Этот пример показывает, как протестировать на существенные различия между категорией средние значения (группы) использовать t - тест, двухсторонняя АНОВА (дисперсионный анализ) и АНОКОВА (ковариационный анализ) анализ.
Цель определяет, зависят ли ожидаемые мили на галлон для автомобиля от десятилетия, в которое это было произведено, или местоположение, где это было произведено.
nominal и типы данных массива ordinal могут быть удалены в будущем релизе. Чтобы представлять упорядоченный и неупорядоченные дискретные, нечисловые данные, используйте Категориальные массивы (MATLAB) тип данных вместо этого.
Отобразите на графике данные, сгруппированные по категориям.
Проведите 2D демонстрационный t-тест для равных средних значений группы.
load('carsmall')
unique(Model_Year)ans =
70
76
82Переменная MPG имеет мили на измерения галлона на выборке 100 автомобилей. Переменные Model_Year и Origin содержат модельный год и страну происхождения для каждого автомобиля.
Первым фактором интереса является десятилетие изготовления. В данных существует три производственных года.
Создайте порядковый массив под названием Decade путем слияния наблюдений с лет, которые 70 и 76 в категорию маркировали 1970s, и помещение наблюдений от 82 в категорию маркировало 1980s.
Decade = ordinal(Model_Year,{'1970s','1980s'},[],[70 77 82]);
getlevels(Decade)ans =
1970s 1980s Чертите диаграмму миль на галлон, сгруппированный десятилетием изготовления.
figure()
boxplot(MPG,Decade)
title('Miles per Gallon, Grouped by Decade of Manufacture')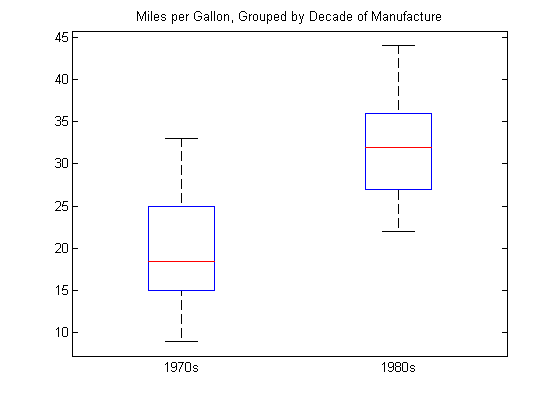
Диаграмма предполагает, что мили на галлон выше в автомобилях, произведенных в течение 1980-х по сравнению с 1970-ми.
Вычислите среднее значение и отклонение миль на галлон в течение каждого десятилетия.
[xbar,s2,grp] = grpstats(MPG,Decade,{'mean','var','gname'})xbar =
19.7857
31.7097
s2 =
35.1429
29.0796
grp =
'1970s'
'1980s'Этот вывод показывает, что средними милями на галлон в 1980-х был 31.71, по сравнению с 19.79 в 1970-х. Отклонения в этих двух группах подобны.
Проведите 2D демонстрационный t - тест, приняв равные отклонения, чтобы протестировать на значительную разницу между средними значениями группы. Гипотеза
MPG70 = MPG(Decade=='1970s'); MPG80 = MPG(Decade=='1980s'); [h,p] = ttest2(MPG70,MPG80)
h =
1
p =
3.4809e-151 указывает на нулевую гипотезу, отклоняется в значении по умолчанию 0,05 уровня значения. P-значение для теста является очень маленьким. Существуют достаточные доказательства, что средние мили на галлон в 1980-х отличаются от средних миль на галлон в 1970-х.Вторым фактором интереса является местоположение изготовления. Во-первых, преобразуйте Origin в номинальный массив.
Location = nominal(Origin); tabulate(Location)
tabulate(Location)
Value Count Percent
France 4 4.00%
Germany 9 9.00%
Italy 1 1.00%
Japan 15 15.00%
Sweden 2 2.00%
USA 69 69.00%Объедините категории France, Germany, Italy и Sweden в новую категорию под названием Europe.
Location = mergelevels(Location, ... {'France','Germany','Italy','Sweden'},'Europe'); tabulate(Location)
Value Count Percent
Japan 15 15.00%
USA 69 69.00%
Europe 16 16.00%Вычислите средние мили на галлон, сгруппированный местоположением изготовления.
[xbar,grp] = grpstats(MPG,Location,{'mean','gname'})xbar =
31.8000
21.1328
26.6667
grp =
'Japan'
'USA'
'Europe'Этот результат показывает, что средние мили на галлон являются самыми низкими для выборки автомобилей, произведенных в США.
Проведите двухстороннюю АНОВУ, чтобы протестировать на различия в ожидаемых милях на галлон между факторными уровнями для Decade и Location.
Статистическая модель
где MPGij является ответом, милями на галлон, для автомобилей, сделанных в десятилетие i в местоположении j. Эффекты обработки для первого фактора, десятилетие изготовления, являются условиями αi (ограниченный суммировать, чтобы обнулить). Эффекты обработки для второго фактора, местоположения изготовления, являются условиями βj (ограниченный суммировать, чтобы обнулить). εij является некоррелироваными, нормально распределенными шумовыми условиями.
