Можно использовать функцию Statistics and Machine Learning Toolbox™ anova2 выполнять сбалансированный двухсторонний дисперсионный анализ (Дисперсионный Анализ). Чтобы выполнить двухсторонний Дисперсионный Анализ для несбалансированного проекта, используйте anovan. Для примера смотрите Двухсторонний Дисперсионный Анализ для Несбалансированного Проекта.
Как в одностороннем Дисперсионном Анализе, данные для двухстороннего исследования Дисперсионного Анализа могут быть экспериментальными или наблюдательными. Различие между односторонним и двухсторонним Дисперсионным Анализом - то, что в двухстороннем Дисперсионном Анализе, эффекты двух факторов на переменной отклика представляют интерес. Эти два фактора могут быть независимыми, и не оказать влияние взаимодействия, или удар одного фактора на переменной отклика может зависеть от группы (уровень) другого фактора. Если эти два фактора не имеют никаких взаимодействий, модель называется аддитивной моделью.
Предположим, что автомобильная компания имеет две фабрики, и каждая фабрика делает те же три модели автомобилей. Расход бензина в автомобилях может варьироваться от фабрики до фабрики и от модели до модели. Эти два фактора, фабрика и модель, объясняют различия в пробеге, то есть, ответе. Одной мерой интереса является различие в пробеге из-за производственных методов между фабриками. Другой мерой интереса является различие в пробеге моделей (независимо от фабрики) из-за различных спецификаций проекта. Эффекты этих мер интереса являются дополнением. Кроме того, предположите, что только одна модель имеет различный расход бензина между фабриками, в то время как пробег других двух моделей является тем же самым между фабриками. Это называется эффектом взаимодействия. Чтобы измерить эффект взаимодействия, должно быть несколько наблюдений для некоторой комбинации модели автомобиля и фабрики. Эти несколько наблюдений называются репликациями.
Двухсторонний Дисперсионный Анализ является особым случаем линейной модели. Двухсторонняя форма Дисперсионного Анализа модели
где,
yijr является наблюдением за переменной отклика.
i представляет группу i фактора строки A, i = 1, 2..., I
j представляет группу j фактора столбца B, j = 1, 2..., J
r представляет номер репликации, r = 1, 2..., R
Существует в общей сложности N = I наблюдения *J*R.
μ является полным средним значением.
αi является отклонениями групп фактора строки A от полного среднего μ из-за фактора строки B. Значения αi суммируют к 0.
βj является отклонениями групп в факторе столбца B от полного среднего μ из-за фактора строки B. Все значения в данном столбце βj идентичны, и значения суммы βj к 0.
αβij является взаимодействиями. Значения в каждой строке и в каждом столбце αβij суммируют к 0.
εijr является случайными воздействиями. Они приняты, чтобы быть независимыми, нормально распределенными, и иметь постоянное отклонение.
В примере пробега:
yijr является наблюдениями расхода бензина, μ является полным средним расходом бензина.
αi является отклонениями экономичности каждого автомобиля от среднего расхода бензина μ из-за модели автомобиля.
βj является отклонениями экономичности каждого автомобиля от среднего расхода бензина μ из-за фабрики автомобиля.
anova2 требует, чтобы данные были сбалансированы, таким образом, каждая комбинация модели и фабрики должна иметь то же количество автомобилей.
Двухсторонний Дисперсионный Анализ тестирует гипотезы об эффектах факторов A и B и их взаимодействие на переменной отклика y. Гипотезы о равенстве среднего ответа для групп фактора строки A
Гипотезы о равенстве среднего ответа для групп фактора столбца B
Гипотезы о взаимодействии столбца и факторов строки
Выполнять сбалансированный двухсторонний Дисперсионный Анализ с помощью anova2, необходимо расположить данные в определенной матричной форме. Столбцы матрицы должны соответствовать группам фактора столбца, B. Строки должны соответствовать группам фактора строки, A, с тем же количеством репликаций для каждой комбинации групп факторов A и B.
