После учебных классификаторов в Classification Learner можно сравнить модели на основе очков точности, визуализировать результаты путем графического вывода прогнозов класса и проверять производительность с помощью матрицы беспорядка и кривой ROC.
Если вы используете перекрестную проверку k-сгиба, то приложение вычисляет очки точности с помощью наблюдений в k валидации, сворачивает и сообщает о средней ошибке перекрестной проверки. Это также делает прогнозы на наблюдениях в этих, валидация сворачивает и вычисляет матрицу беспорядка и кривую ROC на основе этих прогнозов.
Когда вы импортируете данные в приложение, если вы принимаете значения по умолчанию, приложение автоматически использует перекрестную проверку. Чтобы узнать больше, смотрите, Выбирают Validation Scheme.
Если вы используете валидацию затяжки, приложение вычисляет очки точности с помощью наблюдений в сгибе валидации и делает прогнозы на этих наблюдениях. Приложение также вычисляет матрицу беспорядка и кривую ROC на основе этих прогнозов.
Если вы принимаете решение не использовать схему валидации, счет является точностью перезамены на основе всех данных тренировки, и прогнозы являются прогнозами перезамены.
После обучения модель в Classification Learner проверяйте Список предыстории, чтобы видеть, какая модель имеет лучшую общую точность в проценте. Лучший счет Accuracy подсвечен в поле. Этот счет является точностью валидации (если вы не выбрали схему валидации). Счет точности валидации оценивает производительность модели на новых данных по сравнению с данными тренировки. Используйте счет, чтобы помочь вам выбрать лучшую модель.
Для перекрестной проверки счет является точностью на всех наблюдениях, считая каждое наблюдение, когда это было в протянутом сгибе.
Для валидации затяжки счет является точностью на протянутых наблюдениях.
Ни для какой валидации счет является точностью перезамены против всех наблюдений данных тренировки.
Лучшая общая оценка не может быть лучшей моделью для вашей цели. Модель с немного более низкой общей точностью может быть лучшим классификатором для вашей цели. Например, ложные положительные стороны в конкретном классе могут быть важны для вас. Вы можете хотеть исключить некоторые предикторы, где сбор данных является дорогим или трудным.
Чтобы узнать как классификатор, выполняемый в каждом классе, исследуйте матрицу беспорядка.
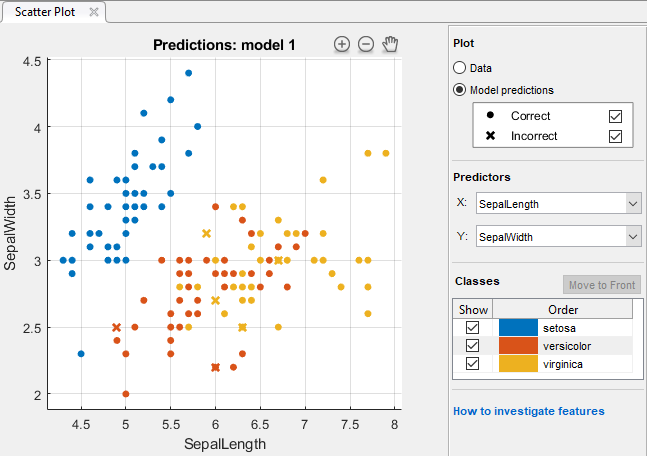
В графике рассеивания просмотрите результаты классификатора. После того, как вы обучаете классификатор, переключатели графика рассеивания от отображения данных к показу образцовых прогнозов. Если вы используете затяжку или перекрестную проверку, то эти прогнозы являются прогнозами на протянутых наблюдениях. Другими словами, каждый прогноз получен с помощью модели, которая была обучена, не используя соответствующее наблюдение. Чтобы исследовать ваши результаты, используйте средства управления справа. Вы можете:
Выберите, построить ли образцовые прогнозы или одни только данные.
Покажите или скройте правильные или неправильные результаты с помощью флажков под Model predictions.
Выберите функции, чтобы построить использование X и списков Y под Predictors.
Визуализируйте результаты классом путем показа или сокрытия определенных классов с помощью флажков под Show.
Измените порядок размещения нанесенных на график классов путем выбора класса под Classes и затем нажатия на Move to Front.
Увеличьте и уменьшите масштаб, или панорамирование через график. Чтобы позволить масштабировать и панорамировать, наведите мышь на график рассеивания и нажмите одну из кнопок, которые появляются около верхнего правого угла графика.
См. также Исследуют Функции в Графике поля точек.
Чтобы экспортировать графики рассеивания, вы создаете в приложении фигурам, видите Графики Экспорта в Приложении Classification Learner.
Используйте матричный график беспорядка понять, как в настоящее время выбранный классификатор выполнил в каждом классе. Чтобы просмотреть матрицу беспорядка после обучения модель, на вкладке Classification Learner, в разделе Plots, нажимают Confusion Matrix. Матрица беспорядка помогает вам идентифицировать области, где классификатор выполнил плохо.
Когда вы открываете график, строки показывают истинный класс, и столбцы показывают предсказанный класс. Если вы используете затяжку или перекрестную проверку, то матрица беспорядка вычисляется с помощью прогнозов на протянутых наблюдениях. Диагональные ячейки показывают, где истинный класс и предсказал соответствие класса. Если эти ячейки являются зелеными, классификатор выполнил хорошо и классифицировал наблюдения за этим истинным классом правильно.
