Найдите локальные максимумы
pks = findpeaks(data)[pks,locs] = findpeaks(data)[pks,locs,w,p]
= findpeaks(data)[___] = findpeaks(data,x)[___] = findpeaks(data,Fs)[___] = findpeaks(___,Name,Value)findpeaks(___)pks = findpeaks(data)data. Локальный пик является выборкой данных, которая или больше, чем ее две соседних выборки или равна Inf. Конечные точки сигнала Non-Inf исключены. Если пик является плоским, функция возвращает только точку с самым низким индексом.
[___] = findpeaks(___, задает аргументы пары "имя-значение" использования опций в дополнение к любому из входных параметров в предыдущих синтаксисах.Name,Value)
findpeaks(___) без выходных аргументов строит сигнал и накладывает пиковые значения.
Задайте вектор с тремя peaks и постройте его.
data = [25 8 15 5 6 10 10 3 1 20 7]; plot(data)

Найдите локальные максимумы. Peaks выводится в порядке вхождения. Первая выборка не включена несмотря на то, чтобы быть максимумом. Для плоского пика функция возвращает только точку с самым низким индексом.
pks = findpeaks(data)
pks = 1×3
15 10 20
Используйте findpeaks без выходных аргументов, чтобы отобразить peaks.
findpeaks(data)

Создайте сигнал, который состоит из суммы кривых нормального распределения. Задайте местоположение, высоту и ширину каждой кривой.
x = linspace(0,1,1000); Pos = [1 2 3 5 7 8]/10; Hgt = [3 4 4 2 2 3]; Wdt = [2 6 3 3 4 6]/100; for n = 1:length(Pos) Gauss(n,:) = Hgt(n)*exp(-((x - Pos(n))/Wdt(n)).^2); end PeakSig = sum(Gauss);
Постройте отдельные кривые и их сумму.
plot(x,Gauss,'--',x,PeakSig)
Используйте findpeaks с настройками по умолчанию, чтобы найти peaks сигнала и их местоположений.
[pks,locs] = findpeaks(PeakSig,x);
Постройте peaks с помощью findpeaks и маркируйте их.
findpeaks(PeakSig,x) text(locs+.02,pks,num2str((1:numel(pks))'))

Сортировка peaks от самого высокого до самого короткого.
[psor,lsor] = findpeaks(PeakSig,x,'SortStr','descend'); findpeaks(PeakSig,x) text(lsor+.02,psor,num2str((1:numel(psor))'))

Создайте сигнал, который состоит из суммы кривых нормального распределения, едущих на полном периоде косинуса. Задайте местоположение, высоту и ширину каждой кривой.
x = linspace(0,1,1000); base = 4*cos(2*pi*x); Pos = [1 2 3 5 7 8]/10; Hgt = [3 7 5 5 4 5]; Wdt = [1 3 3 4 2 3]/100; for n = 1:length(Pos) Gauss(n,:) = Hgt(n)*exp(-((x - Pos(n))/Wdt(n)).^2); end PeakSig = sum(Gauss)+base;
Постройте отдельные кривые и их сумму.
plot(x,Gauss,'--',x,PeakSig,x,base)
Используйте findpeaks, чтобы определить местоположение и построить peaks, который имеет выдающееся положение по крайней мере 4.
findpeaks(PeakSig,x,'MinPeakProminence',4,'Annotate','extents')

