Создайте график рассеивания с гистограммами
s = scatterhistogram(tbl,xvar,yvar)s = scatterhistogram(tbl,xvar,yvar,'GroupVariable',grpvar)s = scatterhistogram(xvalues,yvalues)s = scatterhistogram(xvalues,yvalues,'GroupData',grpvalues)s = scatterhistogram(___,Name,Value)s = scatterhistogram(parent,___)s = scatterhistogram(tbl,xvar,yvar)tbl и возвращает объект ScatterHistogramChart. Вход xvar указывает на табличную переменную, чтобы отобразиться вдоль x - ось. Вход yvar указывает на табличную переменную, чтобы отобразиться вдоль y - ось. Используйте s, чтобы изменить объект после того, как это будет создано. Для списка свойств смотрите ScatterHistogramChart Properties.
s = scatterhistogram(___,Name,Value)
s = scatterhistogram(parent,___)parent.
Создайте график рассеивания с крайними гистограммами из таблицы данных для медицинских пациентов.
Загрузите набор данных patients и составьте таблицу от подмножества переменных, загруженных в рабочую область. Затем создайте поля точек график гистограммы, сравнивающий значения Height со значениями Weight.
load patients tbl = table(LastName,Age,Gender,Height,Weight); s = scatterhistogram(tbl,'Height','Weight');

Используя набор данных patients, создайте график рассеивания с крайними гистограммами и задайте табличную переменную, чтобы использовать для группировки данных.
Загрузите набор данных patients и создайте поля точек график гистограммы от данных. Сравните Systolic пациентов и значения Diastolic. Сгруппируйте данные согласно состоянию курильщика пациентов путем установки аргумента пары "имя-значение" 'GroupVariable' 'Smoker'.
load patients tbl = table(LastName,Diastolic,Systolic,Smoker); s = scatterhistogram(tbl,'Diastolic','Systolic','GroupVariable','Smoker');

Используйте график рассеивания с крайними гистограммами, чтобы визуализировать категориальные и числовые медицинские данные.
Загрузите набор данных patients и преобразуйте данные Smoker в категориальный массив. Затем создайте поля точек график гистограммы, который сравнивает значения Age пациентов с их состоянием курильщика. Получившийся график рассеивания содержит перекрывающиеся точки данных. Однако крайняя гистограмма оси Y указывает, что существует намного больше некурящих, чем курильщики в наборе данных.
load patients Smoker = categorical(Smoker); s = scatterhistogram(Age,Smoker); xlabel('Age') ylabel('Smoker')

Создайте график рассеивания с крайними гистограммами с помощью массивов данных об обуви. Сгруппируйте данные согласно цвету обуви и настройте свойства поля точек графика гистограммы.
Создайте массивы данных. Затем создайте поля точек график гистограммы, чтобы визуализировать данные. Используйте пользовательские метки вдоль оси X и оси Y, чтобы задать имена переменных первых двух входных параметров. Можно задать заголовок, подписи по осям и заголовок легенды путем установки свойств объекта ScatterHistogramChart.
xvalues = [7 6 5 6.5 9 7.5 8.5 7.5 10 8];
yvalues = categorical({'onsale','regular','onsale','onsale', ...
'regular','regular','onsale','onsale','regular','regular'});
grpvalues = {'Red','Black','Blue','Red','Black','Blue','Red', ...
'Red','Blue','Black'};
s = scatterhistogram(xvalues,yvalues,'GroupData',grpvalues);
s.Title = 'Shoe Sales';
s.XLabel = 'Shoe Size';
s.YLabel = 'Price';
s.LegendTitle = 'Shoe Color';Измените цвета в поля точек графике гистограммы, чтобы совпадать с метками группы. Измените ширины интервала гистограммы, чтобы быть тем же самым для всех групп.
s.Color = {'Red','Black','Blue'};
s.BinWidths = 1;
Создайте график рассеивания с крайними гистограммами. Задайте количество интервалов и ширины строки гистограмм, местоположение графика рассеивания и видимость легенды.
Загрузите набор данных patients и создайте поля точек график гистограммы от данных. Сравните Diastolic пациентов и значения Systolic, и сгруппируйте данные согласно значениям SelfAssessedHealthStatus пациентов. Настройте гистограммы путем определения опций LineWidth и NumBins. Поместите график рассеивания в местоположение 'NorthEast' фигуры при помощи опции ScatterPlotLocation. Гарантируйте, что легенда видима путем определения опции LegendVisible как 'on'.
load patients tbl = table(LastName,Diastolic,Systolic,SelfAssessedHealthStatus); s = scatterhistogram(tbl,'Diastolic','Systolic','GroupVariable','SelfAssessedHealthStatus', ... 'NumBins',4,'LineWidth',1.5,'ScatterPlotLocation','NorthEast','LegendVisible','on');

Создайте график рассеивания с крайними гистограммами. Сгруппируйте данные при помощи комбинации двух различных переменных.
Загрузите набор данных patients. Объедините Smoker и данные Gender, чтобы создать новую переменную. Создайте поля точек график гистограммы, который сравнивает Diastolic и значения Systolic пациентов. Используйте новую переменную SmokerGender, чтобы сгруппировать данные в поля точек графике гистограммы.
load patients [idx,genderStatus,smokerStatus] = findgroups(string(Gender),string(Smoker)); SmokerGender = strcat(genderStatus(idx),"-",smokerStatus(idx)); s = scatterhistogram(Diastolic,Systolic,'GroupData',SmokerGender,'LegendVisible','on'); xlabel('Diastolic') ylabel('Systolic')

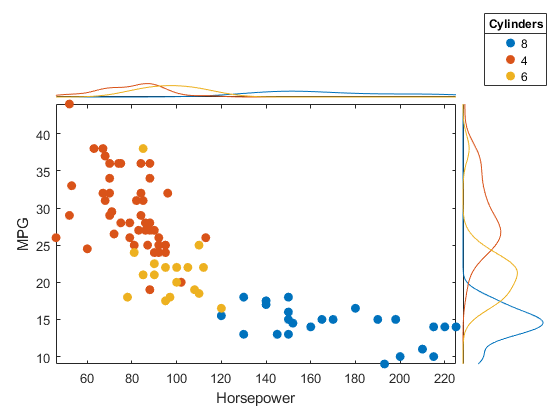
Создайте график рассеивания с плотностью ядра крайние гистограммы. Этот пример требует лицензии Statistics and Machine Learning Toolbox™.
Загрузите набор данных carsmall и создайте поля точек график гистограммы от данных. Сравните значения MPG и Horsepower. Используйте количество цилиндров, чтобы сгруппировать данные путем установки опции GroupVariable на Cylinders. Задайте гистограммы плотности ядра путем установки опции HistogramDisplayStyle на 'smooth'. Задайте сплошную линию для всех гистограмм путем установки опции LineStyle на '-'.
load carsmall tbl = table(Horsepower,MPG,Cylinders); s = scatterhistogram(tbl,'Horsepower','MPG', ... 'GroupVariable','Cylinders','HistogramDisplayStyle','smooth', ... 'LineStyle','-');
Чтобы в интерактивном режиме исследовать данные в вашем объекте ScatterHistogramChart, используйте эти опции. Некоторые из этих опций не доступны в Live Editor.
Изменение масштаба/панорамирование — Использование колесико прокрутки или кнопки + и -, чтобы масштабировать. Перетащите график рассеивания к панорамированию. scatterhistogram обновляет крайние гистограммы на основе данных в текущих пределах графика рассеивания.
Всплывающие подсказки — Наводят на график рассеивания или крайние гистограммы, чтобы отобразить всплывающую подсказку.
