Сглаживайте зашумленные данные
B = smoothdata(A)
Если A матрица, затем smoothdata вычисляет скользящее среднее значение вниз каждый столбец.
Если A многомерный массив, затем smoothdata действует по первому измерению, размер которого не равняется 1.
Если A таблица или расписание с числовыми переменными, затем smoothdata работает с каждой переменной отдельно.
B = smoothdata(___,Name,Value)t вектор временных стоимостей, затем smoothdata(A,'SamplePoints',t) сглаживает данные в A относительно времен в t.
Создайте вектор, содержащий зашумленные данные, и сглаживайте данные со скользящим средним значением. Отобразите исходные и сглаживавшие данные на графике.
x = 1:100; A = cos(2*pi*0.05*x+2*pi*rand) + 0.5*randn(1,100); B = smoothdata(A); plot(x,A,'-o',x,B,'-x') legend('Original Data','Smoothed Data')

Создайте матрицу, строки которой представляют три сигнала с шумом. Сглаживайте три сигнала с помощью скользящего среднего значения и отобразите сглаживавшие данные на графике.
x = 1:100; s1 = cos(2*pi*0.03*x+2*pi*rand) + 0.5*randn(1,100); s2 = cos(2*pi*0.04*x+2*pi*rand) + 0.4*randn(1,100) + 5; s3 = cos(2*pi*0.05*x+2*pi*rand) + 0.3*randn(1,100) - 5; A = [s1; s2; s3]; B = smoothdata(A,2); plot(x,B(1,:),x,B(2,:),x,B(3,:))

Сглаживайте вектор зашумленных данных со Взвешенным гауссовым образом фильтром скользящего среднего значения. Отобразите длину окна, используемую фильтром.
x = 1:100;
A = cos(2*pi*0.05*x+2*pi*rand) + 0.5*randn(1,100);
[B, window] = smoothdata(A,'gaussian');
windowwindow = 4
Сглаживайте исходные данные с большим окном длины 20. Отобразите сглаживавшие данные на графике для обеих длин окна.
C = smoothdata(A,'gaussian',20); plot(x,B,'-o',x,C,'-x') legend('Small Window','Large Window')

Вектор с NaNСоздайте шумный вектор, содержащий NaN значения, и сглаженный данные, игнорирующие NaN, который является значением по умолчанию.
A = [NaN randn(1,48) NaN randn(1,49) NaN]; B = smoothdata(A);
Сглаживайте данные включая NaN значения. Среднее значение в окне, содержащем NaN isnan.
C = smoothdata(A,'includenan');Отобразите сглаживавшие данные на графике в B и C.
plot(1:100,B,'-o',1:100,C,'-x') legend('Ignore NaN','Include NaN')

Создайте вектор зашумленных данных, которые соответствуют временному вектору t. Сглаживайте данные относительно времен в t, и отобразите на графике исходные данные и сглаживавшие данные.
x = 1:100; A = cos(2*pi*0.05*x+2*pi*rand) + 0.5*randn(1,100); t = datetime(2017,1,1,0,0,0) + hours(0:99); B = smoothdata(A,'SamplePoints',t); plot(t,A,'-o',t,B,'-x') legend('Original Data','Smoothed Data')

A — Входной массивВходной массив, заданный как вектор, матрица, многомерный массив, таблица или расписание. Если A таблица или расписание, затем или переменные должны быть числовыми, или необходимо использовать 'DataVariables' пара "имя-значение", чтобы перечислить числовые переменные явным образом. Определение переменных полезно, когда вы работаете с таблицей, которая также содержит нечисловые переменные.
Типы данных: double | single | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64 | logical | table | timetable
Поддержка комплексного числа: Да
dim — Размерность, которая задает направление расчетаВеличина для работы, заданная как положительный целый скаляр. Если значение не задано, то по умолчанию это первый размер массива, не равный 1.
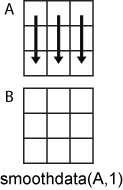
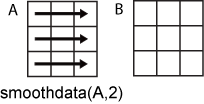
Рассмотрите матричный A.
B = smoothdata(A,1) сглаживает данные в каждом столбце A.
B = smoothdata(A,2) сглаживает данные в каждой строке A.
Когда A таблица или расписание, dim не поддержан. smoothdata действует вдоль каждой переменной таблицы или расписания отдельно.
Типы данных: double | single | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
method — Сглаживание метода'movmean' (значение по умолчанию) | 'movmedian' | 'gaussian' | 'lowess' | 'loess' | 'rlowess' | 'rloess' | 'sgolay'Сглаживание метода, заданного как одно из следующего:
'movmean' — Скользящее среднее значение по каждому окну A. Этот метод полезен для сокращения периодических трендов в данных.
'movmedian' — Движущаяся медиана по каждому окну A. Этот метод полезен для сокращения периодических трендов в данных, когда выбросы присутствуют.
'gaussian' — Взвешенное гауссовым образом скользящее среднее значение по каждому окну A.
'lowess' — Линейная регрессия по каждому окну A. Этот метод может быть в вычислительном отношении дорогим, но результаты в меньшем количестве разрывов.
'loess' — Квадратичная регрессия по каждому окну A. Этот метод является немного более в вычислительном отношении дорогим, чем 'lowess'.
'rlowess' — Устойчивая линейная регрессия по каждому окну A. Этот метод является более в вычислительном отношении дорогой версией метода 'lowess', но это более устойчиво к выбросам.
'rloess' — Устойчивая квадратичная регрессия по каждому окну A. Этот метод является более в вычислительном отношении дорогой версией метода 'loess', но это более устойчиво к выбросам.
'sgolay' — Фильтр Savitzky-Golay, который сглаживает согласно квадратичному полиному, который адаптирован по каждому окну A. Этот метод может быть более эффективным, чем другие методы, когда данные варьируются быстро.
window — Длина окнаДлина окна, заданная как положительный целочисленный скаляр, двухэлементный вектор положительных целых чисел, положительного скаляра длительности или двухэлементного вектора положительной длительности.
Когда window положительный целочисленный скаляр, затем окно сосредоточено о текущем элементе и содержит window-1 граничение с элементами. Если window даже, затем окно сосредоточено о текущих и предыдущих элементах. Если window двухэлементный вектор положительных целых чисел [b f], затем окно содержит текущий элемент, b элементы назад и f элементы вперед.
Когда A расписание или когда 'SamplePoints' задан как datetime или duration вектор, window должен иметь тип duration, и окно вычисляется относительно точек выборки.
Когда длина окна также задана как выходной аргумент, выходное значение совпадает с входным значением.
Типы данных: double | single | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64 | duration
nanflag NaN условие'omitnan' (значение по умолчанию) | 'includenan'NaN условие, заданное как одно из следующих значений:
'omitnan' — Проигнорируйте NaN значения во входе. Если окно содержит весь NaN значения, затем smoothdata возвращает NaN.
'includenan' — Включайте NaN значения при вычислении в каждом окне, приведении к NaN.
Задайте дополнительные разделенные запятой пары Name,Value аргументы. Name имя аргумента и Value соответствующее значение. Name должен появиться в кавычках. Вы можете задать несколько аргументов в виде пар имен и значений в любом порядке, например: Name1, Value1, ..., NameN, ValueN.
smoothdata(A,'SmoothingFactor',0.5)Когда размер окна для метода сглаживания не задан, smoothdata вычисляет размер окна по умолчанию на основе эвристики. Для фактора сглаживания τ, эвристика оценивает размер окна скользящего среднего значения, который затухает приблизительно 100*τ процент энергии входных данных.
Smoothdata | fillmissing | filter | movmad | movmean | movmedian