Самый высокий и самый низкий peaks является единственными единицами, которые удовлетворяют условие.
Отобразите выдающиеся положения и ширины в половине выдающегося положения всего peaks.
[pks,locs,widths,proms] = findpeaks(PeakSig,x); widths
widths = 1×6
0.0154 0.0431 0.0377 0.0625 0.0274 0.0409
proms
proms = 1×6
2.6816 5.5773 3.1448 4.4171 2.9191 3.6363
Солнечные пятна являются циклическим явлением. Их номер, как известно, достигает максимума примерно каждые 11 лет.
Загрузите файл sunspot.dat, который содержит среднее количество солнечных пятен, наблюдаемых каждый год от 1 700 до 1987. Найдите и постройте максимумы.
load sunspot.dat
year = sunspot(:,1);
avSpots = sunspot(:,2);
findpeaks(avSpots,year)
Улучшите свою оценку длительности цикла путем игнорирования peaks, который является очень друг близко к другу. Найдите и постройте peaks снова, но теперь ограничьте приемлемые разделения от пика к пику значениями, больше, чем шесть лет.
findpeaks(avSpots,year,'MinPeakDistance',6)
Используйте пиковые местоположения, возвращенные findpeaks, чтобы вычислить средний интервал между максимумами.
[pks,locs] = findpeaks(avSpots,year,'MinPeakDistance',6);
meanCycle = mean(diff(locs))meanCycle = 10.9600
Создайте массив datetime с помощью данных года. Примите, что солнечные пятна считались каждый год 20-го марта, близко к весеннему равноденствию. Найдите пиковые годы солнечного пятна. Используйте функцию years, чтобы задать минимальное пиковое разделение как duration.
ty = datetime(year,3,20); [pk,lk] = findpeaks(avSpots,ty,'MinPeakDistance',years(6)); plot(ty,avSpots,lk,pk,'o')

Вычислите средний цикл солнечной активности с помощью функциональности datetime.
dttmCycle = years(mean(diff(lk)))
dttmCycle = 10.9600
Создайте расписание с данными. Задайте переменную времени в годах. Отобразите данные на графике. Покажите последние пять записей расписания.
TT = timetable(years(year),avSpots); plot(TT.Time,TT.Variables)

entries = TT(end-4:end,:)
entries=5×2 timetable
Time avSpots
________ _______
1983 yrs 66.6
1984 yrs 45.9
1985 yrs 17.9
1986 yrs 13.4
1987 yrs 29.3
Загрузите звуковой сигнал, выбранный на уровне 7 418 Гц. Выберите 200 выборок.
load mtlb
select = mtlb(1001:1200);Найдите peaks, который разделяется по крайней мере на 5 мс.
Чтобы применить это ограничение, findpeaks выбирает самый высокий пик в сигнале и устраняет весь peaks в 5 мс из него. Функция затем повторяет процедуру для самого высокого остающегося пика и выполняет итерации, пока это не исчерпывает peaks, чтобы рассмотреть.
findpeaks(select,Fs,'MinPeakDistance',0.005)
Найдите peaks, который имеет амплитуду по крайней мере 1 В.
findpeaks(select,Fs,'MinPeakHeight',1)
Найдите peaks, который на по крайней мере 1 В выше, чем их соседние выборки.
findpeaks(select,Fs,'Threshold',1)
Найдите peaks, который понижается по крайней мере на 1 В с обеих сторон, прежде чем сигнал достигает более высокого значения.
findpeaks(select,Fs,'MinPeakProminence',1)
Датчики могут возвратить отсеченные показания, если данные больше, чем данная точка насыщения. Можно принять решение игнорировать этот peaks как бессмысленный или включить их к анализу.
Сгенерируйте сигнал, который состоит из продукта тригонометрических функций частот 5 Гц и 3 Гц, встроенные в белый Гауссов шум отклонения 0,1 ². Сигнал выбирается в течение одной секунды на уровне 100 Гц. Сбросьте генератор случайных чисел для восстанавливаемых результатов.
rng default
fs = 1e2;
t = 0:1/fs:1-1/fs;
s = sin(2*pi*5*t).*sin(2*pi*3*t)+randn(size(t))/10;Моделируйте влажное измерение путем усечения каждого чтения, которое больше, чем заданное, связанное 0,32. Постройте влажный сигнал.
bnd = 0.32;
s(s>bnd) = bnd;
plot(t,s)
xlabel('Time (s)')
Найдите peaks сигнала. findpeaks сообщает только о возрастающем ребре каждого плоского пика.
[pk,lc] = findpeaks(s,t); hold on plot(lc,pk,'x')

