Односторонний дисперсионный анализ
p = anova1(y)y и возвращает p - значение. anova1 обработки каждый столбец y как отдельная группа. Функция тестирует гипотезу что выборки в столбцах y чертятся от популяций с тем же средним значением против альтернативной гипотезы, что средние значения населения не являются всеми одинаковыми. Функция также отображает диаграмму для каждой группы в y и стандартная таблица ANOVA (tbl).
p = anova1(y,group,displayopt)displayopt 'on' (значение по умолчанию) и подавляет отображения когда displayopt 'off'.
[ возвращает структуру, p,tbl,stats]
= anova1(___)stats, который можно использовать, чтобы выполнить тест сравнения кратного. Тест сравнения кратного позволяет вам определить, какие пары средних значений группы существенно отличаются. Чтобы выполнить этот тест, используйте multcompare, обеспечение stats структура как входной параметр.
Создайте матрицу выборочных данных y со столбцами, которые являются константами плюс случайные нормальные воздействия со средним значением 0 и стандартным отклонением 1.
y = meshgrid(1:5); rng default; % For reproducibility y = y + normrnd(0,1,5,5)
y = 5×5
1.5377 0.6923 1.6501 3.7950 5.6715
2.8339 1.5664 6.0349 3.8759 3.7925
-1.2588 2.3426 3.7254 5.4897 5.7172
1.8622 5.5784 2.9369 5.4090 6.6302
1.3188 4.7694 3.7147 5.4172 5.4889
Выполните односторонний Дисперсионный Анализ.
p = anova1(y)


p = 0.0023
Таблица ANOVA показывает изменение между группами (Columns) и изменение в группах (Error). SS сумма квадратов и df степени свободы. Общие степени свободы являются общим количеством наблюдений минус одно, которое равняется 25 - 1 = 24. Степени свободы между группами являются количеством групп минус одна, которая равняется 5 - 1 = 4. Степени свободы в группах являются общими степенями свободы минус между степенями свободы групп, который равняется 24 - 4 = 20.
MS среднеквадратическая ошибка, которая является SS/df для каждого источника изменения. F-статистическая-величина является отношением среднеквадратических ошибок (13.4309/2.2204). P-значение является вероятностью, что тестовая статистическая величина может принять значение, больше, чем значение вычисленной тестовой статистической величины, т.е. P (F> 6.05). Маленькое p-значение 0,0023 указывает, что различия между средними значениями столбца являются значительными.
Введите выборочные данные.
strength = [82 86 79 83 84 85 86 87 74 82 ... 78 75 76 77 79 79 77 78 82 79]; alloy = {'st','st','st','st','st','st','st','st',... 'al1','al1','al1','al1','al1','al1',... 'al2','al2','al2','al2','al2','al2'};
Данные от исследования силы структурных лучей в Хогге (1987). Векторная сила измеряет отклонения лучей в тысячных частях дюйма менее чем 3 000 фунтов силы. Векторный сплав идентифицирует каждый луч как сталь ('st'), сплавьте 1 ('al1'), или сплав 2 ('al2'). Несмотря на то, что сплав сортируется в этом примере, сгруппированные переменные не должны быть отсортированы.
Протестируйте нулевую гипотезу, что стальные балки равны в силе лучам, сделанным из двух более дорогих сплавов. Выключите отображение фигуры и возвратите результаты Дисперсионного Анализа в массиве ячеек.
[p,tbl] = anova1(strength,alloy,'off')p = 1.5264e-04
tbl=4×6 cell
Columns 1 through 5
{'Source'} {'SS' } {'df'} {'MS' } {'F' }
{'Groups'} {[184.8000]} {[ 2]} {[ 92.4000]} {[ 15.4000]}
{'Error' } {[102.0000]} {[17]} {[ 6.0000]} {0x0 double}
{'Total' } {[286.8000]} {[19]} {0x0 double} {0x0 double}
Column 6
{'Prob>F' }
{[1.5264e-04]}
{0x0 double }
{0x0 double }
Общие степени свободы являются общим количеством наблюдений минус одно, которое является . Степени свободы между группами являются количеством групп минус одна, которая является . Степени свободы в группах являются общими степенями свободы минус между степенями свободы групп, который является .
