В Classification Learner попытайтесь идентифицировать предикторы, которые разделяют классы хорошо путем графического вывода различных пар предикторов на графике рассеивания. График может помочь вам исследовать функции, чтобы включать или исключить. Можно визуализировать данные тренировки и неправильно классифицированные точки на графике рассеивания.
Прежде чем вы обучите классификатор, график рассеивания показывает данные. Если вы обучили классификатор, график рассеивания показывает образцовые результаты прогноза. Переключитесь на отображение на графике только данных путем выбора Data в средствах управления Plot.
Выберите функции, чтобы построить использование X и списков Y под Predictors.
Ищите предикторы, это разделяет классы хорошо. Например, отображая на графике данные fisheriris, вы видите, что длина чашелистика и ширина чашелистика разделяют один из классов хорошо (setosa). Необходимо построить другие предикторы, чтобы видеть, можно ли разделить другие два класса.
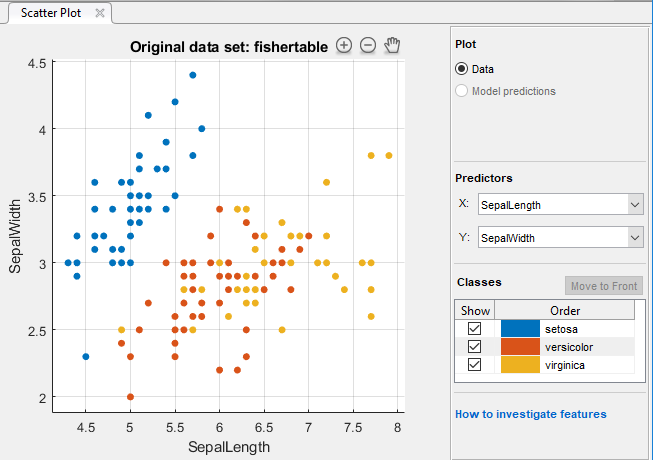
Покажите или скройте определенные классы с помощью флажков под Show.
Измените порядок размещения нанесенных на график классов путем выбора класса под Classes и затем нажатия на Move to Front.
Исследуйте более прекрасные детали путем увеличения и уменьшения масштаба и панорамирования через график. Чтобы позволить масштабировать и панорамировать, наведите мышь на график рассеивания и нажмите одну из кнопок, которые появляются около верхнего правого угла графика.
Если вы идентифицируете предикторы, которые не полезны для выделения классов, то пытаются использовать Feature Selection, чтобы удалить их и классификаторы train только включая самые полезные предикторы.
После того, как вы обучите классификатор, график рассеивания показывает образцовые результаты прогноза. Можно показать или скрыть правильные или неправильные результаты и визуализировать результаты классом. Смотрите Результаты Классификатора Графика.
Можно экспортировать графики рассеивания, которые вы создаете в приложении фигурам. См. Графики Экспорта в Приложении Classification Learner.
В Classification Learner можно задать различные функции (или предикторы), чтобы включать в модель. Смотрите, можно ли улучшить модели путем удаления функций с низкой предсказательной силой. Если сбор данных является дорогим или трудным, вы можете предпочесть модель, которая выполняет удовлетворительно без некоторых предикторов.
На вкладке Classification Learner, в разделе Features, нажимают Feature Selection.
В окне сорвиголовы Выбора Функции снимите флажки для предикторов, которые вы хотите исключить.
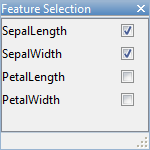
Можно закрыть окно сорвиголовы Выбора Функции или переместить его. Ваш выбор в сорвиголове остается.
Нажмите Train, чтобы обучить новую модель с помощью новых опций предиктора.
Наблюдайте новую модель в Списке предыстории. Панель Текущей модели отображается, сколько предикторов исключено.
Чтобы проверять, какие предикторы включены в обученную модель, кликните по модели в Списке предыстории и наблюдайте флажки в диалоговом окне Feature Selection.
Можно попытаться улучшить модель включением различных функций в модели.
Для примера с помощью выбора функции смотрите, что Деревья решений Train Используют Приложение Classification Learner.
Используйте анализ главных компонентов (PCA), чтобы уменьшать размерность пробела предиктора. Сокращение размерности может создать модели классификации в Classification Learner, что справка предотвращает сверхподбор кривой. PCA линейно преобразовывает предикторы в порядок удалить избыточные размерности и генерирует новый набор названных основных компонентов переменных.
