)
GapValue является любым следующим:
Массив ячеек, {G, H}, где G является или скаляром или указателем на функцию, заданным с помощью @(X)H, является или скаляром или указателем на функцию, заданным с помощью @(Y)@(X)и @(Y)@(X)@(Y)X или Y, содержа штраф разрыва за каждое наблюдение (строка).
Один указатель на функцию задал с помощью @(Z)G и для H. Функциональный @(Z)X и в Y, когда это является соответствующим к разрыву в другом наборе данных. Функциональный @(Z)X и Y. Функциональный @(Z)X или Y, содержа штраф разрыва за каждое наблюдение (строка).
Скаляр, который используется и для G и для H.
Расчетное значение, GPX, является штрафом разрыва за соответствие с наблюдениями от первого набора данных X к разрывам, вставленным во второй набор данных Y, и является продуктом двух условий: GPX = G * QMS. Термин G принимает свое значение как функция наблюдений в X. Точно так же GPY является штрафом разрыва за соответствие с наблюдениями от Y до разрывов, вставленных в X, и является продуктом двух условий: GPY = H * QMS. Термин H принимает свое значение как функция наблюдений в Y. По умолчанию термин QMS является 0,75 квантилями счета к парам наблюдений, которые являются потенциальными соответствиями (то есть, пары, которые выполняют 'Band' и ограничения 'Width').
Если G и H являются положительными скалярными величинами, то GPX и GPY независимы от наблюдения, где разрыв вставляется.
GapValue по умолчанию является 1, то есть, и G и H является 1, который указывает, что штраф по умолчанию за вставки разрыва в обеих последовательностях эквивалентен квантилю (установленный свойством 'Quantile', значение по умолчанию = 0.75) счета к парам наблюдений, которые являются потенциальными соответствиями.
Значения по умолчанию GapValue к относительно безопасному значению. Однако успех алгоритма зависит от точной настройки штрафов разрыва, которая является зависящей от приложения. Когда штрафы разрыва являются большими относительно счета правильных соответствий, samplealign возвращает выравнивания с меньшим количеством разрывов, но с более неправильно выровненными областями. Когда штрафы разрыва меньше, выходное выравнивание содержит более длинные области с разрывами и меньшим количеством совпадающих наблюдений. Установите 'ShowNetwork' на true сравнивать штрафы разрыва счету совпадающих наблюдений в различных областях выравнивания.
[ задает значение квантиля, используемое, чтобы вычислить термин I, J]
= samplealign(X, Y,
...'Quantile', QuantileValue, ...)QMS, который используется свойством 'Gap' вычислить штрафы разрыва. QuantileValue является скаляром между 0 и 1. Значением по умолчанию является 0.75.
Установите QuantileValue на пустой массив ([]) делать штрафы разрыва независимыми от QMS, то есть, GPX и GPY являются функциями только параметров входа G и H соответственно.
[ задает функцию, чтобы вычислить расстояние между парами наблюдений, которые являются потенциальными соответствиями. I, J]
= samplealign(X, Y,
...'Distance', DistanceValue, ...)DistanceValue является указателем на функцию, заданным с помощью @(R,S)@(R,S) R и S, матриц, которые имеют одинаковое число строк и столбцы, и чьи парные строки представляют все потенциальные соответствия наблюдений в X и Y соответственно. Функциональный @(R,S) R и S. Значением по умолчанию является Евклидово расстояние между парами.
Все столбцы в X и Y, включая ссылочную размерность, рассматриваются при вычислении расстояний. Если вы не хотите включать ссылочную размерность на расстоянии вычисления, используйте свойство 'Weight' исключить ее.
[ управляет включением/исключением столбцов (функции) или акцент столбцов (функции) при вычислении счета расстояния между наблюдениями, которые являются потенциальными соответствиями, который является при использовании свойства I, J]
= samplealign(X, Y,
...'Weights', WeightsValue, ...)'Distance'. WeightsValue может быть логическим вектором - строкой, который задает столбцы в X и Y. WeightsValue может также быть числовым вектором - строкой с тем же числом элементов как столбцы в X и Y, который задает относительные веса столбцов (функции). Значением по умолчанию является логический вектор - строка со всем набором элементов к true.
Используя числовой вектор - строку для WeightsValue и устанавливающий некоторые значения к 0 может упростить расчет расстояния, когда наборы данных имеют много столбцов (функции).
