Прогнозирующее обслуживание позволяет пользователям оборудования и производителям оценивать рабочее состояние машинного оборудования, диагностировать отказы или оценку, когда следующий отказ оборудования, вероятно, произойдет. Когда можно диагностировать или предсказать отказы, можно запланировать обслуживание заранее, лучше управлять материально-техническими ресурсами, уменьшать время простоя и увеличить операционную эффективность.
Разработка прогнозирующей программы обслуживания требует хорошо разработанной стратегии оценить рабочее состояние машинного оборудования и обнаружить начинающиеся отказы своевременно. Выполнение так требует эффективного использования и доступных измерений датчика и вашего знания системы. Необходимо многий принять факторы во внимание, включая:
Наблюдаемые источники отказов и их относительной частоты. Такие источники могут быть базовыми компонентами машины (такими как блейды рабочего колеса и клапаны потока в насосе), его приводы (такие как электродвигатель), или его различные датчики (такие как акселерометры и расходомеры).
Доступность измерений процесса через датчики. Номер, тип и местоположение датчиков, и их надежность и сокращение все влияют и на разработку алгоритмов и стоят.
Как различные источники отказов переводят в наблюдаемые признаки. Такой причинно-следственный анализ может потребовать обширной обработки данных из доступных датчиков.
Физическое знание о системной динамике. Это знание может прибыть из математического моделирования системы и ее отказов и от понимания специалистов по проблемной области. Понимание системной динамики включает детальное знание отношений среди различных сигналов от машинного оборудования (таких как отношения ввода - вывода среди приводов и датчиков), рабочий диапазон машины и природа измерений (например, периодический, постоянный или стохастический).
Окончательная цель обслуживания, такая как восстановление отказа или разработка графика обслуживания.
Прогнозирующая программа обслуживания использует мониторинг состояния и алгоритмы предзнаменований, чтобы анализировать данные, измеренные от системы в операции.
Condition monitoring использует данные из машины, чтобы оценить ее текущее положение и обнаружить и диагностировать отказы в машине. Данные о машине являются данными, такими как температура, давление, напряжение, шум или измерения вибрации, собранное использование выделило датчики. Алгоритм мониторинга состояния выводит метрики от названных индикаторов состояния данных. condition indicator является любой функцией системных данных, изменения поведения которых предсказуемым способом, когда система ухудшает. Индикатор состояния может быть любым количеством, выведенным от данных, что состояние аналогичной системы кластеров вместе, и отделяет различное состояние. Таким образом алгоритм мониторинга состояния может выполнить обнаружение отказа или диагноз путем сравнения новых данных с установленными маркерами дефектных условий.
Prognostics предсказывает, когда отказ произойдет на основе текущего и прошлого состояния машины. Алгоритм предзнаменований обычно оценивает remaining useful life машины (RUL) или время к отказу путем анализа текущего состояния машины. Предзнаменования могут использовать моделирование, машинное обучение или комбинацию обоих, чтобы предсказать будущие значения индикаторов состояния. Эти будущие значения затем используются, чтобы вычислить метрики RUL, которые определяют, если и когда обслуживание должно быть выполнено. Для примера коробки передач алгоритм предзнаменований может соответствовать переменной пиковой частоте вибрации и значению к временным рядам, чтобы предсказать их будущие значения. Алгоритм может затем сравнить ожидаемые значения с порогом, задающим здоровую операцию коробки передач, предсказав, если и когда отказ произойдет.
Прогнозирующая система обслуживания реализует предзнаменования и алгоритмы мониторинга состояния с другой инфраструктурой ИТ, которая делает конечные результаты алгоритма доступными и актуальными конечным пользователям, которые выполняют фактические задачи обслуживания. Predictive Maintenance Toolbox™ обеспечивает инструменты, чтобы помочь вам разработать такие алгоритмы.
Следующий рисунок показывает рабочий процесс для разработки прогнозирующего алгоритма обслуживания.