Представление по умолчанию показывает количество наблюдений в каждой ячейке.
Чтобы видеть, как классификатор, выполняемый в классе, под Plot, выбирает True Positive Rates, опцию False Negative Rates. График показывает сводные данные в истинном классе в последних двух столбцах справа.
Ищите области, где классификатор выполнил плохо путем исследования ячеек от диагонали, которые отображают высокие проценты и являются красными. Чем выше процент, тем более яркий оттенок цвета ячейки. В этих эритроцитах не соответствуют истинный класс и предсказанный класс. Точки данных неправильно классифицируются.
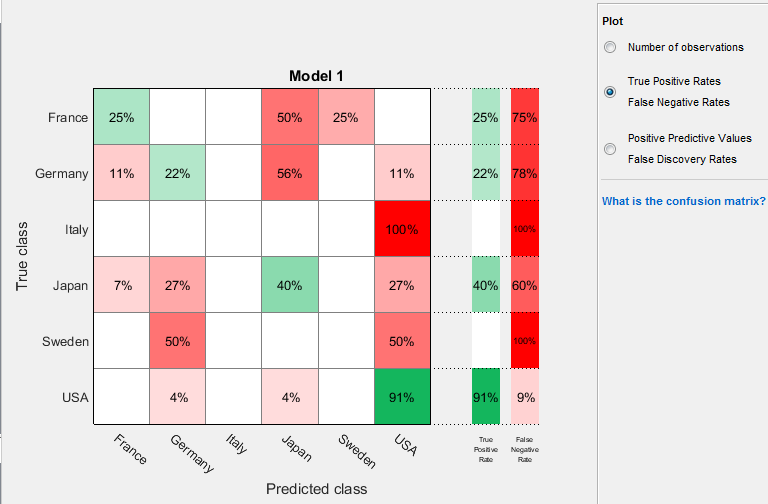
В этом примере, с помощью набора данных carsmall, верхняя строка показывает все автомобили с истинным классом Франция. Столбцы показывают предсказанные классы. В верхней строке правильно классифицируются 25% автомобилей из Франции, таким образом, 25% является истинным положительным уровнем для правильно классифицированных точек в этом классе, показанном в зеленой ячейке в столбце True Positive Rate.
Другие автомобили в строке Франции неправильно классифицируются: 50% автомобилей неправильно классифицируются как из Японии, и 25% классифицируются как из Швеции. 75% является ложным отрицательным уровнем для неправильно классифицированных точек в этом классе, показанном в эритроците в столбце False Negative Rate.
Если вы хотите видеть, что количества наблюдений (автомобили, в этом примере) вместо процентов, под Plot, выбирают Number of observations.
Если ложные положительные стороны важны в вашей проблеме классификации, строят результаты в предсказанном классе (вместо истинного класса), чтобы исследовать ложные уровни открытия. Чтобы видеть результаты в предсказанном классе, под Plot, выбирают опцию False Discovery Rates Positive Predictive Values. Матрица беспорядка теперь показывает сводные строки под таблицей. Положительные прогнозирующие значения отображают зеленым для правильно предсказанных точек в каждом классе, и ложные уровни открытия показывают ниже его в красном для неправильно предсказанных точек в каждом классе.
Если вы решаете, что существует слишком много неправильно классифицированных точек в классах интереса, пытаются изменить настройки классификатора или показывают выбор, чтобы искать лучшую модель.
Чтобы экспортировать матричные графики беспорядка, вы создаете в приложении фигурам, видите Графики Экспорта в Приложении Classification Learner.
Чтобы просмотреть кривую ROC после обучения модель, на вкладке Classification Learner, в разделе Plots, нажимают ROC Curve. Просмотрите истину и ложь показа кривой рабочей характеристики получателя (ROC) положительные уровни. Кривая ROC показывает истинный положительный уровень по сравнению с ложным положительным уровнем для в настоящее время выбранного обученного классификатора. Можно выбрать различные классы, чтобы построить.
Маркер на графике показывает производительность в настоящее время выбранного классификатора. Маркер показывает значения ложного положительного уровня (FPR) и истинного положительного уровня (TPR) для в настоящее время выбранного классификатора. Например, ложный положительный уровень (FPR) 0,2 указывает, что текущий классификатор присваивает 20% наблюдений неправильно к положительному классу. Истинный положительный уровень 0,9 указывает, что текущий классификатор присваивает 90% наблюдений правильно к положительному классу.
Совершенным результатом без неправильно классифицированных точек является прямой угол к левому верхнему из графика. Плохим результатом, который является не лучше, чем случайный, является строка в 45 градусах. Номер Area Under Curve является мерой общего качества классификатора. Большие значения Area Under Curve указывают на лучшую производительность классификатора. Сравните классы и обученные модели, чтобы видеть, выполняют ли они по-другому в кривой ROC.
Для получения дополнительной информации смотрите perfcurve.
Чтобы экспортировать ROC изгибают графики, которые вы создаете в приложении фигурам, видите Графики Экспорта в Приложении Classification Learner.