Значения веса не рассматриваются при вычислении ограниченного пробела выравнивания, который является при использовании свойств 'Band' или 'Width', или при вычислении штрафов разрыва, который является при использовании свойства 'Gap'.
[ управляет отображением пространства поиска, ограниченного входными параметрами I, J]
= samplealign(X, Y,
...'ShowConstraints', ShowConstraintsValue,
...)'Band' и 'Width', давая индикацию относительно памяти, требуемой запускать алгоритм с определенным 'Band' и 'Width' на ваших наборах данных. Выбором является true или false (значение по умолчанию).
[ управляет отображением динамической сети программирования, очков соответствия, штрафов разрыва и пути к победе. Выбором является I, J]
= samplealign(X, Y,
...'ShowNetwork', ShowNetworkValue, ...)true или false (значение по умолчанию).
[ управляет отображением первых и вторых столбцов I, J]
= samplealign(X, Y,
...'ShowAlignment', ShowAlignmentValue,
...)X и наборов данных Y в абсциссе и ординате соответственно, двумерного графика. Отображены ссылки между всеми потенциальными соответствиями, которые соответствуют ограничениям, и соответствия, принадлежащие выходному выравниванию, подсвечены. Выбором является true, false (значение по умолчанию) или целое число, задающее столбец X и наборов данных Y, чтобы построить как ордината.
Загрузите sunspot.dat, файл данных, включенный с MATLAB, который содержит переменную sunspot, которая является матрицей 2D столбца, содержащей изменения в действии солнечного пятна за прошлые 300 лет. Первый столбец является ссылочной размерностью (годы), и второй столбец содержит значения действия солнечного пятна. Действие солнечного пятна циклично, достигая максимума о каждых 11 годах.
load sunspot.datСоздайте синусоиду с известным периодом действия солнечного пятна.
years = (1700:1990)'; T = 11.038; f = @(y) 60 + 60 * sin(y*(2*pi/T));
Выровняйте наблюдения между синусоидой и действием солнечного пятна путем представления разрывов.
[i,j] = samplealign([years f(years)],sunspot,'weights',... [0 1],'showalignment',true);
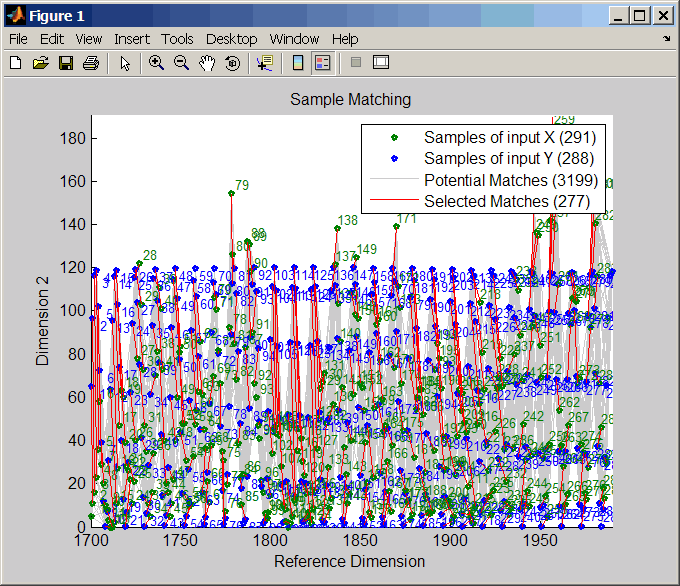
Оцените, что сглаженная функция деформирует синусоиду.
[p,s,mu] = polyfit(years(i),years(j),15); wy = @(y) polyval(p,(y-mu(1))./mu(2));
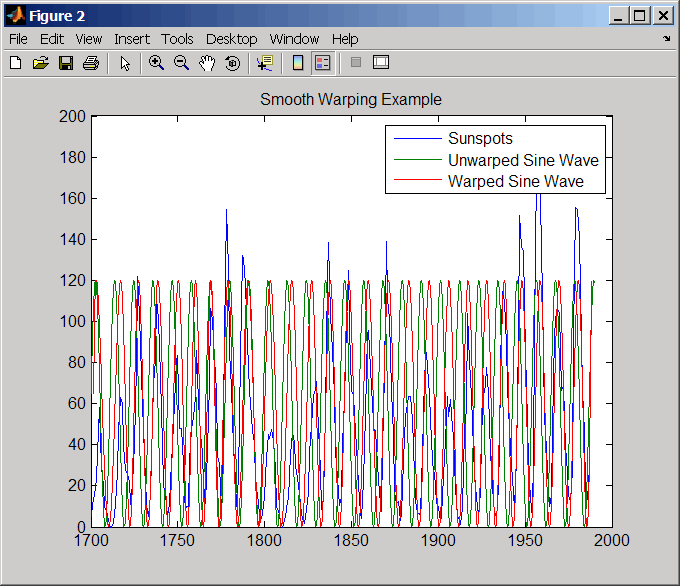
Постройте циклы солнечной активности, недеформированную синусоиду и деформированную синусоиду.