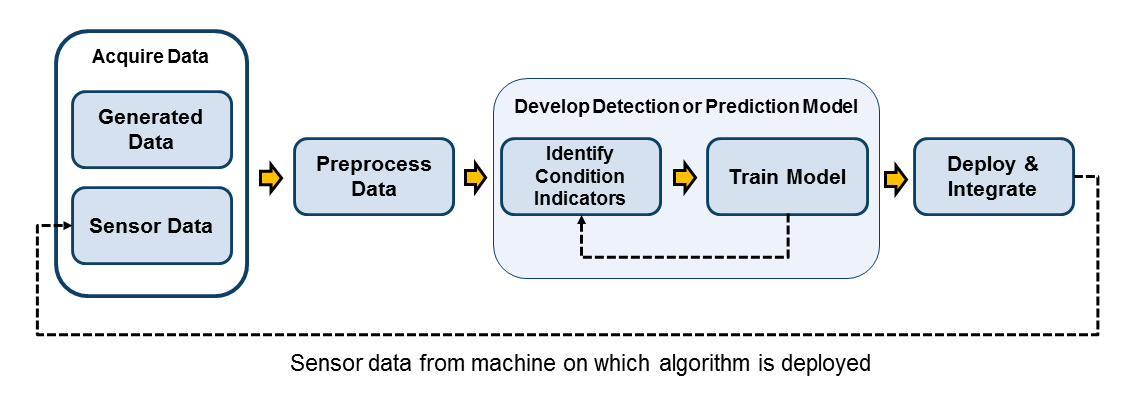
Начиная с данных, которые описывают вашу систему в области значений здоровых и дефектных условий, вы разрабатываете модель обнаружения (для мониторинга состояния) или модель прогноза (для предзнаменований). Разработка такой модели требует, чтобы идентифицирующие соответствующие индикаторы состояния и обучение модель интерпретировали их. Тот процесс, очень вероятно, будет итеративным, когда вы пробуете различные индикаторы состояния и различные модели, пока вы не находите лучшую модель для своего приложения. Наконец, вы развертываете алгоритм и интегрируете его в ваши системы для контроля машины и обслуживания.
Разработка прогнозирующих алгоритмов обслуживания начинается с массива данных. Часто необходимо справиться и процесс большие наборы данных, включая данные из нескольких датчиков и нескольких машин, запускающихся в разное время и под различными условиями работы. У вас может быть доступ к одному или нескольким следующих типов данных:
Действительные данные из операции нормальной системы
Действительные данные из системы, действующей в дефектном условии
Действительные данные из системных отказов (данные run-to-failure)
Например, у вас могут быть данные о датчике из работы системы, такой как температура, давление и вибрация. Такие данные обычно хранимы как сигнал или данные временных рядов. У вас могут также быть текстовые данные, такие как данные из обслуживания записывает, или данные в других формах. Эти данные хранятся в файлах, базах данных или распределенных файловых системах, таких как Hadoop®.
Во многих случаях данные об отказе из машин не доступны, или только ограниченное количество наборов данных отказа существуют из-за регулярного выполняемого обслуживания и относительная редкость таких инцидентов. В этом случае данные об отказе могут быть сгенерированы из модели Simulink® представление работы системы при различных условиях отказа.
Predictive Maintenance Toolbox обеспечивает функциональность для организации, маркировки и доступа к таким данным, хранимым на диске. Это также обеспечивает инструменты, чтобы упростить генерацию данных из моделей Simulink для прогнозирующей разработки алгоритмов обслуживания. Для получения дополнительной информации смотрите Ансамбли Данных для Мониторинга состояния и Прогнозирующего Обслуживания.
Предварительная обработка данных часто необходима, чтобы преобразовать данные в форму, от которой легко извлечены индикаторы состояния. Предварительная обработка данных включает простые методы, такие как выброс и удаление отсутствующего значения и усовершенствованные методы обработки сигналов, такие как кратковременные преобразования Фурье и преобразования к области порядка.
