readbytesСчитайте двоичные данные из файла
Блокноты MuPAD® будут демонтированы в будущем релизе. Используйте live скрипты MATLAB® вместо этого.
Live скрипты MATLAB поддерживают большую часть функциональности MuPAD, хотя существуют некоторые различия. Для получения дополнительной информации смотрите, Преобразуют Notebook MuPAD в Live скрипты MATLAB.
readbytes(filename | n, <m>, <format>, <BigEndian | LittleEndian>, <ReturnType = DOM_HFARRAY | DOM_LIST | [DOM_HFARRAY] | [DOM_HFARRAY, dim1, dim2, …]>)
readbytes позволяет вам считать произвольные файлы и интерпретировать их содержимое как последовательность чисел.
Результаты readbytes зависьте от интерпретации двоичных данных, установленных format опция. При чтении файла можно интерпретировать его как поток Byte, SignedByte, Short, SignedShortWord, SignedWord, Float или Double. Это стандартные форматы, которые используются многими пакетами программы, чтобы считать данные. Смотрите Пример 1.
Эта функция особенно полезна, когда вы работаете над данными, обеспеченными или предназначенный для внешних программ. Например, можно использовать его, чтобы реализовать алгоритмы шифрования или алгоритмы сжатия в MuPAD®. Смотрите Пример 2.
Можно задать файл непосредственно его именем. Если имя файла задано, readbytes открывает и закрывает файл автоматически. Если READPATH не имеет никакого значения, readbytes интерпретирует имя файла как путь относительно “рабочей директории”. Абсолютные пути обрабатываются readbytes, также.
Значение “рабочей директории” зависит от операционной системы. В системах Microsoft® Windows® и в системах Mac OS X, “рабочая директория” является папкой, где MuPAD установлен. В системах UNIX® это - текущая рабочая директория, в которой был запущен MuPAD.
Если имя файла задано, каждый вызов readbytes открывает файл вначале. Если файл был открыт через fopen, последующие вызовы readbytes с соответствующим дескриптором файла запускаются в точке в файле, который был достигнут последним readbytes команда. Следовательно, если вы хотите считать файл фрагментами, необходимо открыть его с fopen и используйте возвращенный дескриптор файла вместо имени файла. Смотрите Пример 3.
Если вы открываете файл при помощи fopen, обязательно передайте флаг Raw к fopen. В противном случае, readbytes выдает ошибку.
Если количество байтов в файле в readbytes вызов не является кратным модулям заданного формата, данные считаны до последнего полного номера. Остающиеся байты проигнорированы. Смотрите Пример 4.
Обязательно считайте данные соответствующим способом. Необходимо знать формат, используемый программой, которая создала файл.
Если readbytes используется с опцией ReturnType = [DOM_HFARRAY, dim1, dim2, …], возвращаемым значением является DOM_HFARRAY из соответствующего размера. Здесь dim1, dim2, … и положительные целые числа, который задает размер размерностей массива. Если файл содержит меньшие значения, или количество значений, которые будут считаны, ограничивается, не элементы чтения массива инициализируются к 0,0. В других случаях точно читаются элементы массива. Смотрите Пример 6.
Если массив типа DOM_HFARRAY с комплексными числами записан в файл, затем сначала действительные части элементов записаны, и затем комплексные части записаны в файл. Поскольку readbytes может только считать действительные значения, сначала создать действительное и затем комплексную часть, чтобы восстановить комплексный массив. Смотрите Пример 7.
Функциональный readbytes чувствительно к переменной окружения READPATH. Во-первых, файл ищется в “рабочей директории”. Если это не может быть найдено там, все пути в READPATH ищутся.
Запишите последовательность чисел в файл test.tst с настройками по умолчанию. Затем загрузите их, въезжайте задним ходом:
writebytes("test.tst", [42, 17, 1, 3, 5, 7, 127, 250]):readbytes("test.tst")![]()
Считайте вышеупомянутые данные с некоторой другой опцией: SignedByte интерпретирует все значения от 0 до 127 точно как Byte делает. Более высокие значения x, однако, интерпретированы как x - 256. Например, 250 - 256 = - 6:
readbytes("test.tst", SignedByte)![]()
Short интерпретирует два байта, чтобы быть одним номером. Поэтому восемь записанных байтов интерпретированы как четыре числа. Например, первый 2-байтовый урожай 42 28 + 17 = 10769:
readbytes("test.tst", Short)![]()
С флагом LittleEndian, порядок байтов инвертируется. Например, первые 2 байта теперь уступают 17 28 + 42 = 4394:
readbytes("test.tst", Short, LittleEndian)![]()
Word интерпретирует четыре байта, чтобы быть одним номером. Поэтому восемь записанных байтов дают два числа. Первый 4-байтовый урожай 10769 216 + 259 = 705757443:
readbytes("test.tst", Word)![]()
Double интерпретирует восемь байтов, чтобы представлять одно число с плавающей запятой. Интерпретация является зависимым машины и может отличаться для вас:
readbytes("test.tst", Double)![]()
Используйте readbytes и writebytes зашифровать файл, созданный в предыдущем примере с простым “кодированием типа Цезаря”: Любой целочисленный x (байт) заменяется x + 13 mod 256:
