После секвенирования части DNA одна из первых задач состоит в том, чтобы исследовать содержимое нуклеотида в последовательности. Начиная с последовательности DNA этот пример использует функции статистики последовательности, чтобы определить моно - di-и trinucleotide содержимое, и определить местоположение открытых рамок считывания.
Следующая процедура иллюстрирует, как использовать Браузер документации MATLAB®, чтобы искать в Интернете информацию. В этом примере вы интересуетесь изучением человеческого митохондриального генома. В то время как много генов, которыми код для митохондриальных белков найден в ядре клетки, митохондриальное, имеют гены, что код для белков раньше производил энергию.
Первая исследовательская информация о человеческих митохондриях и находит последовательность нуклеотида для генома. Затем посмотрите на содержимое нуклеотида для целой последовательности. И наконец, определите открытые рамки считывания и извлеките определенные последовательности генов.
Используйте Браузер документации MATLAB, чтобы исследовать сеть. В Командном Окне MATLAB введите
web('http://www.ncbi.nlm.nih.gov/')
Отдельное окно браузера открывается домашней страницей для веб-сайта NCBI.
Ищите веб-сайт NCBI об информации. Например, чтобы искать человеческий геном митохондрии, из списка Search, выбирают Genome , и в списке Search, введите mitochondrion homo sapiens.

Веб-поиск NCBI возвращает список ссылок на соответствующие страницы.
Выберите страницу результатов. Например, щелкните по ссылке, пометил NC_012920.
Браузер документации MATLAB отображает страницу NCBI для человеческого митохондриального генома.
Следующая процедура иллюстрирует, как найти последовательность нуклеотида в общедоступной базе данных и считать информации последовательности в среду MATLAB. Много общедоступных баз данных для последовательностей нуклеотида доступны с сети. Окно Команды MATLAB обеспечивает интегрированную среду для обеспечения информации о последовательности в среду MATLAB.
Последовательность согласия для человеческого митохондриального генома имеет инвентарный номер GenBank® NC_012920. Поскольку целая запись GenBank является довольно большой, и вы можете только интересоваться последовательностью, можно получить только информацию последовательности.
Получите информацию последовательности от базы данных Web. Например, чтобы получить информацию о последовательности для человеческого митохондриального генома, в Окне Команды MATLAB, типе
mitochondria = getgenbank('NC_012920','SequenceOnly',true)
getgenbank функция получает последовательность нуклеотида из базы данных GenBank и создает символьный массив.
mitochondria = GATCACAGGTCTATCACCCTATTAACCACTCACGGGAGCTCTCCATGCAT TTGGTATTTTCGTCTGGGGGGTGTGCACGCGATAGCATTGCGAGACGCTG GAGCCGGAGCACCCTATGTCGCAGTATCTGTCTTTGATTCCTGCCTCATT CTATTATTTATCGCACCTACGTTCAATATTACAGGCGAACATACCTACTA AAGT . . .
Если у вас нет веб-подключения, можно загрузить данные из файла MAT, включенного с программным обеспечением Bioinformatics Toolbox™, с помощью команды
load mitochondria
load функционируйте загружает последовательность mitochondria в рабочее пространство MATLAB.
Получите информацию о последовательности. Ввод
whos mitochondria
Информация о размере последовательности отображается в Окне Команды MATLAB.
Name Size Bytes Class Attributes mitochondria 1x16569 33138 char
Следующая процедура иллюстрирует, как определить мономеры и димеры, и затем визуализировать данные в графиках и столбиковых диаграммах. Разделы последовательности DNA с высоким процентом нуклеотидов A+T обычно указывают на межгенные части последовательности, в то время как низкий A+T, и выше проценты нуклеотида G+C указывают на возможные гены. Много раз высокое содержимое динуклеотида CG расположено перед геном.
После того, как вы читаете последовательность в среду MATLAB, можно использовать функции статистики последовательности, чтобы определить, имеет ли последовательность характеристики кодирующей белок области. Эта процедура использует человеческий митохондриальный геном в качестве примера. Смотрите информацию Последовательности Чтения из сети.