Понимание вашей машины и вида данных, которые вы имеете, может помочь определить что, предварительно обработав методы, чтобы использовать. Например, если вы фильтруете шумные данные о вибрации, зная то, что, скорее всего, отобразит частотный диапазон, полезные функции могут помочь вам выбрать методы предварительной обработки. Точно так же может быть полезно преобразовать данные о вибрации коробки передач к области порядка, которая используется для вращения машин, когда скорость вращения изменяется в зависимости от времени. Однако та же самая предварительная обработка не была бы полезна для данных о вибрации из автомобильного шасси, которое является твердым телом.
Для получения дополнительной информации о предварительной обработке данных для прогнозирующих алгоритмов обслуживания смотрите, что Данные Предварительно обрабатывают для Мониторинга состояния и Прогнозирующего Обслуживания.
Ключевой шаг в прогнозирующей разработке алгоритмов обслуживания идентифицирует индикаторы состояния, функции в ваших системных данных, изменения поведения которых предсказуемым способом, когда система ухудшает. Индикатор состояния может быть любой функцией, которая полезна для различения нормального от дефектной операции или для предсказания остающегося срока полезного использования. Полезное состояние аналогичной системы кластеров индикатора состояния вместе, и отделяет различное состояние. Примеры индикаторов состояния включают количества, выведенные от:
Простой анализ, такой как среднее значение данных в зависимости от времени
Более комплексный анализ сигнала, такой как частота пикового значения в спектре сигнала или статистическое описание момента изменяется в спектре в зависимости от времени
Основанный на модели анализ данных, таких как максимальное собственное значение модели в пространстве состояний, которая была оценена с помощью данных
Комбинация нескольких функций в один эффективный индикатор состояния (сплав)
Например, можно контролировать условие коробки передач с помощью данных о вибрации. Повредите к результатам коробки передач в изменениях в частоте и значении колебаний. Пиковая частота и пиковое значение являются таким образом полезными индикаторами состояния, предоставляя информацию о виде колебаний, существующих в коробке передач. Чтобы контролировать здоровье коробки передач, можно постоянно анализировать данные о вибрации в частотном диапазоне, чтобы извлечь эти индикаторы состояния.
Даже когда у вас есть действительные или моделируемые данные, представляющие область значений условий отказа, вы не можете знать, как анализировать те данные, чтобы идентифицировать полезные индикаторы состояния. Правильные индикаторы состояния для вашего приложения зависят от того, какую систему, системные данные и системное знание вы имеете. Поэтому идентификация индикаторов состояния может потребовать некоторого метода проб и ошибок и является часто итеративной с учебным шагом рабочего процесса разработки алгоритмов. Среди методов, обычно используемых для извлечения индикаторов состояния:
Закажите анализ
Модальный анализ
Анализ спектра
Спектр конверта
Анализ усталости
Нелинейный анализ timeseries
Основанный на модели анализ, такой как остаточное вычисление, оценка состояния и оценка параметра
Predictive Maintenance Toolbox добавляет функциональность в других тулбоксах, таких как Signal Processing Toolbox™ с функциями для извлечения основанных на сигнале или основанных на модели индикаторов состояния от измеренных или сгенерированных данных. Для получения дополнительной информации смотрите, Идентифицируют Индикаторы состояния.
В основе прогнозирующего обслуживания алгоритм является моделью прогноза или обнаружением. Эта модель анализирует извлеченные индикаторы состояния, чтобы определить текущее положение системы (обнаружение отказа и диагноз) или предсказать его будущее условие (остающийся прогноз срока полезного использования).