years = (1700:1/12:1990)'; figure plot(sunspot(:,1),sunspot(:,2),years,f(years),wy(years),... f(years)) legend('Sunspots','Unwarped Sine Wave','Warped Sine Wave') title('Smooth Warping Example')
Создайте два сигнала с шумным Гауссовым peaks.
rng('default')
peakLoc = [30 60 90 130 150 200 230 300 380 430];
peakInt = [7 1 3 10 3 6 1 8 3 10];
time = 1:450;
comp = exp(-(bsxfun(@minus,time,peakLoc')./5).^2);
sig_1 = (peakInt + rand(1,10)) * comp + rand(1,450);
sig_2 = (peakInt + rand(1,10)) * comp + rand(1,450);Задайте нелинейную функцию деформирования.
wf = @(t) 1 + (t<=100).*0.01.*(t.^2) + (t>100).*...
(310+150*tanh(t./100-3));Деформируйте второй сигнал исказить его.
sig_2 = interp1(time,sig_2,wf(time),'pchip');Выровняйте наблюдения между двумя сигналами путем представления разрывов.
[i,j] = samplealign([time;sig_1]',[time;sig_2]',... 'weights',[0,1],'band',35,'quantile',.5);
Постройте ссылочный сигнал, искаженный сигнал, и деформировал (исправленный) сигнал.
figure sig_3 = interp1(time,sig_2,interp1(i,j,time,'pchip'),'pchip'); plot(time,sig_1,time,sig_2,time,sig_3) legend('Reference','Distorted Signal','Corrected Signal') title('Non-linear Warping Example')

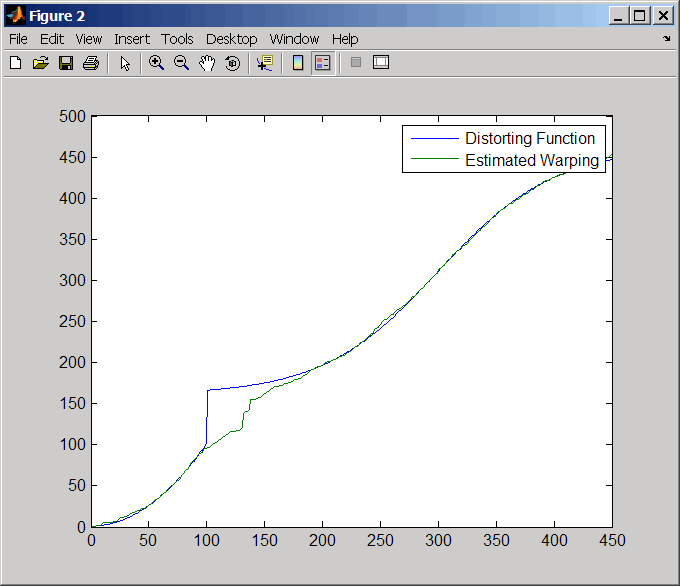
Постройте действительное и предполагаемые функции деформирования.
figure plot(time,wf(time),time,interp1(j,i,time,'pchip')) legend('Distorting Function','Estimated Warping')
Для примеров использования указателей на функцию для Band Gap и свойства Distance, видят Визуализацию и Предварительную обработку Написанных через дефис Наборов данных Масс-спектрометрии для Профилирования Метаболита и Белка/Пептида.
[1] Майерс, C.S. и Rabiner, L.R. (1981). Сравнительное исследование нескольких динамических деформирующих время алгоритмов для связанного распознавания слов. Система Bell Технический Журнал 60:7, 1389-1409.
[2] Sakoe, H. и Чиба, S. (1978). Динамическая оптимизация алгоритма программирования для распознавания произносимого слова. Сделка IEEE. Акустика, Речь и Обработка сигналов ASSP-26 (1), 43–49.
msalign | msheatmap | mspalign | msppresample | msresample