Используйте пару "имя-значение" 'Threshold', чтобы исключить плоский peaks. Потребуйте минимального амплитудного различия между пиком и его соседями.
[pkt,lct] = findpeaks(s,t,'Threshold',1e-4); plot(lct,pkt,'o','MarkerSize',12)

Создайте сигнал, который состоит из суммы кривых нормального распределения. Задайте местоположение, высоту и ширину каждой кривой.
x = linspace(0,1,1000); Pos = [1 2 3 5 7 8]/10; Hgt = [4 4 2 2 2 3]; Wdt = [3 8 4 3 4 6]/100; for n = 1:length(Pos) Gauss(n,:) = Hgt(n)*exp(-((x - Pos(n))/Wdt(n)).^2); end PeakSig = sum(Gauss);
Постройте отдельные кривые и их сумму.
plot(x,Gauss,'--',x,PeakSig)
grid
Измерьте ширины peaks с помощью половины выдающегося положения в качестве ссылки.
findpeaks(PeakSig,x,'Annotate','extents')

Измерьте ширины снова, на этот раз с помощью половины высоты в качестве ссылки.
findpeaks(PeakSig,x,'Annotate','extents','WidthReference','halfheight') title('Signal Peak Widths')

Выдающееся положение пика измеряется, насколько пик выделяется из-за его внутренней высоты и его местоположения относительно другого peaks. Низкий изолированный пик может быть более видным, чем тот, который выше, но является в противном случае обыкновенным членом высокой области значений.
Измерять выдающееся положение пика:
Поместите маркер в пик.
Расширьте горизонтальную строку от пика налево и прямо пока строка не выполнит одно из следующих действий:
Пересекает сигнал, потому что существует более высокий пик
Достигает левого или правого конца сигнала
Найдите минимум сигнала в каждом из этих двух интервалов заданным на Шаге 2. Эта точка является или долиной или одной из конечных точек сигнала.
Выше двух минимумов интервала задает контрольный уровень. Высота пика выше этого уровня является своим выдающимся положением.
findpeaks не делает предположения о поведении сигнала вне его конечных точек, безотносительно их высоты. Это отражается на Шагах 2 и 4 и часто влияет на значение контрольного уровня. Рассмотрите, например, peaks этого сигнала:
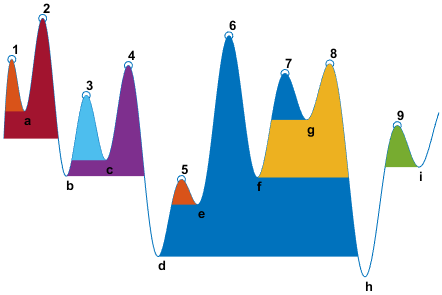
| Пиковый номер | Оставленный интервал находится между пиком и | Правильный интервал находится между пиком и | Самая низкая точка на левом интервале | Самая низкая точка на правильном интервале | Контрольный уровень (самый высокий минимум) |
|---|---|---|---|---|---|
| 1 | Оставленный конец | Пересечение должного достигнуть максимума 2 | Оставленная конечная точка | a | a |
| 2 | Оставленный конец | Правильный конец | Оставленная конечная точка | h | Оставленная конечная точка |
| 3 | Пересечение должного достигнуть максимума 2 | Пересечение должного достигнуть максимума 4 | b | c | c |
| 4 | Пересечение должного достигнуть максимума 2 | Пересечение должного достигнуть максимума 6 | b | d | b |
| 5 | Пересечение должного достигнуть максимума 4 | Пересечение должного достигнуть максимума 6 | d | e | e |
| 6 | Пересечение должного достигнуть максимума 2 | Правильный конец | d | h | d |
| 7 | Пересечение должного достигнуть максимума 6 | Пересечение должного достигнуть максимума 8 | f | g | g |
| 8 | Пересечение должного достигнуть максимума 6 | Правильный конец | f | h | f |
| 9 | Пересечение должного достигнуть максимума 8 | Пересечение из-за правильной конечной точки | h | i | i |
fminbnd | fminsearch | fzero | islocalmax | islocalmin | max