Обнаружение отказа и диагноз полагаются на использование одного или нескольких значений индикатора состояния, чтобы различать здоровую и дефектную операцию, и различные типы отказов. Простая модель обнаружения отказа является пороговым значением для индикатора состояния, который показателен из условия отказа, когда превышено. Другая сила модели сравнивает индикатор состояния со статистическим распределением значений индикатора, чтобы определить вероятность конкретного состояния отказа. Более комплексный подход диагностики отказа должен обучить классификатор, который сравнивает текущее значение одного или нескольких индикаторов состояния к значениям, сопоставленным с состояниями отказа, и возвращает вероятность, которая один или другое состояние отказа присутствует.
При разработке прогнозирующего алгоритма обслуживания вы можете протестировать различное обнаружение отказа и модели диагноза с помощью различных индикаторов состояния. Таким образом этот шаг в процессе проектирования является, вероятно, итеративным с шагом индикаторов состояния экстракции, когда вы пробуете различные индикаторы, различные комбинации индикаторов и различные модели выбора решения. Statistics and Machine Learning Toolbox™ и другие тулбоксы включают функциональность, которую можно использовать, чтобы обучить модели выбора решения, такие как модели регрессии и классификаторы. Для получения дополнительной информации смотрите Модели выбора решения для Обнаружения Отказа и Диагноза.
Примеры моделей прогноза включают:
Модель, которая соответствует эволюции времени индикатора состояния и предсказывает, какой длины это будет перед индикатором состояния, пересекает некоторое пороговое значение, показательное из условия отказа.
Модель, которая сравнивает эволюцию времени индикатора состояния к измеренным или моделируемым временным рядам от систем, которые запустились к отказу. Такая модель может вычислить наиболее вероятное время к отказу существующей системы.
Можно предсказать остающийся срок полезного использования путем прогнозирования с моделями динамической системы или утвердить средства оценки. Кроме того, Predictive Maintenance Toolbox включает специализированную функциональность для прогноза RUL на основе таких методов как подобие, порог и анализ выживания. Для получения дополнительной информации см. Модели для Предсказания Остающегося Срока полезного использования.
Когда вы идентифицировали рабочий алгоритм для обработки ваших новых системных данных, обработки его соответственно, и генерации прогноза, развертываете алгоритм и интегрируете его в вашу систему. Базирующийся специфические особенности вашей системы, можно развернуть алгоритм на облаке или на встроенных устройствах.
Внедрение облака может быть полезным, когда вы собираете и храните большие объемы данных по облаку. Устранение необходимости передать данные между облаком и локальными машинами, которые запускают предзнаменования и медицинский контрольный алгоритм, делает процесс обслуживания более эффективным. Результаты, вычисленные на облако, могут быть сделаны доступными через твиты, уведомления по электронной почте, веб-приложения и инструментальные панели.
Также алгоритм может работать на встроенных устройствах, которые ближе к фактическому оборудованию. Основные преимущества выполнения этого - то, что отправленный объем информации уменьшается, когда данные передаются только при необходимости, и обновления и уведомления о здоровье оборудования сразу доступны без любой задержки..
Третья опция должна использовать комбинацию двух. Части предварительной обработки и выделения признаков алгоритма могут быть запущены на встроенных устройствах, в то время как прогнозирующая модель может работать на облаке и сгенерировать уведомления по мере необходимости. В системах, таких как нефтяные развертки и авиационные двигатели, которые запускаются постоянно и генерируют огромные объемы данных, храня все данные на борту или передавая его, не всегда жизнеспособно из-за сотовой пропускной способности и ограничений стоимости. Используя алгоритм, который работает с потоковой передачей данных или с пакетами данных, позволяет вам сохранить и отправить данные только при необходимости.
Генерация кода MathWorks® и продукты развертывания могут помочь вам с этим шагом рабочего процесса. Для получения дополнительной информации смотрите, Развертывают Прогнозирующие Алгоритмы Обслуживания.
[1] Изерманн, R. Системы диагностики отказа: введение от обнаружения отказа до отказоустойчивости. Берлин: Springer Verlag, 2006.