L := readbytes("test.tst"):
L := map(L, x -> (x + 13 mod 256)):
writebytes("test.tst", L):Зная шифрование и его ключ, можно успешно дешифровать файл:
L := readbytes("test.tst")![]()
map(L, x -> (x - 13 mod 256))
![]()
delete L:
Используйте fopen записать и считать файл во фрагментах:
n := fopen("test.tst", Write, Raw):
for i from 1 to 10 do writebytes(n, [i]) end_for:
fclose(n):Эквивалентно, можно записать все данные сразу:
n := fopen("test.tst", Write, Raw):
writebytes(n, [i $ i = 1..10]):
fclose(n):Считайте байт данных байтом:
n := fopen("test.tst", Read, Raw):
readbytes(n, 1), readbytes(n, 1), readbytes(n, 1);
fclose(n):![]()
Следующая команда читает во фрагментах 5 байтов каждого:
n := fopen("test.tst", Read, Raw):
readbytes(n, 5), readbytes(n, 5);
fclose(n):![]()
delete n, i:
Вот то, что происходит, если количество байтов в файле не совпадает с кратным модулям заданного формата. Поскольку оба SignedShort и Float состойте из четного числа байтов, запаздывающего 5-го байта, соответствующего 11 проигнорирован:
writebytes("test.tst", [42, 17, 7, 9, 11], Byte):
readbytes("test.tst", SignedShort),
readbytes("test.tst", Float)![]()
Задайте порядок байтов при помощи BigEndian и LittleEndian:
writebytes("test.tst", [129, 255, 145, 171, 191, 253], Byte):
L1 := readbytes("test.tst", Short, BigEndian)![]()
L2 := readbytes("test.tst", Short, LittleEndian)![]()
Посмотрите на данные в бинарном представлении. (См. numlib::g_adic для деталей). Эффект использования LittleEndian вместо BigEndian должен обмениваться первыми 8 битами и последними 8 битами каждого номера:
map(L1, numlib::g_adic, 2)
![]()
map(L2, numlib::g_adic, 2)
![]()
delete L1, L2:
Считайте данные из файла и создайте DOM_HFARRAY с данными с помощью опции ReturnType:
writebytes("test.tst",
[ 0.2703, 12.8317, -33.1531, 9999.9948, 0.2662, -14.3421,
1000.1801, 0.4521, -34.6787, -67.3549, 0.6818, 13], Double):
readbytes("test.tst", ReturnType=[DOM_HFARRAY,2,6]);
readbytes("test.tst", ReturnType=[DOM_HFARRAY,2,3,2]);
hfarray(1..2, 1..3, 1..2, [0.2703, 12.8317, -33.1531, 9999.9948, 0.2662, -\ 14.3421, 1000.1801, 0.4521, -34.6787, -67.3549, 0.6818, 13.0])
При попытке считать больше элементов, точно элементы массива читаются.
readbytes("test.tst", ReturnType=[DOM_HFARRAY,2,4]);
readbytes("test.tst", 12, ReturnType=[DOM_HFARRAY,2,3]);

Если вы читаете только часть массива, другие элементы инициализируются с 0,0.
readbytes("test.tst", ReturnType=[DOM_HFARRAY,2,7]);
readbytes("test.tst", 4, ReturnType=[DOM_HFARRAY,2,6]);
![]()
При попытке считать все данные из файла с помощью опции ReturnType без размерности для DOM_HFARRAY одномерный массив правильного размера создается.
readbytes("test.tst", ReturnType=DOM_HFARRAY)![]()
Запишите DOM_HFARRAY с комплексными числами к файлу и попытке восстановить его путем чтения данных.
A := hfarray(1..2, 1..3,
[[2342.133 + 56*I, -342.56, PI + I],
[ -3*E, I^2 + I, 13]]);
writebytes("test.tst", A);
fd := fopen("test.tst", Read, Raw):
B := readbytes(fd, ReturnType = [DOM_HFARRAY, 2, 3]);
C := readbytes(fd, ReturnType = [DOM_HFARRAY, 2, 3]);
bool(A = B + C*I);
flose(fd):
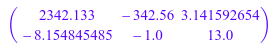
![]()
![]()
delete A, B, C, fd:
|
Имя файла: символьная строка |
|
Дескриптор файла обеспечивается |
|
Количество значений, которые будут считаны или записаны: положительное целое число. |
|
Формат двоичных данных, заданных как |
|
Формат двоичных данных. Форматом по умолчанию является Байт является 8-битным двоичным числом. Поэтому байт может иметь 28 различных значений. Для С С
“Коротким” является 16-битное двоичное число (2 байта). Поэтому “короткое” может иметь 216 различных значений. Для Семантика “Слово” является 32-битным двоичным числом (4 байта). Поэтому “слово” может иметь 232 различных значения. Для Семантика “Плавание” является 32-битным представлением вещественного числа (4 байта). “Двойным” является 64-битное представление вещественного числа (8 байтов). ПримечаниеЗначения с двойной точностью и с плавающей точкой читаются/пишутся в формате машины/операционной системы, на которой в настоящее время работает MuPAD. Поэтому результаты могут отличаться между другими платформами. Двоичные файлы, содержащие числа с плавающей запятой, являются, в целом, не портативными на другие платформы. Смотрите флаги Смотрите Пример 1 для обзора по опциям другого формата. |
|
Порядок байтов: любой
Для всех форматов данные написаны в 8-битных блоках (байты). Это также включает форматы, где модуль более длинен, чем один байт (все форматы, но Если, например,
Смотрите Пример 5 для эффектов |
|
Опция, заданная как Если установлено в Если установлено в Если установлено в [ |
Список цифр MuPAD (или целые числа или числа с плавающей запятой) или массив оборудования значения с плавающей точкой типа DOM_HFARRAY. Его тип зависит от установки опции ReturnType.
FILEPATH | READPATH | WRITEPATH | fclose | finput | fname | fopen | fprint | fread | ftextinput | import::readbitmap | import::readdata | pathname | print | protocol | read | write | writebytes