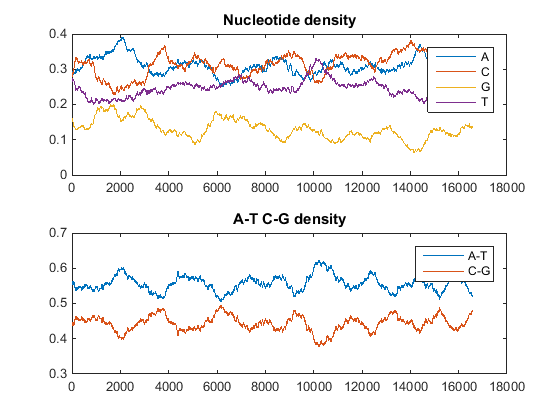
Постройте плотность мономера и объединенную плотность мономера в графике. В Командном Окне MATLAB введите
ntdensity(mitochondria)
Этот график показывает, что геном является богатыми A+T.
Считайте нуклеотиды с помощью basecount функция.
basecount(mitochondria)
Список количеств нуклеотида показывают для 5 '-3' скрутки.
ans =
A: 5124
C: 5181
G: 2169
T: 4094
Считайте нуклеотиды в противоположном дополнении последовательности с помощью seqrcomplement функция.
basecount(seqrcomplement(mitochondria))
Как ожидалось нуклеотид рассчитывает на противоположную дополнительную скрутку, дополнительны к 5 '-3' скрутки.
ans =
A: 4094
C: 2169
G: 5181
T: 5124
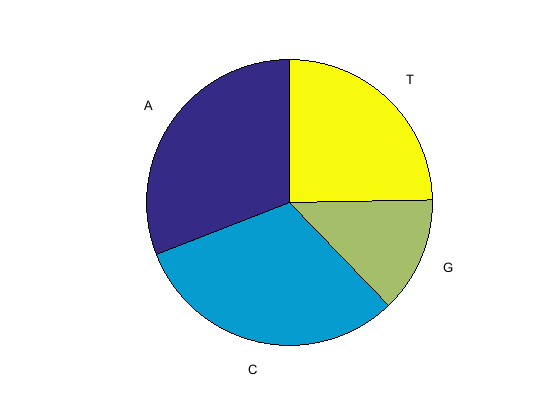
Используйте функциональный basecount с chart опция, чтобы визуализировать распределение нуклеотида.
figure basecount(mitochondria,'chart','pie');
Круговая диаграмма отображается в окне MATLAB Figure.
Считайте димеры в последовательности и отобразите информацию в столбчатой диаграмме.
figure dimercount(mitochondria,'chart','bar')
ans =
AA: 1604
AC: 1495
AG: 795
AT: 1230
CA: 1534
CC: 1771
CG: 435
CT: 1440
GA: 613
GC: 711
GG: 425
GT: 419
TA: 1373
TC: 1204
TG: 513
TT: 1004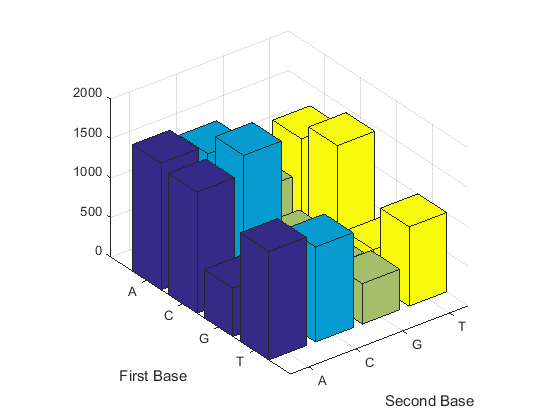
Следующая процедура иллюстрирует, как посмотреть на кодоны для этих шести рамок считывания. Trinucleotides (кодон) код для аминокислоты, и существуют 64 возможных кодона в последовательности нуклеотида. Знание процента кодонов в вашей последовательности может быть полезным, когда вы соответствуете таблицам для ожидаемого использования кодона.