Предположим, что фактор строки, A имеет три группы и фактор столбца B, имеет две группы (уровни). Также предположите, что каждая комбинация факторов A и B имеет два измерения или наблюдения (reps = 2). Затем у каждой группы факторного A есть шесть наблюдений и каждая группа факторного B четыре наблюдения.
Индексы указывают на строку, столбец и репликацию, соответственно. Например, y 221 соответствует измерению для второй группы факторного A, второй группы факторного B и первой репликации для этой комбинации.
В этом примере показано, как выполнить двухсторонний Дисперсионный Анализ, чтобы определить эффект модели автомобиля и фабрики на оценке пробега автомобилей.
Загрузите и отобразите выборочные данные.
load mileage
mileagemileage = 6×3
33.3000 34.5000 37.4000
33.4000 34.8000 36.8000
32.9000 33.8000 37.6000
32.6000 33.4000 36.6000
32.5000 33.7000 37.0000
33.0000 33.9000 36.7000
Существует три модели автомобилей (столбцы) и две фабрики (строки). Данные имеют шесть строк пробега, потому что каждая фабрика обеспечила три автомобиля каждой модели для исследования (т.е. номер репликации равняется трем). Данные из первой фабрики находятся в первых трех строках, и данные из второй фабрики находятся в последних трех строках.
Выполните двухсторонний Дисперсионный Анализ. Возвратите структуру статистики, stats, использовать в нескольких сравнениях.
nmbcars = 3; % Number of cars from each model, i.e., number of replications
[~,~,stats] = anova2(mileage,nmbcars);
Можно использовать F-статистику, чтобы сделать тесты гипотез, чтобы узнать, является ли пробег тем же самым через модели, фабрики и модель - пары фабрики. Прежде, чем выполнить эти тесты, необходимо настроить для аддитивных эффектов. anova2 возвращает p-значение в эти тесты.
P-значение для эффекта модели (Columns) нуль к четырем десятичным разрядам. Этим результатом является верный признак, что пробег варьируется от одной модели до другого.
P-значение для эффекта фабрики (Rows) 0.0039, который является также очень значительным. Это значение указывает, что одна фабрика превосходит другой по характеристикам в экономичности автомобилей, которые это производит. Наблюдаемое p-значение указывает, что F-статистическая-величина как экстремальное значение как наблюдаемый F происходит случайно приблизительно четыре из 1 000 раз, если расход бензина был действительно равен от фабрики до фабрики.
Фабрики и модели, кажется, не имеют никакого взаимодействия. P-значение, 0.8411, означает, что наблюдаемый результат вероятен (84 из 100 раз), учитывая, что нет никакого взаимодействия.
Выполните Несколько Сравнений, чтобы узнать, какая пара трех моделей автомобилей существенно отличается.
c = multcompare(stats)
Note: Your model includes an interaction term. A test of main effects can be difficult to interpret when the model includes interactions.

c = 3×6
1.0000 2.0000 -1.5865 -1.0667 -0.5469 0.0004
1.0000 3.0000 -4.5865 -4.0667 -3.5469 0.0000
2.0000 3.0000 -3.5198 -3.0000 -2.4802 0.0000
В матричном c, первые два столбца показывают пары моделей автомобилей, которые сравнены. Последний столбец показывает p-значения для теста. Все p-значения малы (0.0004, 0, и 0), который указывает, что средний пробег всех моделей автомобилей существенно отличается друг от друга.
В фигуре синяя панель является интервалом сравнения для среднего пробега первой модели автомобиля. Красные панели являются интервалами сравнения для среднего пробега вторых и третьих моделей автомобилей. Ни один из вторых и третьих интервалов сравнения не накладывается с первым интервалом сравнения, указывая, что средний пробег первой модели автомобиля отличается от среднего пробега второго и третьих моделей автомобилей. Если вы нажимаете на одну из других панелей, можно протестировать на другие модели автомобилей. Ни одно из перекрытия интервалов сравнения, указывая, что средний пробег каждой модели автомобиля существенно отличается от других двух.
