Класс: matlab.perftest.TimeResult
Пакет: matlab.perftest
Создайте график сравнить результаты испытаний измерения и базовая линия
comparisonPlot( создает график, который визуально сравнивает каждый Baseline,Measurement)TimeResult объект в массивах Baseline и Measurement. Сравнение основано на минимуме демонстрационных времен измерения.
comparisonPlot( указывает, что статистическая величина применилась к демонстрационным временам измерения каждого Baseline,Measurement,stat)TimeResult объект в Baseline и Measurement.
comparisonPlot(___, создает график сравнения с дополнительными опциями, заданными одним или несколькими Name,Value)Name,Value парные аргументы. Например, comparisonPlot(Baseline,Measurement,'Scale','linear') создает график с линейной шкалой для x - и y - оси.
cp = comparisonPlot(___) возвращает ComparisonPlot объект, заданный как экземпляр matlab.unittest.measurement.chart.ComparisonPlot класс. Используйте cp изменить свойства определенного графика сравнения после того, как вы создаете его.
Визуализируйте вычислительную сложность двух алгоритмов сортировки, пузырьковой сортировки и сортировки слиянием, который элементы списка видов в порядке возрастания. Пузырьковая сортировка является простым алгоритмом сортировки, который неоднократно продвигается через список, сравнивает смежные пары элементов и подкачивает элементы, если они находятся в неправильном порядке. Сортировка слиянием, "делят и завоевывают" алгоритм, который использует в своих интересах простоту слияния отсортированных подсписков в новый отсортированный список.
В вашей текущей папке сохраните следующий код в bubbleSort.m.
function y = bubbleSort(x) % Sorting algorithm with O(n^2) complexity n = length(x); swapped = true; while swapped swapped = false; for i = 2:n if x(i-1) > x(i) temp = x(i-1); x(i-1) = x(i); x(i) = temp; swapped = true; end end end y=x; end
Сохраните следующий код в mergeSort.m.
function y = mergeSort(x) % Sorting algorithm with O(n*logn) complexity y = x; % A list of one element is considered sorted if length(x) > 1 mid = floor(length(x)/2); L = x(1:mid); R = x((mid+1):end); % Sort left and right sublists recursively L = mergeSort(L); R = mergeSort(R); % Merge the sorted left (L) and right (R) sublists i = 1; j = 1; k = 1; while i <= length(L) && j <= length(R) if L(i) < R(j) y(k) = L(i); i = i + 1; else y(k) = R(j); j = j + 1; end k = k + 1; end % At this point, either L or R is empty while i <= length(L) y(k) = L(i); i = i + 1; k = k + 1; end while j <= length(R) y(k) = R(j); j = j + 1; k = k + 1; end end end
Создайте следующий параметризованный тестовый класс, TestSort, который сравнивает производительность алгоритмов сортировки слиянием и пузырьковой сортировки. len свойство содержит количество элементов списка, которые вы хотите протестировать.
classdef TestSort < matlab.perftest.TestCase properties Data SortedData end properties(ClassSetupParameter) % Create 25 logarithmically spaced values between 10^2 and 10^4 len = num2cell(round(logspace(2,4,25))); end methods(TestClassSetup) function ClassSetup(testCase,len) orig = rng; testCase.addTeardown(@rng,orig) rng('default') testCase.Data = rand(1,len); testCase.SortedData = sort(testCase.Data); end end methods(Test) function testBubbleSort(testCase) while testCase.keepMeasuring y = bubbleSort(testCase.Data); end testCase.verifyEqual(y,testCase.SortedData); end function testMergeSort(testCase) while testCase.keepMeasuring y = mergeSort(testCase.Data); end testCase.verifyEqual(y,testCase.SortedData); end end end
Запустите тесты производительности для всех тестовых элементов, которые соответствуют 'testBubbleSort' метод, и сохраняет результаты в Baseline массив. Ваши результаты могут варьироваться от показанных результатов.
Baseline = runperf('TestSort','ProcedureName','testBubbleSort');
Running TestSort .......... .......... .......... .......... .......... .......... .......... .......... .......... .......... .......... .......... .......... .......... .......... .......... .......... .......... .......... .......... .......... .......... .......... .......... .......... .......... .......... ..... Done TestSort __________
Запустите тесты производительности для всех элементов, которые соответствуют 'testMergeSort' метод, и сохраняет результаты в Measurement массив.
Measurement = runperf('TestSort','ProcedureName','testMergeSort');
Running TestSort .......... .......... .......... .......... .......... .......... .......... .......... .......... .......... .......... .......... .......... .......... .......... .......... .......... .......... .......... .......... Done TestSort __________
Визуально сравните минимум MeasuredTime столбец в Samples таблица для каждой соответствующей пары Baseline и Measurement объекты.
comparisonPlot(Baseline,Measurement);
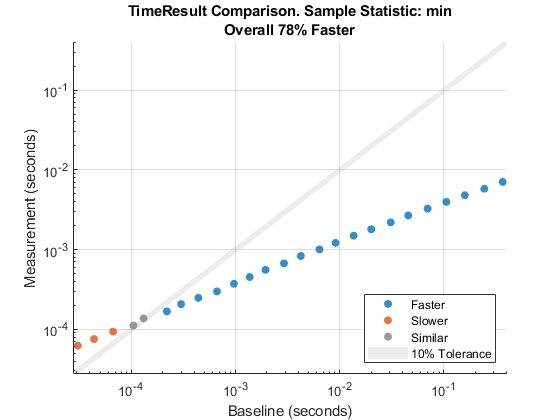
В этом графике сравнения большинство точек данных является синим, потому что они ниже теневой области подобия. Этот результат показывает на наилучшее решение сортировки слиянием для большинства тестов. Однако для достаточно маленьких списков, пузырьковая сортировка выполняет лучше, чем или сопоставимый с сортировкой слиянием, как показано оранжевыми и серыми точками на графике.
Как сводные данные сравнения, график сообщает о 78%-м повышении производительности из-за сортировки слиянием. Это значение является геометрическим средним значением процентов улучшения, соответствующих всем точкам данных. Если бы график сравнения содержал недопустимые точки данных, сводные данные сравнения не были бы сгенерированы.
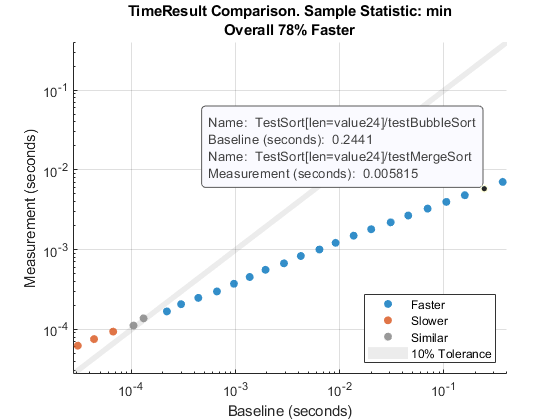
Можно нажать или навести на любую точку данных, чтобы просмотреть подробную информацию о сравниваемых результатах измерения времени.
Чтобы изучить худший случай, сортирующий производительность алгоритма для различных длин списка, создайте график сравнения на основе максимума демонстрационных времен измерения.
comparisonPlot(Baseline,Measurement,'max');
Уменьшайте SimilarityTolerance к 0.01 при сравнении максимума демонстрационных времен измерения. Возвратите ComparisonPlot объект в cp так, чтобы можно было изменить его свойства позже.
cp = comparisonPlot(Baseline,Measurement,'max','SimilarityTolerance',0.01);