Гипотезы, чтобы протестировать являются равенством эффектов десятилетия,
и равенство эффектов местоположения,
Можно провести несколько - фактор АНОВА, использующая anovan.
anovan(MPG,{Decade,Location},'varnames',{'Decade','Location'});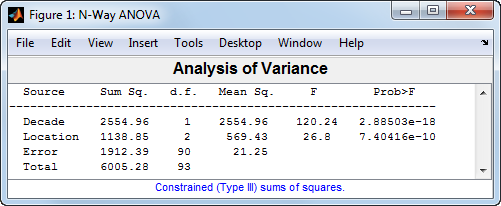
Этот вывод показывает результаты двухсторонней АНОВОЙ. P-значением для тестирования равенства эффектов десятилетия является 2.88503e-18, таким образом, нулевая гипотеза отклоняется на 0,05 уровнях значения. P-значением для тестирования равенства эффектов местоположения является 7.40416e-10, таким образом, эта нулевая гипотеза также отклоняется.
Потенциальный нарушитель спокойствия в этом анализе является автомобильным весом. Автомобили с большим весом, как ожидают, будут иметь более низкий расход бензина. Включайте переменную Weight как непрерывный ковариант в АНОВОЙ; то есть, проведите анализ АНОКОВОЙ.
Принимая параллельные строки, статистическая модель
Различием между этой моделью и двухсторонней моделью АНОВОЙ является включение непрерывного предиктора, Weightijk, веса для k th автомобиль, который был сделан в i th десятилетием и в j th местоположение. Наклонным параметром является γ.
Добавьте непрерывный ковариант как третью группу во втором входном параметре anovan. Используйте аргумент пары "имя-значение" Continuous, чтобы указать, что Weight (третья группа) непрерывен.
anovan(MPG,{Decade,Location,Weight},'Continuous',3,...
'varnames',{'Decade','Location','Weight'});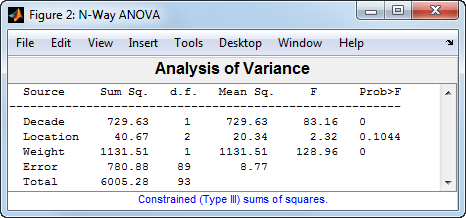
Этот вывод показывает, что, когда автомобильный вес рассматривается, существуют недостаточные доказательства производственного эффекта местоположения (p-значение = 0.1044).
Можно использовать интерактивный aoctool, чтобы исследовать этот результат.
aoctool(Weight,MPG,Location);
Эта команда открывает три диалоговых окна. В диалоговом окне Prediction Plot АНОКОВОЙ выберите модель Separate Means.
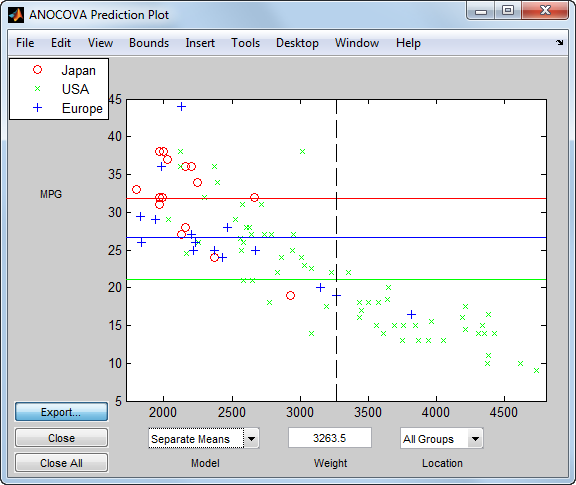
Этот вывод показывает, что, когда вы не включаете Weight в модель, существуют довольно значительные различия в ожидаемых милях на галлон среди трех производственных мест. Обратите внимание на то, что здесь модель не настраивает в течение десятилетия производства.
Теперь, выберите модель Parallel Lines.
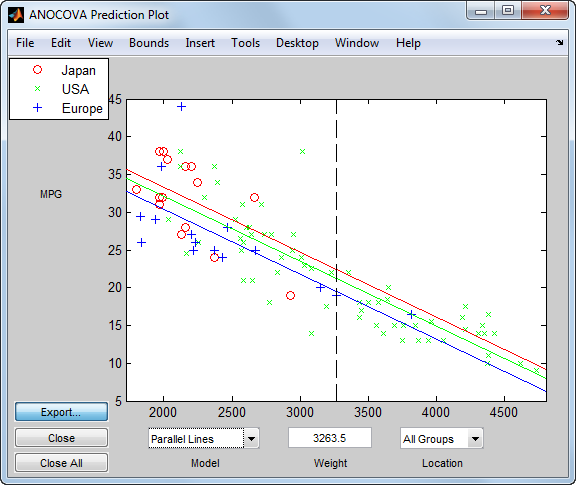
Когда вы включаете Weight в модель, различие в ожидаемых милях на галлон среди трех производственных мест намного меньше.
anovan | aoctool | boxplot | grpstats | nominal | ordinal | ttest2