2D факторный Дисперсионный Анализ делит общее изменение на следующие компоненты:
Изменение группы фактора строки означает от полного среднего значения,
Изменение группы фактора столбца означает от полного среднего значения,
Изменение полного среднего значения плюс репликация означает от среднего значения группы фактора столбца плюс среднее значение группы фактора строки,
Изменение наблюдений от средних значений репликации,
Дисперсионный Анализ делит полную сумму квадратов (SST) в сумму квадратов из-за фактора строки A (SSA), сумма квадратов из-за фактора столбца B (SSB), сумма квадратов из-за взаимодействия между A и B (SSAB) и ошибка суммы квадратов (SSE).
Дисперсионный Анализ берет изменение из-за фактора или взаимодействия и сравнивает его с изменением из-за ошибки. Если отношение этих двух изменений высоко, то эффект фактора или эффект взаимодействия являются статистически значительными. Можно измерить статистическое значение с помощью тестовой статистической величины, которая имеет F - распределение.
Для нулевой гипотезы, что средний ответ для групп фактора строки A равен, тестовая статистическая величина
Для нулевой гипотезы, что средний ответ для групп фактора столбца B равен, тестовая статистическая величина
Для нулевой гипотезы, которую равно нулю взаимодействие столбца и факторов строки, тестовая статистическая величина
Если p - значение для F - статистическая величина меньше, чем уровень значения, то Дисперсионный Анализ отклоняет нулевую гипотезу. Наиболее распространенные уровни значения 0.01 и 0.05.
Таблица ANOVA получает изменчивость в модели по источнику, F - статистической величине для тестирования значения этой изменчивости и p - значение для выбора значения этой изменчивости. p - значение, возвращенное anova2 зависит от предположений о случайных воздействиях, ε i j, в уравнении модели. Для p - значение, чтобы быть правильными, эти воздействия должны быть независимы, нормально распределены, и иметь постоянное отклонение. Стандартная таблица ANOVA имеет эту форму:
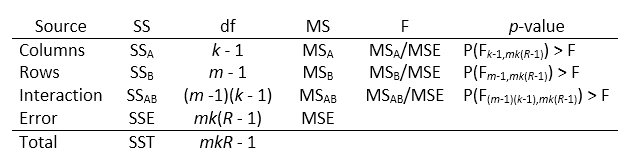
anova2 возвращает стандартную таблицу ANOVA как массив ячеек с шестью столбцами.
| Столбец | Определение |
|---|---|
Source | Источник изменчивости. |
SS | Сумма квадратов из-за каждого источника. |
df | Степени свободы сопоставлены с каждым источником. Предположим, что J является количеством групп в факторе столбца, I является количеством групп в факторе строки, и R является количеством репликаций. Затем общим количеством наблюдений является IJR, и общие степени свободы IJR – 1. I – 1 является степенями свободы для фактора строки, J – 1 является степенями свободы для фактора столбца, (I – 1) (J – 1) степени свободы взаимодействия, и IJ (R – 1) является ошибочными степенями свободы. |
MS | Средние квадратичные для каждого источника, который является отношением SS/df. |
F | F-, которая является отношением средних квадратичных. |
Prob>F | p - значение, которое является вероятностью, что F - статистическая величина может принять значение, больше, чем вычисленное статистическое тестом значение. anova2 выводит эту вероятность из cdf F - распределение. |
Строки таблицы ANOVA показывают изменчивость в данных, которые разделены на источник.
| Строка (Источник) | Определение |
|---|---|
Columns | Изменчивость из-за фактора столбца |
Rows | Изменчивость из-за фактора строки |
Interaction | Изменчивость из-за взаимодействия факторов строки и столбца |
Error | Изменчивость из-за различий между данными в каждой группе и средним значением группы (изменчивость в группах) |
Total | Общая изменчивость |
[1] Ву, C. F. J. и М. Амада. Эксперименты: планирование, анализ и оптимизация проекта параметра, 2000.
[2] Neter, J., М. Х. Катнер, К. Дж. Нахцхайм и В. Вассерман. 4-й редактор Прикладные Линейные Статистические модели. Ирвин Пресс, 1996.
anova1 | anova2 | anovan | multcompare