После того, как вы считаете последовательность в среду MATLAB, можно анализировать последовательность для состава кодона. Эта процедура использует человеческий геном митохондрий в качестве примера. Смотрите информацию Последовательности Чтения из сети.
Считайте кодоны в последовательности нуклеотида. В Командном Окне MATLAB введите
codoncount(mitochondria)
Кодон значит отображения системы координат первого чтения.
AAA - 167 AAC - 171 AAG - 71 AAT - 130 ACA - 137 ACC - 191 ACG - 42 ACT - 153 AGA - 59 AGC - 87 AGG - 51 AGT - 54 ATA - 126 ATC - 131 ATG - 55 ATT - 113 CAA - 146 CAC - 145 CAG - 68 CAT - 148 CCA - 141 CCC - 205 CCG - 49 CCT - 173 CGA - 40 CGC - 54 CGG - 29 CGT - 27 CTA - 175 CTC - 142 CTG - 74 CTT - 101 GAA - 67 GAC - 53 GAG - 49 GAT - 35 GCA - 81 GCC - 101 GCG - 16 GCT - 59 GGA - 36 GGC - 47 GGG - 23 GGT - 28 GTA - 43 GTC - 26 GTG - 18 GTT - 41 TAA - 157 TAC - 118 TAG - 94 TAT - 107 TCA - 125 TCC - 116 TCG - 37 TCT - 103 TGA - 64 TGC - 40 TGG - 29 TGT - 26 TTA - 96 TTC - 107 TTG - 47 TTT - 78
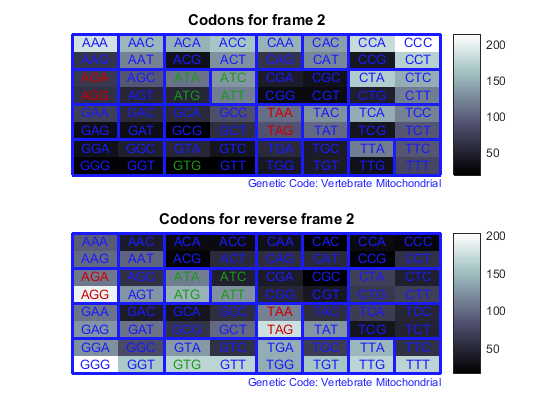
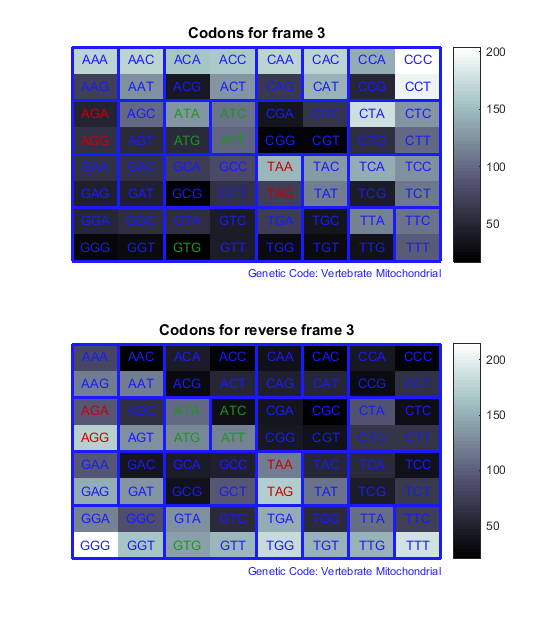
Считайте кодоны во всех шести рамках считывания и постройте результаты в картах тепла.
for frame = 1:3
figure
subplot(2,1,1);
codoncount(mitochondria,'frame',frame,'figure',true,...
'geneticcode','Vertebrate Mitochondrial');
title(sprintf('Codons for frame %d',frame));
subplot(2,1,2);
codoncount(mitochondria,'reverse',true,'frame',frame,...
'figure',true,'geneticcode','Vertebrate Mitochondrial');
title(sprintf('Codons for reverse frame %d',frame));
end
Нагрейтесь карты отображают все 64 кодона в этих 6 рамках считывания.