MS среднеквадратическая ошибка, которая является SS/df для каждого источника изменения. F-статистическая-величина является отношением среднеквадратических ошибок. P-значение является вероятностью, что тестовая статистическая величина может принять значение, больше, чем, или равняться значению тестовой статистической величины. P-значение 1.5264e-04 предлагает отклонение нулевой гипотезы.
Можно получить значения в таблице ANOVA путем индексации в массив ячеек. Сохраните значение F-статистической-величины и p-значение в новых переменных Fstat и pvalue.
Fstat = tbl{2,5}Fstat = 15.4000
pvalue = tbl{2,6}pvalue = 1.5264e-04
Введите выборочные данные.
strength = [82 86 79 83 84 85 86 87 74 82 ... 78 75 76 77 79 79 77 78 82 79]; alloy = {'st','st','st','st','st','st','st','st',... 'al1','al1','al1','al1','al1','al1',... 'al2','al2','al2','al2','al2','al2'};
Данные от исследования силы структурных лучей в Хогге (1987). Векторная сила измеряет отклонения лучей в тысячных частях дюйма менее чем 3 000 фунтов силы. Векторный сплав идентифицирует каждый луч как сталь (st), сплавьте 1 (al1), или сплав 2 (al2). Несмотря на то, что сплав сортируется в этом примере, сгруппированные переменные не должны быть отсортированы.
Выполните односторонний Дисперсионный Анализ с помощью anova1. Возвратите структуру stats, который содержит статистику multcompare потребности в выполнении Нескольких Сравнений.
[~,~,stats] = anova1(strength,alloy);


Маленькое p-значение 0,0002 предполагает, что сила лучей не является тем же самым.
Выполните сравнение кратного средней силы лучей.
[c,~,~,gnames] = multcompare(stats);

Отобразите результаты сравнения с соответствующими названиями группы.
[gnames(c(:,1)), gnames(c(:,2)), num2cell(c(:,3:6))]
ans=3×6 cell
Columns 1 through 5
{'st' } {'al1'} {[ 3.6064]} {[ 7]} {[10.3936]}
{'st' } {'al2'} {[ 1.6064]} {[ 5]} {[ 8.3936]}
{'al1'} {'al2'} {[-5.6280]} {[-2]} {[ 1.6280]}
Column 6
{[1.6831e-04]}
{[ 0.0040]}
{[ 0.3560]}
Первые два столбца показывают пару групп, которые сравнены. Четвертый столбец показывает различие между предполагаемыми средними значениями группы. Третьи и пятые колонны показывают нижние и верхние пределы для 95% доверительных интервалов истинного различия средних значений. Шестой столбец показывает p-значение для гипотезы, что истинное различие средних значений для соответствующих групп равно нулю.
Первые две строки показывают, что оба сравнения, вовлекающие первую группу (сталь), уверены интервалы, которые не включают нуль. Поскольку соответствующие p-значения (1.6831e-04 и 0.0040, соответственно) малы, те различия являются значительными.
Третья строка показывает, что различия в силе между двумя сплавами не являются значительными. 95%-й доверительный интервал для различия [-5.6 1.6], таким образом, вы не можете отклонить гипотезу, что истинным различием является нуль. Соответствующее p-значение 0,3560 в шестом столбце подтверждает этот результат.
В фигуре синяя панель представляет интервал сравнения для средней прочности материала для стали. Красные панели представляют интервалы сравнения для средней прочности материала для сплава 1 и сплавляют 2. Ни одна из красных панелей не накладывается с синей панелью, которая указывает, что средняя прочность материала для стали существенно отличается от того из сплава 1 и сплава 2. Подтвердить значительную разницу путем нажатия на панели, которые представляют сплав 1 и 2.
y — выборочные данныеВыборочные данные, заданные как вектор или матрица.