На вкладке Classification Learner, в разделе Features, выбирают PCA.
В Усовершенствованном окне сорвиголовы Опций PCA установите флажок Enable PCA.
Можно закрыть окно сорвиголовы PCA или переместить его. Ваш выбор в сорвиголове остается.
Когда вы затем нажимаете Train, функция pca преобразовывает ваши выбранные функции перед обучением классификатор.
По умолчанию PCA сохраняет только компоненты, которые объясняют 95% отклонения. В окне сорвиголовы PCA можно изменить процент отклонения, чтобы объяснить в поле Explained variance. Более высокое значение рискует сверхсоответствовать, в то время как нижнее значение рискует удалять полезные размерности.
Если вы хотите вручную ограничить количество компонентов PCA в списке Component reduction criterion, выберите Specify number of components. Отредактируйте номер в поле Number of numeric components. Количество компонентов не может быть больше, чем количество числовых предикторов. PCA не применяется к категориальным предикторам.
Проверяйте опции PCA на обученные модели в информации о панели Текущей модели. Проверяйте объясненные проценты отклонения, чтобы решить, изменить ли количество компонентов. Например:
PCA is keeping enough components to explain 95% variance. After training, 2 components were kept. Explained variance per component (in order): 92.5%, 5.3%, 1.7%, 0.5%
Чтобы узнать больше, как Classification Learner применяет PCA к вашим данным, сгенерируйте код для своего обученного классификатора. Для получения дополнительной информации о PCA смотрите, что pca функционирует.
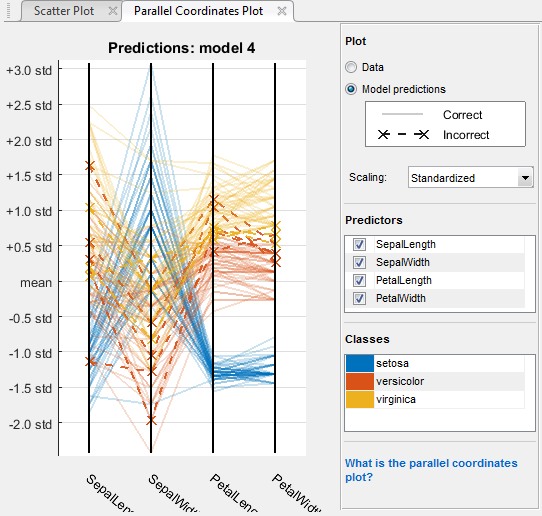
Чтобы исследовать функции, чтобы включать или исключить, используйте параллельный график координат. Можно визуализировать высокие размерные данные по одному графику видеть 2D шаблоны. Этот график может помочь вам понять отношения между функциями и идентифицировать полезные предикторы для разделения классов. Можно визуализировать данные тренировки и неправильно классифицированные точки на параллельном графике координат. Когда вы строите результаты классификатора, неправильно классифицированные точки показывают пунктирные линии.
На вкладке Classification Learner, в разделе Plots, выбирают Parallel Coordinates Plot.
На графике можно перетащить панели, чтобы переупорядочить предикторы. Изменение порядка может помочь вам идентифицировать предикторы, это разделяет классы хорошо.
Чтобы задать который предикторы построить, используйте флажки Predictors. Может быть полезно построить несколько предикторов за один раз. Если ваши данные имеют много предикторов, график показывает первые 10 по умолчанию.
Если предикторы имеют совсем другие шкалы, масштабируют данные, чтобы облегчить визуализировать. Попробуйте различные варианты в списке Scaling:
Normalization строит все предикторы на том же диапазоне от 0 до 1.
Standardization строит среднее значение каждого предиктора в нуле и масштабирует предикторы их стандартными отклонениями.
Если вы идентифицируете предикторы, которые не полезны для выделения классов, используют Feature Selection, чтобы удалить их и классификаторы train только включая самые полезные предикторы.
Отображая на графике данные fisheriris, вы видите, что лепестковая длина и лепестковая ширина являются функциями, которые разделяют классы лучше всего.
Можно экспортировать параллельные графики координат, которые вы создаете в приложении фигурам. См. Графики Экспорта в Приложении Classification Learner.