Следующая процедура иллюстрирует, как определить местоположение открытых рамок считывания с помощью определенного генетического кода. Определение кодирующей белок последовательности для эукариотического гена может быть трудной задачей, потому что интроны (не кодирующий разделы) смешаны с экзонами. Однако прокариотические гены обычно не имеют интронов, и mRNA последовательностям удалили интроны. Идентификация запуска и кодонов остановки для перевода определяет кодирующий белок раздел или открытую рамку считывания (ORF), в последовательности. Если вы знаете ORF для гена или mRNA, можно перевести последовательность нуклеотида в ее соответствующую последовательность аминокислот.
После того, как вы считаете последовательность в среду MATLAB, можно анализировать последовательность для открытых рамок считывания. Эта процедура использует человеческий геном митохондрий в качестве примера. Смотрите информацию Последовательности Чтения из сети.
Отобразите открытые рамки считывания (ORFs) в последовательности нуклеотида. В Командном Окне MATLAB введите:
seqshoworfs(mitochondria);
Если вы сравниваете этот выход с генами, показанными на странице NCBI для NC_012920, чем ожидалось существует меньше генов. Это вызвано тем, что позвоночные митохондрии используют генетический код, немного отличающийся от стандартного генетического кода. Для списка генетических кодов см. таблицу Genetic Code в aa2nt страница с описанием.
Отобразите ORFs использование Vertebrate Mitochondrial код.
orfs= seqshoworfs(mitochondria,...
'GeneticCode','Vertebrate Mitochondrial',...
'alternativestart',true);
Заметьте, что существует теперь два больших ORFs на третьей рамке считывания. Каждый запускает в положении 4470 и других запусках в 5 904. Они соответствуют генам ND2 (подблок дегидрогеназы NADH 2 [Человек разумный]) и COX1 (цитохром c подблок оксидазы I) гены.
Найдите соответствующий кодон остановки. Запуск и положения остановки для ORFs имеют те же индексы как положения запуска в полях Start и Stop.
ND2Start = 4470; StartIndex = find(orfs(3).Start == ND2Start) ND2Stop = orfs(3).Stop(StartIndex)
Отображения положения остановки.
ND2Stop =
5511Используя индексы последовательности для запуска и остановки гена, извлеките подпоследовательность из последовательности.
ND2Seq = mitochondria(ND2Start:ND2Stop)
Подпоследовательность (кодирующая белок область) хранится в ND2Seq и отображенный на экране.
attaatcccctggcccaacccgtcatctactctaccatctttgcaggcac actcatcacagcgctaagctcgcactgattttttacctgagtaggcctag aaataaacatgctagcttttattccagttctaaccaaaaaaataaaccct cgttccacagaagctgccatcaagtatttcctcacgcaagcaaccgcatc cataatccttc . . .
Определите распределение кодона.
codoncount (ND2Seq)
Количество кодона показывает большое количество ACC, ATA, CTA, и ATC.
AAA - 10 AAC - 14 AAG - 2 AAT - 6 ACA - 11 ACC - 24 ACG - 3 ACT - 5 AGA - 0 AGC - 4 AGG - 0 AGT - 1 ATA - 23 ATC - 24 ATG - 1 ATT - 8 CAA - 8 CAC - 3 CAG - 2 CAT - 1 CCA - 4 CCC - 12 CCG - 2 CCT - 5 CGA - 0 CGC - 3 CGG - 0 CGT - 1 CTA - 26 CTC - 18 CTG - 4 CTT - 7 GAA - 5 GAC - 0 GAG - 1 GAT - 0 GCA - 8 GCC - 7 GCG - 1 GCT - 4 GGA - 5 GGC - 7 GGG - 0 GGT - 1 GTA - 3 GTC - 2 GTG - 0 GTT - 3 TAA - 0 TAC - 8 TAG - 0 TAT - 2 TCA - 7 TCC - 11 TCG - 1 TCT - 4 TGA - 10 TGC - 0 TGG - 1 TGT - 0 TTA - 8 TTC - 7 TTG - 1 TTT - 8
Ищите аминокислоты для кодонов ATA, CTA, ACC, и ATC.