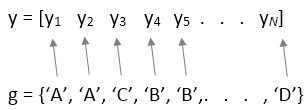
Если y вектор, необходимо задать group входной параметр. Каждый элемент в group представляет название группы соответствующего элемента в y. anova1 функционируйте обрабатывает y значения, соответствующие тому же значению group как часть той же группы. Используйте этот проект, когда у групп есть различные числа элементов (разбалансировал Дисперсионный Анализ).
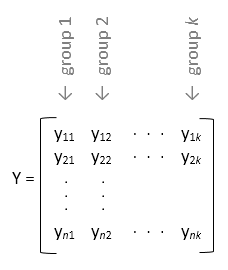
Если y матрица, и вы не задаете group, затем anova1 обработки каждый столбец y как отдельная группа. В этом проекте функция оценивает, равны ли средние значения населения столбцов. Используйте этот проект, когда у каждой группы есть то же число элементов (сбалансировал Дисперсионный Анализ).
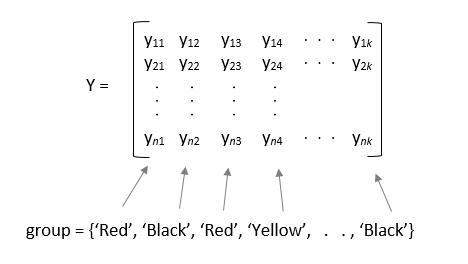
Если y матрица, и вы задаете group, затем каждый элемент в group представляет название группы для соответствующего столбца в y. anova1 функционируйте обрабатывает столбцы, которые имеют то же название группы как часть той же группы.
anova1 игнорирует любой NaN значения в y. Кроме того, если group содержит пустой или NaN значения, anova1 игнорирует соответствующие наблюдения в y. anova1 функция выполняет, сбалансировал Дисперсионный Анализ, если у каждой группы есть то же количество наблюдений после того, как функция игнорирует пустой или NaN значения. В противном случае, anova1 выполняет разбалансировал Дисперсионный Анализ.
Типы данных: single | double
group — Сгруппированная переменнаяСгруппированная переменная, содержащая названия группы, заданные как числовой вектор, логический вектор, категориальный вектор, символьный массив, массив строк или массив ячеек из символьных векторов.
Если y вектор, затем каждый элемент в group представляет название группы соответствующего элемента в y. anova1 функционируйте обрабатывает y значения, соответствующие тому же значению group как часть той же группы.
N является общим количеством наблюдений.
Если y матрица, затем каждый элемент в group представляет название группы для соответствующего столбца в y. anova1 функционируйте обрабатывает столбцы y это имеет то же название группы как часть той же группы.
Если вы не хотите задавать названия группы для матричных выборочных данных y, введите пустой массив ([]) или не используйте этот аргумент. В этом случае, anova1 обработки каждый столбец y как отдельная группа.
Если group содержит пустой или NaN значения, anova1 игнорирует соответствующие наблюдения в y.
Для получения дополнительной информации о сгруппированных переменных смотрите Сгруппированные переменные.
Пример: 'group',[1,2,1,3,1,...,3,1] когда y вектор с наблюдениями, категоризированными в группы 1, 2, и 3
Пример: 'group',{'white','red','white','black','red'} когда y матрица с пятью столбцами, категоризированными в группы, красные, белые, и черные
Типы данных: single | double | logical | categorical | char | string | cell
displayopt — Индикатор, чтобы отобразить таблицу ANOVA и диаграмму'on' (значение по умолчанию) | 'off'Индикатор, чтобы отобразить таблицу ANOVA и диаграмму, заданную как 'on' или 'off'. Когда displayopt 'off', anova1 возвращает выходные аргументы, только. Это не отображает стандартную таблицу ANOVA и диаграмму.
Пример: p = anova(x,group,'off')
[1] Хогг, R. V., и Дж. Ледолтер. Техническая статистика. Нью-Йорк: Макмиллан, 1987.
anova2 | anovan | boxplot | multcompare