aminolookup('code',nt2aa('ATA'))
aminolookup('code',nt2aa('CTA'))
aminolookup('code',nt2aa('ACC'))
aminolookup('code',nt2aa('ATC'))
Следующие отображения:
Ile isoleucine Leu leucine Thr threonine Ile isoleucine
Следующая процедура иллюстрирует, как извлечь кодирующую белок последовательность из последовательности генов и преобразовать ее в последовательность аминокислот для белка. Определение относительного состава аминокислоты белка даст вам характеристический профиль для белка. Часто, этот профиль является достаточной информацией, чтобы идентифицировать белок. Используя состав аминокислоты, атомарный состав и молекулярную массу, можно также искать общедоступные базы данных подобные белки.
После того, как вы определите местоположение открытой рамки считывания (ORF) в гене, можно преобразовать его в последовательность аминопласта и определить ее состав аминокислоты. Эта процедура использует человеческий геном митохондрий в качестве примера. Смотрите Открытые Рамки считывания.
Преобразуйте последовательность нуклеотида в последовательность аминокислот. В этом примере только преобразована кодирующая белок последовательность между запуском и кодонами остановки.
ND2AASeq = nt2aa(ND2Seq,'geneticcode',...
'Vertebrate Mitochondrial')
Последовательность преобразована с помощью Vertebrate Mitochondrial генетический код. Поскольку свойство AlternativeStartCodons установлен в 'true' по умолчанию, первый кодон att преобразован в M вместо I.
MNPLAQPVIYSTIFAGTLITALSSHWFFTWVGLEMNMLAFIPVLTKKMNP RSTEAAIKYFLTQATASMILLMAILFNNMLSGQWTMTNTTNQYSSLMIMM AMAMKLGMAPFHFWVPEVTQGTPLTSGLLLLTWQKLAPISIMYQISPSLN VSLLLTLSILSIMAGSWGGLNQTQLRKILAYSSITHMGWMMAVLPYNPNM TILNLTIYIILTTTAFLLLNLNSSTTTLLLSRTWNKLTWLTPLIPSTLLS LGGLPPLTGFLPKWAIIEEFTKNNSLIIPTIMATITLLNLYFYLRLIYST SITLLPMSNNVKMKWQFEHTKPTPFLPTLIALTTLLLPISPFMLMIL
Сравните свое преобразование с опубликованным преобразованием в базе данных GenPept.
ND2protein = getgenpept('YP_003024027','sequenceonly',true)
getgenpept функция получает опубликованное преобразование из базы данных NCBI и читает его в рабочее пространство MATLAB.
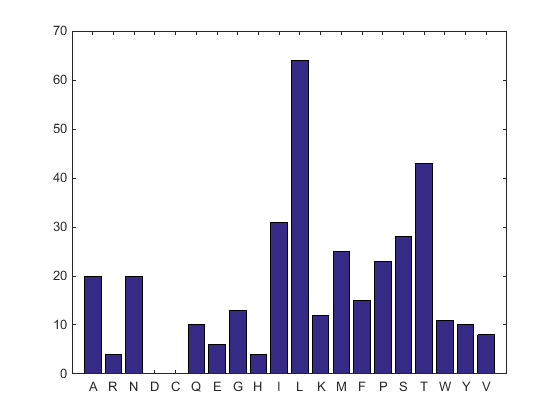
Считайте аминокислоты в последовательности белка.
aacount(ND2AASeq, 'chart','bar')
Столбчатый график отображается. Заметьте высокое содержимое для лейцина, треонина и изолейцина, и также заметьте отсутствие кислоты аспарагиновой кислоты и цистеина.
Определите атомарный состав и молекулярную массу белка.
atomiccomp(ND2AASeq) molweight (ND2AASeq)
Следующие отображения в рабочем пространстве MATLAB:
ans =
C: 1818
H: 2882
N: 420
O: 471
S: 25ans = 3.8960e+004
Если бы эта последовательность была неизвестна, вы могли бы использовать эту информацию, чтобы идентифицировать белок путем сравнения ее с атомарным составом других белков в базе данных.
